 Ulaz
UlazIspravljena formula standardne devijacije. Tumačenje vrijednosti standardne devijacije. Prosječni indeksi, njihova definicija
Prosjek standardna devijacija
Većina savršena karakteristika varijacija je srednja kvadratna devijacija, koja se naziva standard (ili standardna devijacija). Standardna devijacija() jednak je kvadratnom korijenu prosječne kvadratne devijacije pojedinačnih vrijednosti atributa od aritmetičke sredine:
Standardna devijacija je jednostavna:


Ponderirana standardna devijacija se primjenjuje na grupisane podatke:

Sljedeći omjer se odvija između srednjeg kvadrata i srednjeg linearnog odstupanja u uslovima normalne distribucije: ~ 1,25.
Standardna devijacija, kao glavna apsolutna mjera varijacije, koristi se za određivanje ordinatnih vrijednosti krivulje normalne distribucije, u proračunima koji se odnose na organizaciju posmatranja uzorka i utvrđivanje tačnosti karakteristika uzorka, kao i pri ocjenjivanju granice varijacije karakteristike u homogenoj populaciji.
18. Varijanca, njeni tipovi, standardna devijacija.
Varijanca slučajne varijable- mjera širenja date slučajne varijable, odnosno njenog odstupanja od matematičkog očekivanja. U statistici se često koristi notacija ili. Kvadratni korijen varijanse se obično naziva standardna devijacija, standardna devijacija ili standardni namaz.
Ukupna varijansa (σ 2) mjeri varijaciju osobine u cjelini pod uticajem svih faktora koji su uzrokovali ovu varijaciju. Istovremeno, zahvaljujući metodi grupisanja, moguće je identifikovati i izmeriti varijaciju zbog karakteristike grupisanja i varijaciju koja nastaje pod uticajem neuračunatih faktora.
Međugrupna varijansa (σ 2 m.gr) karakterizira sistematsko variranje, odnosno razlike u vrijednosti proučavane osobine koje nastaju pod uticajem osobine - faktora koji čini osnovu grupe.
Standardna devijacija(sinonimi: standardna devijacija, standardna devijacija, kvadratna devijacija; povezani pojmovi: standardna devijacija, standardni namaz) - u teoriji vjerojatnosti i statistici, najčešći pokazatelj disperzije vrijednosti slučajne varijable u odnosu na njeno matematičko očekivanje. Sa ograničenim nizovima uzoraka vrijednosti, umjesto matematičkog očekivanja, koristi se aritmetička sredina skupa uzoraka.
Standardna devijacija se mjeri u mjernim jedinicama same slučajne varijable i koristi se pri izračunavanju standardne greške aritmetičke sredine, pri konstruiranju intervala povjerenja, pri statističkom testiranju hipoteza, pri mjerenju linearnog odnosa između slučajnih varijabli. Definisano kao Kvadratni korijen iz varijanse slučajne varijable.
Standardna devijacija:

Standardna devijacija (procjena standardne devijacije slučajne varijable x u odnosu na njegovo matematičko očekivanje zasnovano na nepristrasnoj procjeni njegove varijanse):

gdje je disperzija; - i th element selekcije; - veličina uzorka; - aritmetička sredina uzorka:
![]()
Treba napomenuti da su obje procjene pristrasne. U opštem slučaju, nemoguće je konstruisati nepristrasnu procenu. U ovom slučaju, procjena zasnovana na nepristrasnoj procjeni varijanse je konzistentna.
19. Suština, obim i postupak za određivanje modusa i medijana.
Pored prosječnih vrijednosti u statistici za relativne karakteristike vrijednosti promjenjive karakteristike i unutrašnja struktura distribucijske serije koriste strukturna sredstva, koja su uglavnom predstavljena moda i medijana.
Moda- Ovo je najčešća varijanta serije. Moda se koristi, na primjer, pri određivanju veličine odjeće i obuće za kojima je najveća potražnja među kupcima. Režim za diskretnu seriju je varijanta sa najvećom frekvencijom. Prilikom izračunavanja moda za niz intervalnih varijacija, izuzetno je važno prvo odrediti modalni interval (po maksimalnoj frekvenciji), a zatim - vrijednost modalne vrijednosti atributa koristeći formulu:

§ - značenje mode
§ - donja granica modalnog intervala
§ - vrijednost intervala
§ - frekvencija modalnog intervala
§ - frekvencija intervala koji prethodi modalnom
§ - frekvencija intervala nakon modalnog
medijana - ova vrijednost atributa, ĸᴏᴛᴏᴩᴏᴇ, leži u osnovi rangirane serije i dijeli ovu seriju na dva dijela jednaka po broju.
Za određivanje medijane u diskretnoj seriji ako su frekvencije dostupne, prvo izračunajte polovični zbir frekvencija, a zatim odredite koja vrijednost varijante pada na njega. (Ako sortirana serija sadrži neparan broj karakteristike, tada se srednji broj izračunava pomoću formule:
M e = (n (ukupan broj karakteristika) + 1)/2,
u slučaju parnog broja karakteristika, medijana će biti jednaka proseku dve karakteristike u sredini reda).
Prilikom izračunavanja medijane za intervalne varijacione serije Prvo odredite srednji interval unutar kojeg se medijana nalazi, a zatim odredite vrijednost medijane koristeći formulu:

§ - tražena medijana
§ - donja granica intervala koji sadrži medijanu
§ - vrijednost intervala
§ - zbir frekvencija ili broj članova serije
§ - zbir akumuliranih frekvencija intervala koji prethode medijani
§ - frekvencija srednjeg intervala
Primjer. Pronađite mod i medijan.
Rješenje: U ovom primjeru, modalni interval je unutar starosne grupe od 25-30 godina, jer ovaj interval ima najveću učestalost (1054).
Izračunajmo veličinu moda:
To znači da je modalna starost studenata 27 godina.
Izračunajmo medijanu. Medijan interval je u starosnoj grupi od 25-30 godina, jer u okviru ovog intervala postoji opcija͵ koja dijeli populaciju na dva jednaka dijela (Σf i /2 = 3462/2 = 1731). Zatim u formulu zamjenjujemo potrebne numeričke podatke i dobivamo srednju vrijednost:

To znači da je polovina učenika mlađa od 27,4 godine, a druga polovina starija od 27,4 godine.
Pored moda i medijana, koriste se indikatori kao što su kvartili, koji dijele rangiranu seriju na 4 jednaka dijela, decili - 10 dijelova i percentili - na 100 dijelova.
20. Koncept posmatranja uzorka i njegov obim.
Selektivno posmatranje primjenjuje se kada se koristi kontinuirani nadzor fizički nemoguće zbog velike količine podataka ili nije ekonomski izvodljivo. Fizička nemogućnost se javlja, na primjer, kada se proučavaju putnički tokovi, tržišne cijene i porodični budžeti. Ekonomska nesvrsishodnost javlja se pri ocjenjivanju kvalitete robe povezane s njihovim uništenjem, na primjer, degustacija, ispitivanje čvrstoće cigle itd.
Statističke jedinice odabrane za posmatranje su uzorak populacije ili uzorak, i cijeli njihov niz - opšta populacija(GS). Gde broj jedinica u uzorku označiti n, a u cijelom GS - N. Stav n/N obično se zove relativna veličina ili uzorak udjela.
Kvalitet rezultata posmatranja uzorka zavisi od reprezentativnost uzorka, odnosno koliko je reprezentativan u GS. Da bi se osigurala reprezentativnost uzorka, izuzetno je važno pridržavati se princip slučajnog odabira jedinica, koji pretpostavlja da na uključivanje HS jedinice u uzorak ne može uticati bilo koji drugi faktor osim slučajnosti.
Postoji 4 načina nasumične selekcije uzorkovati:
- Zapravo nasumično odabir ili ʼʼlotto metodʼʼ, kada se dodjeljuju statističke vrijednosti serijski brojevi, postavljeni na određene predmete (na primjer, bačve), koji se zatim miješaju u kontejneru (na primjer, u vrećici) i biraju nasumično. U praksi se ova metoda provodi pomoću generatora slučajnih brojeva ili matematičkih tablica slučajnih brojeva.
- Mehanički izbor prema kojem svaki ( N/n)-ta količina stanovništva. Na primjer, ako sadrži 100.000 vrijednosti, a vi trebate odabrati 1.000, tada će svaka 100.000 / 1000 = 100. vrijednost biti uključena u uzorak. Štaviše, ako nisu rangirani, onda se prvi bira nasumično od prvih sto, a brojevi ostalih će biti sto veći. Na primjer, ako je prva jedinica bila br. 19, onda bi sljedeća trebala biti br. 119, zatim br. 219, pa br. 319, itd. Ako su jedinice stanovništva rangirane, tada se prvo bira broj 50, zatim broj 150, zatim broj 250 i tako dalje.
- Vrši se odabir vrijednosti iz heterogenog niza podataka slojevito(stratificirana) metoda, kada se populacija prvo podijeli na homogene grupe na koje se primjenjuje slučajni ili mehanički odabir.
- Poseban način uzorkovanje je serijski selekcija, u kojoj se nasumično ili mehanički biraju ne pojedinačne vrijednosti, već njihove serije (sekvence od nekog broja do nekog broja u nizu), unutar kojih se vrši kontinuirano posmatranje.
Kvalitet opservacija uzorka također zavisi od tip uzorka: ponovljeno ili neponovljiv. At ponovna selekcija Statističke vrijednosti ili njihove serije uključene u uzorak se nakon upotrebe vraćaju u opću populaciju, imajući priliku da budu uključene u novi uzorak. Štaviše, sve vrijednosti u općoj populaciji imaju istu vjerovatnoću uključivanja u uzorak. Neponovljiv izbor znači da se statističke vrijednosti ili njihove serije uključene u uzorak ne vraćaju u opću populaciju nakon upotrebe, pa se za preostale vrijednosti potonje povećava vjerovatnoća da će biti uključene u sljedeći uzorak.
Uzorkovanje koje se ne ponavlja daje preciznije rezultate i stoga se češće koristi. Ali postoje situacije kada se ne može primijeniti (proučavanje putničkih tokova, potražnje potrošača itd.) i tada se vrši ponovljena selekcija.
21. Maksimalna greška uzorkovanja posmatranja, prosječna greška uzorkovanja, postupak njihovog izračunavanja.
Razmotrimo detaljno gore navedene metode za formiranje populacije uzorka i greške reprezentativnosti koje se javljaju. Pravilno nasumično uzorkovanje se zasniva na nasumičnom odabiru jedinica iz populacije bez ikakvih sistematskih elemenata. Tehnički, stvarni slučajni odabir se vrši izvlačenjem ždrijeba (na primjer, lutrija) ili korištenjem tablice slučajnih brojeva.
Pravilna nasumična selekcija “u svom čistom obliku” se rijetko koristi u praksi selektivnog posmatranja, ali je ona inicijalna među ostalim tipovima selekcije i implementira osnovne principe selektivnog posmatranja. Razmotrimo neka teorijska pitanja metoda uzorkovanja i formule greške za jednostavno nasumično uzorkovanje.
Pristrasnost uzorkovanja- ϶ᴛᴏ razlika između vrijednosti parametra u općoj populaciji i njegove vrijednosti izračunate iz rezultata promatranja uzorka. Važno je napomenuti da je za prosječnu kvantitativnu karakteristiku greška uzorkovanja određena
Indikator se obično naziva maksimalnom greškom uzorkovanja. Srednja vrijednost uzorka je slučajna varijabla koja može uzeti različita značenja na osnovu toga koje su jedinice uključene u uzorak. Stoga su greške uzorkovanja također slučajne varijable i mogu poprimiti različite vrijednosti. Iz tog razloga odredite prosjek od moguće greške – prosječna greška uzorkovanja, što zavisi od:
· veličina uzorka: što je veći broj, to je manja prosječna greška;
· stepen promjene karakteristike koja se proučava: što je manja varijacija karakteristike, a samim tim i disperzija, manja je prosječna greška uzorkovanja.
At nasumični ponovni odabir izračunava se prosječna greška. U praksi, opšta varijansa nije tačno poznata, ali u teoriji verovatnoće je to dokazano ![]() . Budući da je vrijednost za dovoljno veliko n blizu 1, možemo pretpostaviti da je . Zatim treba izračunati prosječnu grešku uzorkovanja: . Ali u slučajevima malog uzorka (sa n<30) коэффициент крайне важно учитывать, и среднюю ошибку малой выборки рассчитывать по формуле
. Budući da je vrijednost za dovoljno veliko n blizu 1, možemo pretpostaviti da je . Zatim treba izračunati prosječnu grešku uzorkovanja: . Ali u slučajevima malog uzorka (sa n<30) коэффициент крайне важно учитывать, и среднюю ошибку малой выборки рассчитывать по формуле  .
.
At nasumično neponavljajuće uzorkovanje date formule su prilagođene vrijednosti . Tada je prosječna greška uzorkovanja koja se ne ponavlja:  I
I  . Jer je uvijek manji od , tada je množitelj () uvijek manji od 1. To znači da je prosječna greška kod ponovljenog odabira uvijek manja nego kod ponovljenog odabira. Mehaničko uzorkovanje koristi se kada je opća populacija na neki način uređena (na primjer, spiskovi birača po abecednom redu, brojevi telefona, brojevi kuća i stanova). Odabir jedinica se vrši u određenom intervalu, koji je jednak inverznoj vrijednosti procenta uzorkovanja. Dakle, kod uzorka od 2% bira se svakih 50 jedinica = 1/0,02, a kod uzorka od 5% svakih 1/0,05 = 20 jedinica opšte populacije.
. Jer je uvijek manji od , tada je množitelj () uvijek manji od 1. To znači da je prosječna greška kod ponovljenog odabira uvijek manja nego kod ponovljenog odabira. Mehaničko uzorkovanje koristi se kada je opća populacija na neki način uređena (na primjer, spiskovi birača po abecednom redu, brojevi telefona, brojevi kuća i stanova). Odabir jedinica se vrši u određenom intervalu, koji je jednak inverznoj vrijednosti procenta uzorkovanja. Dakle, kod uzorka od 2% bira se svakih 50 jedinica = 1/0,02, a kod uzorka od 5% svakih 1/0,05 = 20 jedinica opšte populacije.
Referentna tačka se bira na različite načine: nasumično, od sredine intervala, sa promjenom referentne točke. Glavna stvar je izbjeći sistematske greške. Na primjer, kod uzorka od 5%, ako je prva jedinica 13., onda su sljedeće 33, 53, 73 itd.
U smislu tačnosti, mehanički odabir je blizak stvarnom slučajnom uzorkovanju. Iz tog razloga, za određivanje prosječne greške mehaničkog uzorkovanja, koriste se odgovarajuće formule slučajnog odabira.
At tipičan izbor populacija koja se anketira preliminarno je podijeljena u homogene, slične grupe. Na primjer, kada se anketiraju preduzeća, to su industrije, podsektori, kada se proučava stanovništvo, to su regije, društvene ili starosne grupe. Zatim se vrši nezavisna selekcija iz svake grupe mehanički ili čisto nasumično.
Tipično uzorkovanje daje preciznije rezultate od drugih metoda. Tipizacija opće populacije osigurava da je svaka tipološka grupa zastupljena u uzorku, što omogućava eliminaciju utjecaja međugrupne varijanse na prosječnu grešku uzorkovanja. Stoga je pri pronalaženju greške tipičnog uzorka prema pravilu sabiranja varijansi () izuzetno važno uzeti u obzir samo prosjek grupnih varijansi. Zatim prosječna greška uzorkovanja: s ponovljenim uzorkovanjem, sa uzorkovanjem koji se ne ponavlja  , Gdje
, Gdje  – prosjek varijansi unutar grupe u uzorku.
– prosjek varijansi unutar grupe u uzorku.
Serijski (ili gnijezdo) odabir koristi se kada je populacija podijeljena u serije ili grupe prije početka istraživanja uzorka. Ove serije uključuju pakovanje gotovih proizvoda, studentske grupe i brigade. Serije za ispitivanje se biraju mehanički ili čisto nasumično, au okviru serije vrši se kontinuirano ispitivanje jedinica. Iz tog razloga, prosječna greška uzorkovanja ovisi samo o međugrupnoj (između serija) varijansi, koja se izračunava pomoću formule:  gdje je r broj odabranih serija; – prosjek i-te serije. Izračunava se prosječna greška serijskog uzorkovanja: sa ponovljenim uzorkovanjem, sa uzorkovanjem koji se ne ponavlja
gdje je r broj odabranih serija; – prosjek i-te serije. Izračunava se prosječna greška serijskog uzorkovanja: sa ponovljenim uzorkovanjem, sa uzorkovanjem koji se ne ponavlja  , gdje je R ukupan broj serija. Kombinovano selekcija je kombinacija razmatranih metoda selekcije.
, gdje je R ukupan broj serija. Kombinovano selekcija je kombinacija razmatranih metoda selekcije.
Prosječna greška uzorkovanja za bilo koju metodu uzorkovanja uglavnom zavisi od apsolutne veličine uzorka i, u manjoj mjeri, od procenta uzorka. Pretpostavimo da je u prvom slučaju napravljeno 225 opservacija iz populacije od 4.500 jedinica, au drugom iz populacije od 225.000 jedinica. Varijance u oba slučaja su jednake 25. Tada će u prvom slučaju, uz odabir od 5%, greška uzorkovanja biti:  U drugom slučaju, sa 0,1% odabira, to će biti jednako:
U drugom slučaju, sa 0,1% odabira, to će biti jednako:
 Međutim, kada je postotak uzorkovanja smanjen za 50 puta, greška uzorkovanja se neznatno povećala, jer se veličina uzorka nije mijenjala. Pretpostavimo da je veličina uzorka povećana na 625 opservacija. U ovom slučaju greška uzorkovanja je:
Međutim, kada je postotak uzorkovanja smanjen za 50 puta, greška uzorkovanja se neznatno povećala, jer se veličina uzorka nije mijenjala. Pretpostavimo da je veličina uzorka povećana na 625 opservacija. U ovom slučaju greška uzorkovanja je:  Povećanje uzorka za 2,8 puta sa istom veličinom populacije smanjuje veličinu greške uzorkovanja za više od 1,6 puta.
Povećanje uzorka za 2,8 puta sa istom veličinom populacije smanjuje veličinu greške uzorkovanja za više od 1,6 puta.
22.Metode i metode za formiranje uzorka populacije.
U statistici se koriste različite metode formiranja populacija uzoraka, što je određeno ciljevima istraživanja i zavisi od specifičnosti predmeta proučavanja.
Osnovni uslov za sprovođenje uzorka je da se spreči pojava sistematskih grešaka koje proizilaze iz kršenja principa jednakih mogućnosti da svaka jedinica opšte populacije bude uključena u uzorak. Prevencija sistematskih grešaka postiže se korišćenjem naučno zasnovanih metoda za formiranje uzorka.
Postoje sljedeće metode za odabir jedinica iz opšte populacije: 1) individualna selekcija - pojedinačne jedinice se biraju za uzorak; 2) grupni odabir - uzorak obuhvata kvalitativno homogene grupe ili serije jedinica koje se proučavaju; 3) kombinovana selekcija je kombinacija individualne i grupne selekcije. Metode selekcije određene su pravilima za formiranje uzorka populacije.
Uzorak bi trebao biti:
- zapravo nasumično sastoji se u tome da se uzorkovana populacija formira kao rezultat slučajnog (nenamjernog) odabira pojedinačnih jedinica iz opće populacije. U ovom slučaju, broj jedinica odabranih u populaciji uzorka obično se određuje na osnovu prihvaćenog udjela uzorka. Proporcija uzorka je omjer broja jedinica u populaciji uzorka n prema broju jedinica u općoj populaciji N, ᴛ.ᴇ.
- mehanički sastoji se u tome da se izbor jedinica u populaciji uzorka vrši iz opće populacije, podijeljene u jednake intervale (grupe). U ovom slučaju, veličina intervala u populaciji jednaka je recipročnom udjelu uzorka. Dakle, kod uzorka od 2% bira se svaka 50. jedinica (1:0.02), kod uzorka od 5% svaka 20. jedinica (1:0.05) itd. Međutim, u skladu sa prihvaćenom proporcijom selekcije, opšta populacija je takoreći mehanički podijeljena u jednake grupe. Iz svake grupe se bira samo jedna jedinica za uzorak.
- tipično - u kojoj se opća populacija najprije dijeli na homogene tipične grupe. Zatim, iz svake tipične grupe, čisto slučajni ili mehanički uzorak se koristi za individualni odabir jedinica u populaciji uzorka. Važna karakteristika tipičnog uzorka je da daje tačnije rezultate u poređenju sa drugim metodama odabira jedinica u populaciji uzorka;
- serijski- u kojem je opća populacija podijeljena na grupe jednake veličine - serije. Serije se biraju u populaciju uzorka. U okviru serije vrši se kontinuirano posmatranje jedinica uključenih u seriju;
- kombinovano- uzorkovanje treba da bude dvostepeno. U ovom slučaju, stanovništvo se prvo dijeli na grupe. Zatim se biraju grupe, au okviru ovih se biraju pojedinačne jedinice.
U statistici se razlikuju sljedeće metode za odabir jedinica u populaciji uzorka:
- single stage uzorkovanje - svaka odabrana jedinica se odmah podvrgava proučavanju prema datom kriterijumu (pravilno nasumično i serijsko uzorkovanje);
- višestepeni uzorkovanje - vrši se selekcija iz opšte populacije pojedinačnih grupa, a pojedinačne jedinice se biraju iz grupa (tipično uzorkovanje sa mehaničkom metodom odabira jedinica u populaciju uzorka).
Osim toga, postoje:
- ponovna selekcija- prema šemi vraćene lopte. U ovom slučaju, svaka jedinica ili serija uključena u uzorak se vraća u opštu populaciju i stoga ima šansu da ponovo bude uključena u uzorak;
- ponovite odabir- prema šemi nevraćene lopte. Ima preciznije rezultate sa istom veličinom uzorka.
23. Određivanje izuzetno važne veličine uzorka (koristeći Studentovu t-tabelu).
Jedan od naučnih principa u teoriji uzorkovanja je osigurati da se odabere dovoljan broj jedinica. Teoretski, izuzetna važnost poštivanja ovog principa prikazana je u dokazima graničnih teorema u teoriji vjerovatnoće, koji omogućavaju da se utvrdi koji volumen jedinica treba izabrati iz populacije da bude dovoljan i osigura reprezentativnost uzorka.
Smanjenje standardne greške uzorkovanja, a samim tim i povećanje tačnosti procjene, uvijek je povezano s povećanjem veličine uzorka, stoga je već u fazi organiziranja promatranja uzorka potrebno odlučiti koja je veličina populacije uzorka treba da bude kako bi se osigurala potrebna tačnost rezultata posmatranja. Proračun izuzetno važnog volumena uzorka konstruiran je korištenjem formula izvedenih iz formula za maksimalne greške uzorkovanja (A), koje odgovaraju određenom tipu i načinu odabira. Dakle, za slučajni ponovljeni uzorak (n) imamo:

Suština ove formule je da je kod nasumičnih ponovljenih uzorkovanja izuzetno važnih brojeva veličina uzorka direktno proporcionalna kvadratu koeficijenta pouzdanosti (t2) i varijansu varijacione karakteristike (?2) i obrnuto je proporcionalna kvadratu maksimalne greške uzorkovanja (?2). Konkretno, sa povećanjem maksimalne greške za faktor dva, potrebna veličina uzorka treba biti smanjena za faktor četiri. Od tri parametra, dva (t i?) postavlja istraživač. Istovremeno, istraživač na osnovu cilja
a problemi uzorka istraživanja moraju riješiti pitanje: u koju kvantitativnu kombinaciju je bolje uključiti ove parametre kako bi se osigurala optimalna opcija? U jednom slučaju može biti više zadovoljan pouzdanošću dobijenih rezultata (t) nego mjerom tačnosti (?), u drugom - obrnuto. Teže je riješiti pitanje vrijednosti maksimalne greške uzorkovanja, budući da istraživač nema ovaj indikator u fazi dizajniranja promatranja uzorka, pa je u praksi uobičajeno postaviti vrijednost maksimalne greške uzorkovanja. , obično unutar 10% od očekivanog prosječnog nivoa atributa . Ustanovljavanju procijenjenog prosjeka može se pristupiti na različite načine: korištenjem podataka iz sličnih prethodnih istraživanja ili korištenjem podataka iz okvira uzorkovanja i provođenjem malog pilot uzorka.
Najteže je utvrditi prilikom dizajniranja opservacije uzorka treći parametar u formuli (5.2) – varijansa populacije uzorka. U ovom slučaju izuzetno je važno koristiti sve informacije dostupne istraživaču, dobijene u prethodnim sličnim i pilot anketama.
Pitanje određivanja izuzetno važne veličine uzorka postaje komplikovanije ako istraživanje uzorka uključuje proučavanje nekoliko karakteristika jedinica uzorka. U ovom slučaju, prosječni nivoi svake od karakteristika i njihova varijacija su, po pravilu, različiti, pa je u tom pogledu odlučivanje kojoj varijaciji kojoj od karakteristika dati prednost moguće je samo uzimajući u obzir svrhu i ciljeve ankete.
Prilikom dizajniranja opservacije uzorka, pretpostavlja se unaprijed određena vrijednost dozvoljene greške uzorkovanja u skladu sa ciljevima određene studije i vjerovatnoćom zaključaka na osnovu rezultata posmatranja.
Općenito, formula za maksimalnu grešku prosjeka uzorka nam omogućava da odredimo:
‣‣‣ veličina mogućih odstupanja indikatora opšte populacije od pokazatelja populacije uzorka;
‣‣‣ potrebnu veličinu uzorka kako bi se osigurala potrebna tačnost, pri kojoj granice moguće greške ne prelaze određenu specificiranu vrijednost;
‣‣‣ vjerovatnoća da će greška u uzorku imati određeno ograničenje.
Distribucija studenata u teoriji vjerovatnoće, to je jednoparametarska porodica apsolutno kontinuiranih distribucija.
24. Dinamički niz (interval, trenutak), završni dinamički niz.
Serija Dynamics- to su vrijednosti statističkih pokazatelja koji se prikazuju određenim hronološkim redoslijedom.
Svaka vremenska serija sadrži dvije komponente:
1) indikatori vremenskih perioda(godine, kvartali, mjeseci, dani ili datumi);
2) indikatori koji karakterišu objekt koji se proučava za vremenske periode ili na odgovarajuće datume, koji se nazivaju nivoi serije.
Nivoi serije su izraženi u apsolutnim i prosječnim ili relativnim vrijednostima. Uzimajući u obzir ovisnost o prirodi pokazatelja, grade se dinamičke serije apsolutnih, relativnih i prosječnih vrijednosti. Dinamičke serije relativnih i prosječnih vrijednosti konstruiraju se na osnovu izvedenih serija apsolutnih vrijednosti. Postoje intervalne i momentne serije dinamike.
Dinamičke intervalne serije sadrži vrijednosti indikatora za određene vremenske periode. U intervalnoj seriji, nivoi se mogu sumirati kako bi se dobio volumen fenomena u dužem periodu, ili takozvani akumulirani ukupni iznosi.
Serija dinamičkih trenutaka odražava vrijednosti indikatora u određenom trenutku (datum u vremenu). U serijama trenutaka, istraživača može zanimati samo razlika u pojavama koja odražava promjenu nivoa serije između određenih datuma, budući da ovdje zbir nivoa nema pravi sadržaj. Ovdje se ne izračunavaju kumulativni zbroji.
Najvažniji uslov za ispravnu konstrukciju vremenskih serija je uporedivost nivoa serije koji pripadaju različitim periodima. Nivoi moraju biti predstavljeni u homogenim količinama i mora postojati jednaka potpunost obuhvata različitih delova fenomena.
Kako bi se izbjeglo izobličenje realne dinamike, u statističkim istraživanjima vrše se preliminarni proračuni (zatvaranje dinamike serije), koji prethode statističkoj analizi vremenske serije. Ispod zatvaranje serije dinamike Općenito je prihvaćeno razumijevanje kombinacije u jednu seriju od dvije ili više serija, čiji se nivoi izračunavaju različitom metodologijom ili ne odgovaraju teritorijalnim granicama itd. Zatvaranje dinamičkog niza takođe može podrazumevati dovođenje apsolutnih nivoa dinamičkog niza na zajedničku osnovu, čime se neutrališe neuporedivost nivoa dinamičkih serija.
25. Koncept uporedivosti dinamičkih serija, koeficijenata, stopa rasta i rasta.
Serija Dynamics- ovo su niz statističkih pokazatelja koji karakterišu razvoj prirodnih i društvenih pojava tokom vremena. Statističke zbirke koje izdaje Državni komitet za statistiku Rusije sadrže veliki broj dinamičkih serija u tabelarnom obliku. Dinamičke serije omogućavaju identifikaciju obrazaca razvoja fenomena koji se proučavaju.
Serija Dynamics sadrži dvije vrste indikatora. Indikatori vremena(godine, kvartali, mjeseci, itd.) ili tačke u vremenu (na početku godine, na početku svakog mjeseca, itd.). Indikatori nivoa reda. Pokazatelji nivoa dinamike serije mogu se izraziti u apsolutnim vrijednostima (proizvodnja proizvoda u tonama ili rubljama), relativnim vrijednostima (udio gradskog stanovništva u %) i prosječnim vrijednostima (prosječna plata radnika u industriji po godinama , itd.). U tabelarnom obliku, vremenska serija sadrži dvije kolone ili dva reda.
Ispravna konstrukcija vremenskih serija zahtijeva ispunjenje niza zahtjeva:
- svi pokazatelji niza dinamike moraju biti naučno potkrijepljeni i pouzdani;
- indikatori niza dinamike moraju biti uporedivi tokom vremena, ᴛ.ᴇ. moraju biti izračunati za iste vremenske periode ili na iste datume;
- indikatori niza dinamike moraju biti uporedivi na cijeloj teritoriji;
- indikatori niza dinamike moraju biti uporedivi po sadržaju, ᴛ.ᴇ. obračunava se prema jedinstvenoj metodologiji, na isti način;
- indikatori određenog broja dinamika trebali bi biti uporedivi za čitav niz farmi koje se uzimaju u obzir. Svi pokazatelji serije dinamike moraju biti dati u istim mjernim jedinicama.
Statistički pokazatelji mogu karakterizirati ili rezultate procesa koji se proučava u određenom vremenskom periodu, ili stanje fenomena koji se proučava u određenom trenutku, ᴛ.ᴇ. indikatori mogu biti intervalni (periodični) i trenutni. Prema tome, u početku su dinamičke serije ili intervalne ili momentalne. Serija dinamike momenta, zauzvrat, dolazi sa jednakim i nejednakim vremenskim intervalima.
Izvorni niz dinamike može se transformirati u niz prosječnih vrijednosti i niz relativnih vrijednosti (lančane i osnovne). Takve vremenske serije se nazivaju izvedene vremenske serije.
Metodologija za izračunavanje prosječnog nivoa u dinamičkoj seriji je različita, ovisno o vrsti dinamičke serije. Koristeći primjere, razmotrit ćemo vrste dinamičkih serija i formule za izračunavanje prosječnog nivoa.
Apsolutna povećanja (Δy) pokazuje koliko se jedinica promijenio sljedeći nivo serije u odnosu na prethodni (gr. 3. - lanac apsolutnih povećanja) ili u odnosu na početni nivo (gr. 4. - osnovni apsolutni porast). Formule proračuna se mogu napisati na sljedeći način:

Kada se apsolutne vrijednosti serije smanje, doći će do „smanjivanja“ odnosno „smanjenja“.
Apsolutni pokazatelji rasta ukazuju da je, na primjer, 1998. god. proizvodnja proizvoda "A" porasla je u odnosu na 1997. godinu. za 4 hiljade tona, au odnosu na 1994. godinu ᴦ. - za 34 hiljade tona; za ostale godine vidi tabelu. 11,5 gr.
Objavljeno na ref.rf
3 i 4.
Stopa rasta pokazuje koliko se puta nivo serije promenio u odnosu na prethodni (gr. 5 - lančani koeficijenti rasta ili opadanja) ili u odnosu na početni nivo (gr. 6 - osnovni koeficijenti rasta ili pada). Formule proračuna se mogu napisati na sljedeći način:

Stope rasta pokazati u kom procentu je sledeći nivo serije u odnosu na prethodni (kolona 7 - lančane stope rasta) ili u odnosu na početni nivo (gr. 8 - osnovne stope rasta). Formule proračuna se mogu napisati na sljedeći način:

Tako je, na primjer, 1997. obim proizvodnje proizvoda "A" u odnosu na 1996. ᴦ. iznosio 105,5% (
Stopa rasta pokazuju za koji procenat je povećan nivo izvještajnog perioda u odnosu na prethodni (kolona 9 - lančane stope rasta) ili u odnosu na početni nivo (kolona 10 - osnovne stope rasta). Formule proračuna se mogu napisati na sljedeći način:
T pr = T r - 100% ili T pr = apsolutni rast / nivo prethodnog perioda * 100%
Tako je, na primjer, 1996. u poređenju sa 1995. ᴦ. Proizvod "A" proizveden je više za 3,8% (103,8% - 100%) ili (8:210) x 100% u odnosu na 1994. godinu ᴦ. - za 9% (109% - 100%).
Ako se apsolutni nivoi u nizu smanje, tada će stopa biti manja od 100% i, shodno tome, postojaće stopa smanjenja (stopa povećanja sa predznakom minus).
Apsolutna vrijednost od 1% povećanja(gr.
Objavljeno na ref.rf
11) pokazuje koliko jedinica je potrebno proizvesti u datom periodu da se nivo prethodnog perioda poveća za 1%. U našem primjeru, 1995. ᴦ. bilo je potrebno proizvesti 2,0 hiljade tona, a 1998. ᴦ. - 2,3 hiljade tona, ᴛ.ᴇ. mnogo veći.
Apsolutna vrijednost rasta od 1% može se odrediti na dva načina:
§ nivo prethodnog perioda podijeljen sa 100;
§ apsolutna povećanja lanca su podijeljena sa odgovarajućim stopama rasta lanca.
Apsolutna vrijednost povećanja od 1% = 
U dinamici, posebno u dužem periodu, važna je zajednička analiza stope rasta sa sadržajem svakog procenta povećanja ili smanjenja.
Imajte na umu da je razmatrana metodologija za analizu vremenskih serija primjenjiva kako za vremenske serije čiji su nivoi izraženi u apsolutnim vrijednostima (t, hiljada rubalja, broj zaposlenih, itd.), tako i za vremenske serije čiji su nivoi izražavaju se u relativnim pokazateljima (% nedostataka, % pepela u uglju itd.) ili prosječnim vrijednostima (prosječan prinos u c/ha, prosječna plata i sl.).
Uz razmatrane analitičke pokazatelje, izračunate za svaku godinu u poređenju sa prethodnim ili početnim nivoom, pri analizi dinamičkih serija izuzetno je važno izračunati prosječne analitičke pokazatelje za period: prosječni nivo serije, prosječni godišnji apsolutni povećanje (smanjenje) i prosječna godišnja stopa rasta i stopa rasta .
Metode za izračunavanje prosječnog nivoa serije dinamike su razmatrane gore. U nizu dinamike intervala koji razmatramo, prosječni nivo serije izračunava se pomoću jednostavne aritmetičke srednje formule:
Prosječni godišnji obim proizvodnje proizvoda za 1994-1998. iznosio je 218,4 hiljade tona.
Prosječni godišnji apsolutni rast se također izračunava pomoću formule aritmetičke sredine
Standardna devijacija - pojam i vrste. Klasifikacija i karakteristike kategorije "Srednja kvadratna devijacija" 2017, 2018.
Standardna devijacija je jedan od onih statističkih pojmova u korporativnom svijetu koji daje kredibilitet ljudima koji to uspijevaju dobro izvesti u razgovoru ili prezentaciji, ostavljajući pritom nejasan osjećaj zbunjenosti među onima koji ne znaju što je to, ali su previše neugodno pitati. U stvari, većina menadžera ne razumije koncept standardne devijacije i ako ste jedan od njih, vrijeme je da prestanete živjeti u laži. U današnjem članku ću vam reći kako vam ova nedovoljno cijenjena statistička mjera može pomoći da bolje razumijete podatke s kojima radite.
Šta mjeri standardna devijacija?
Zamislite da ste vlasnik dvije radnje. A da biste izbjegli gubitke, važno je imati jasnu kontrolu stanja zaliha. U pokušaju da saznate koji menadžer bolje upravlja zalihama, odlučujete se za analizu zadnjih šest sedmica zaliha. Prosječna sedmična cijena zaliha za obje trgovine je približno ista i iznosi oko 32 konvencionalne jedinice. Na prvi pogled, prosječan drugi krug pokazuje da oba menadžera rade slično.

Ali ako bolje pogledate aktivnosti druge trgovine, uvjerit ćete se da iako je prosječna vrijednost tačna, varijabilnost zaliha je vrlo velika (od 10 do 58 USD). Dakle, možemo zaključiti da prosjek ne procjenjuje uvijek podatke ispravno. Ovdje dolazi standardna devijacija.
Standardna devijacija pokazuje kako su vrijednosti raspoređene u odnosu na srednju vrijednost u našem . Drugim riječima, možete razumjeti koliko je veliko širenje oticaja iz sedmice u sedmicu.
U našem primjeru koristili smo Excelovu STDEV funkciju za izračunavanje standardne devijacije zajedno sa srednjom vrijednosti.

U slučaju prvog menadžera, standardna devijacija je bila 2. To nam govori da svaka vrijednost u uzorku u prosjeku odstupa 2 od srednje vrijednosti. je li dobro? Pogledajmo pitanje iz drugog ugla - standardna devijacija od 0 nam govori da je svaka vrijednost u uzorku jednaka njenoj srednjoj vrijednosti (u našem slučaju 32,2). Dakle, standardna devijacija od 2 nije mnogo drugačija od 0, što ukazuje da je većina vrijednosti blizu srednje vrijednosti. Što je standardna devijacija bliže 0, to je prosek pouzdaniji. Štaviše, standardna devijacija blizu 0 ukazuje na malu varijabilnost u podacima. Odnosno, vrijednost odljeva sa standardnom devijacijom od 2 ukazuje na nevjerovatnu konzistentnost prvog menadžera.
U slučaju druge trgovine, standardna devijacija je bila 18,9. Odnosno, cijena oticaja u prosjeku odstupa za 18,9 od prosječne vrijednosti iz sedmice u sedmicu. Crazy spread! Što je standardna devijacija dalje od 0, to je prosjek manje tačan. U našem slučaju, brojka 18,9 ukazuje da se prosječnoj vrijednosti (32,8 USD sedmično) jednostavno ne može vjerovati. To nam također govori da je sedmični protok veoma varijabilan.
Ovo je koncept standardne devijacije ukratko. Iako ne pruža uvid u druga važna statistička mjerenja (Mode, Median...), u stvari, standardna devijacija igra ključnu ulogu u većini statističkih proračuna. Razumijevanje principa standardne devijacije će baciti svjetlo na mnoge vaše poslovne procese.
Kako izračunati standardnu devijaciju?
Dakle, sada znamo šta govori broj standardne devijacije. Hajde da shvatimo kako se to izračunava.
Pogledajmo skup podataka od 10 do 70 u koracima od 10. Kao što vidite, već sam izračunao vrijednost standardne devijacije za njih koristeći STANDARDEV funkciju u ćeliji H2 (narandžasto).

Ispod su koraci koje Excel preduzima da bi stigao do 21.6.
Imajte na umu da su svi proračuni vizualizirani radi boljeg razumijevanja. U stvari, u Excelu se izračunavanje dešava trenutno, ostavljajući sve korake iza scene.
Prvo, Excel pronalazi srednju vrijednost uzorka. U našem slučaju se pokazalo da je prosjek 40, koji se u sljedećem koraku oduzima od svake vrijednosti uzorka. Svaka dobijena razlika se kvadrira i zbraja. Dobili smo zbir jednak 2800, koji se mora podijeliti sa brojem elemenata uzorka minus 1. Pošto imamo 7 elemenata, ispada da trebamo podijeliti 2800 sa 6. Iz dobivenog rezultata nalazimo kvadratni korijen, ovaj cifra će biti standardna devijacija.

Za one kojima nije sasvim jasan princip izračunavanja standardne devijacije pomoću vizualizacije, dajem matematičku interpretaciju pronalaženja ove vrijednosti.

Funkcije za izračunavanje standardne devijacije u Excelu
Excel ima nekoliko tipova formula standardne devijacije. Sve što treba da uradite je da upišete =STDEV i uverićete se sami.

Vrijedi napomenuti da funkcije STDEV.V i STDEV.G (prva i druga funkcija na listi) dupliciraju funkcije STDEV i STDEV (peta i šesta funkcija na listi), koje su zadržane radi kompatibilnosti s ranijim verzije Excel-a.
Generalno, razlika u završecima .B i .G funkcija ukazuje na princip izračunavanja standardne devijacije uzorka ili populacije. Već sam objasnio razliku između ova dva niza u prethodnom.
Posebnost funkcija STANDARDEV i STANDDREV (treća i četvrta funkcija na listi) je da se prilikom izračunavanja standardne devijacije niza uzimaju u obzir logičke i tekstualne vrijednosti. Tekst i prave logičke vrijednosti su 1, a lažne logičke vrijednosti su 0. Ne mogu zamisliti situaciju u kojoj bi mi bile potrebne ove dvije funkcije, pa mislim da se mogu zanemariti.
Standardna devijacija je klasičan indikator varijabilnosti od deskriptivne statistike.
Standardna devijacija, standardna devijacija, Standardna devijacija, uzorak standardne devijacije (eng. standard deviation, STD, STDev) je vrlo čest indikator disperzije u deskriptivnoj statistici. Ali, jer tehnička analiza je srodna statistici; ovaj indikator se može (i treba) koristiti u tehničkoj analizi za otkrivanje stepena disperzije cijene analiziranog instrumenta tokom vremena. Označeno grčkim simbolom Sigma "σ".
Hvala Carlu Gausu i Pearsonu što su nam omogućili korištenje standardne devijacije.
Koristeći standardna devijacija u tehničkoj analizi, okrećemo ovo "indeks disperzije"" V "indikator volatilnosti“, zadržavajući značenje, ali mijenjajući pojmove.
Šta je standardna devijacija
Ali pored srednjih pomoćnih proračuna, standardna devijacija je sasvim prihvatljiva za nezavisan proračun i primjene u tehničkoj analizi. Kao aktivni čitalac našeg časopisa čičak je primetio, „ Još uvijek ne razumijem zašto standardna devijacija nije uključena u set standardnih indikatora domaćih dilerskih centara«.
stvarno, standardna devijacija može mjeriti varijabilnost instrumenta na klasičan i "čist" način. Ali, nažalost, ovaj pokazatelj nije toliko čest u analizi vrijednosnih papira.
Primjena standardne devijacije
Ručno izračunavanje standardne devijacije nije baš zanimljivo, ali korisno za iskustvo. Standardna devijacija se može izraziti formula STD=√[(∑(x-x) 2)/n], koja zvuči kao korijen zbira kvadrata razlika između elemenata uzorka i srednje vrijednosti, podijeljen sa brojem elemenata u uzorku.
Ako broj elemenata u uzorku prelazi 30, tada nazivnik razlomka ispod korijena uzima vrijednost n-1. Inače se koristi n.
Korak po korak proračun standardne devijacije:
- izračunati aritmetičku sredinu uzorka podataka
- oduzmite ovaj prosjek od svakog elementa uzorka
- kvadriramo sve nastale razlike
- zbrojite sve rezultirajuće kvadrate
- rezultujuću količinu podijelite s brojem elemenata u uzorku (ili sa n-1, ako je n>30)
- izračunajte kvadratni korijen rezultirajućeg količnika (zv disperzija)
Instrukcije
Neka postoji nekoliko brojeva koji karakterišu homogene veličine. Na primjer, rezultati mjerenja, vaganja, statistička posmatranja itd. Sve prikazane količine moraju biti izmjerene pomoću istog mjerenja. Da biste pronašli standardnu devijaciju, učinite sljedeće:
Odredite aritmetičku sredinu svih brojeva: saberite sve brojeve i podijelite zbir ukupnim brojem brojeva.
Odredite disperziju (raspršenost) brojeva: dodajte kvadrate prethodno pronađenih odstupanja i rezultujući zbir podijelite sa brojem brojeva.
Na odjeljenju je sedam pacijenata sa temperaturom od 34, 35, 36, 37, 38, 39 i 40 stepeni Celzijusa.
Potrebno je odrediti prosječno odstupanje od srednje vrijednosti.
Rješenje:
“na odjelu”: (34+35+36+37+38+39+40)/7=37 ºS;
Odstupanja temperature od prosjeka (u ovom slučaju normalne vrijednosti): 34-37, 35-37, 36-37, 37-37, 38-37, 39-37, 40-37, što rezultira: -3, - 2, -1 , 0, 1, 2, 3 (ºS);
Podijelite zbir prethodno dobijenih brojeva njihovim brojem. Za tačne proračune, bolje je koristiti kalkulator. Rezultat dijeljenja je aritmetička sredina dodanih brojeva.
Obratite pažnju na sve faze proračuna, jer će greška čak i u jednom od proračuna dovesti do pogrešnog konačnog indikatora. Provjerite svoje proračune u svakoj fazi. Aritmetički prosjek ima isti metar kao i zbrojeni brojevi, odnosno, ako odredite prosječnu posjećenost, tada će svi vaši pokazatelji biti "osoba".
Ova metoda proračuna se koristi samo u matematičkim i statističkim proračunima. Na primjer, aritmetička sredina u informatici ima drugačiji algoritam proračuna. Aritmetička sredina je vrlo relativan pokazatelj. Pokazuje vjerovatnoću događaja, pod uslovom da ima samo jedan faktor ili indikator. Za najdublju analizu potrebno je uzeti u obzir mnoge faktore. U tu svrhu koristi se proračun opštijih veličina.
Aritmetička sredina je jedna od mjera centralne tendencije, koja se široko koristi u matematici i statističkim proračunima. Pronalaženje aritmetičkog prosjeka za nekoliko vrijednosti je vrlo jednostavno, ali svaki zadatak ima svoje nijanse, koje je jednostavno potrebno znati kako biste izvršili ispravne proračune.
Kvantitativni rezultati sličnih eksperimenata.
Kako pronaći aritmetičku sredinu
Potražite prosjek aritmetički broj za niz brojeva, trebali biste početi određivanjem algebarskog zbira ovih vrijednosti. Na primjer, ako niz sadrži brojeve 23, 43, 10, 74 i 34, tada će njihov algebarski zbir biti jednak 184. Prilikom pisanja, aritmetička sredina se označava slovom μ (mu) ili x (x sa a bar). Zatim, algebarski zbir treba podijeliti sa brojem brojeva u nizu. U primjeru koji se razmatra bilo je pet brojeva, tako da će aritmetička sredina biti jednaka 184/5 i biće 36,8.Značajke rada s negativnim brojevima
Ako niz sadrži negativni brojevi, tada se aritmetička sredina nalazi korištenjem sličnog algoritma. Razlika postoji samo kada se računa u programskom okruženju ili ako problem ima dodatne uslove. U ovim slučajevima, pronalaženje aritmetičke sredine brojeva sa različiti znakovi svodi se na tri koraka:1. Pronalaženje opšte aritmetičke sredine standardnom metodom;
2. Pronalaženje aritmetičke sredine negativnih brojeva.
3. Izračunavanje aritmetičke sredine pozitivnih brojeva.
Odgovori za svaku radnju su napisani odvojeni zarezima.
Prirodni i decimalni razlomci
Ako je prikazan niz brojeva decimale, rješenje se provodi metodom izračunavanja aritmetičke sredine cijelih brojeva, ali se rezultat umanjuje prema zahtjevima zadatka za tačnost odgovora.Kada radite s prirodnim razlomcima, treba ih svesti na zajednički nazivnik, koji se množi brojem brojeva u nizu. Brojač odgovora će biti zbir datih brojnika originalnih razlomaka.
$X$. Za početak, podsjetimo se sljedeće definicije:
Definicija 1
Populacija-- skup nasumično odabranih objekata date vrste, nad kojima se provode opservacije kako bi se dobile specifične vrijednosti slučajne varijable, koje se provode pod konstantnim uvjetima pri proučavanju jedne slučajne varijable datog tipa.
Definicija 2
Opća varijansa-- aritmetička sredina kvadrata odstupanja vrijednosti varijante populacije od njihove srednje vrijednosti.
Neka vrijednosti opcije $x_1,\ x_2,\dots ,x_k$ imaju, respektivno, frekvencije $n_1,\ n_2,\dots ,n_k$. Tada se opća varijansa izračunava pomoću formule:
Razmotrimo poseban slučaj. Neka su sve opcije $x_1,\ x_2,\dots ,x_k$ različite. U ovom slučaju $n_1,\ n_2,\dots ,n_k=1$. Nalazimo da se u ovom slučaju opća varijansa izračunava pomoću formule:
Ovaj koncept je takođe povezan sa konceptom opšte standardne devijacije.
Definicija 3
Opća standardna devijacija
\[(\sigma )_g=\sqrt(D_g)\]
Varijanca uzorka
Neka nam je data populacija uzorka u odnosu na slučajnu varijablu $X$. Za početak, podsjetimo se sljedeće definicije:
Definicija 4
Populacija uzorka -- dio odabranih objekata iz opće populacije.
Definicija 5
Varijanca uzorka-- prosek aritmetičke vrijednosti opcija uzorkovanja.
Neka vrijednosti opcije $x_1,\ x_2,\dots ,x_k$ imaju, respektivno, frekvencije $n_1,\ n_2,\dots ,n_k$. Zatim se varijansa uzorka izračunava pomoću formule:
Razmotrimo poseban slučaj. Neka su sve opcije $x_1,\ x_2,\dots ,x_k$ različite. U ovom slučaju $n_1,\ n_2,\dots ,n_k=1$. Nalazimo da se u ovom slučaju varijansa uzorka izračunava pomoću formule:
Takođe je povezan sa ovim konceptom koncept standardne devijacije uzorka.
Definicija 6
Standardna devijacija uzorka-- kvadratni korijen opće varijanse:
\[(\sigma )_v=\sqrt(D_v)\]
Ispravljena varijansa
Da biste pronašli ispravljenu varijansu $S^2$ potrebno je pomnožiti varijansu uzorka sa razlomkom $\frac(n)(n-1)$, tj.
Ovaj koncept je također povezan s konceptom korigirane standardne devijacije, koji se nalazi po formuli:
U slučaju kada vrijednosti varijanti nisu diskretne, već predstavljaju intervale, tada se u formulama za izračunavanje općih ili uzoraka varijansi vrijednost $x_i$ uzima kao vrijednost sredine intervala do kojoj pripada $x_i.$.
Primjer problema za pronalaženje varijanse i standardne devijacije
Primjer 1
Populacija uzorka definirana je sljedećom tablicom distribucije:
Slika 1.
Pronađimo za njega varijansu uzorka, standardnu devijaciju uzorka, ispravljenu varijansu i korigovanu standardnu devijaciju.
Da bismo riješili ovaj problem, prvo napravimo tablicu proračuna:
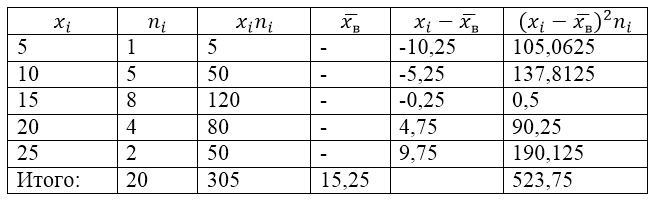
Slika 2.
Vrijednost $\overline(x_v)$ (prosjek uzorka) u tabeli nalazi se po formuli:
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)\]
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)=\frac(305)(20)=15,25\]
Nađimo uzorak varijanse koristeći formulu:
Standardna devijacija uzorka:
\[(\sigma )_v=\sqrt(D_v)\približno 5,12\]
Ispravljena varijansa:
\[(S^2=\frac(n)(n-1)D)_v=\frac(20)(19)\cdot 26.1875\približno 27.57\]
Ispravljena standardna devijacija.