 ورود
ورودفرمول انحراف استاندارد تصحیح شده تفسیر مقدار انحراف معیار. شاخص های متوسط، تعریف آنها
میانگین انحراف معیار
اکثر مشخصه کاملتنوع انحراف معیار است، ĸᴏᴛᴏᴩᴏᴇ استاندارد (یا انحراف معیار) نامیده می شود. انحراف معیار() برابر است با جذر مجذور میانگین انحراف مقادیر ویژگی های فردی از میانگین حسابی:
انحراف استاندارد ساده است:


انحراف استاندارد وزنی برای داده های گروه بندی شده اعمال می شود:

بین میانگین مربع و میانگین انحراف خطی در شرایط توزیع نرمال، رابطه زیر برقرار است: ~ 1.25.
انحراف معیار، به عنوان معیار مطلق اصلی تغییرات، در تعیین مقادیر ارادات منحنی توزیع نرمال، در محاسبات مربوط به سازماندهی مشاهده نمونه و تعیین دقت ویژگی های نمونه، و همچنین در ارزیابی مرزهای تنوع یک صفت در یک جمعیت همگن
18. پراکندگی، انواع آن، انحراف معیار.
واریانس یک متغیر تصادفی- اندازه گیری گسترش یک متغیر تصادفی معین، یعنی انحراف آن از انتظارات ریاضی. در آمار، نام یا اغلب استفاده می شود. جذر واریانس نامیده می شود انحراف معیار, انحراف معیاریا پخش استاندارد
واریانس کل (σ2) تنوع یک صفت را در کل جمعیت تحت تأثیر همه عواملی که باعث این تنوع شده اند اندازه گیری می کند. در عین حال، به لطف روش گروهبندی، میتوان تغییرات ناشی از ویژگی گروهبندی و تغییراتی را که تحت تأثیر عوامل نامشخص رخ میدهد، جدا و اندازهگیری کرد.
واریانس بین گروهی (σ 2 m.gr) تنوع سیستماتیک را مشخص می کند، به عنوان مثال، تفاوت در ارزش صفت مورد مطالعه، که تحت تأثیر ویژگی - عامل زیربنایی گروه بندی ایجاد می شود.
انحراف معیار(مترادف: انحراف معیار, انحراف معیار, انحراف معیار; اصطلاحات مرتبط: انحراف معیار, گسترش استاندارد) - در تئوری احتمالات و آمار، رایج ترین شاخص پراکندگی مقادیر یک متغیر تصادفی نسبت به انتظارات ریاضی آن است. با آرایه های محدود از نمونه های مقادیر، به جای انتظار ریاضی، از میانگین حسابی مجموعه نمونه ها استفاده می شود.
انحراف معیار در واحدهای خود متغیر تصادفی اندازهگیری میشود و هنگام محاسبه خطای استاندارد میانگین حسابی، هنگام ساخت فواصل اطمینان، هنگام آزمون آماری فرضیهها و هنگام اندازهگیری رابطه خطی بین متغیرهای تصادفی استفاده میشود. که تعریف میشود ریشه دوماز واریانس یک متغیر تصادفی
انحراف معیار:

انحراف معیار (تخمین انحراف معیار یک متغیر تصادفی ایکسنسبت به انتظارات ریاضی آن بر اساس برآورد بی طرفانه از واریانس آن):

پراکندگی کجاست - منعنصر نمونه -ام - اندازهی نمونه؛ - میانگین حسابی نمونه:
![]()
لازم به ذکر است که هر دو برآورد مغرضانه هستند. در حالت کلی، ایجاد یک تخمین بی طرفانه غیرممکن است. در عین حال، برآورد بر اساس برآورد واریانس بی طرفانه سازگار است.
19. ماهیت، محدوده و رویه تعیین مد و میانه.
علاوه بر میانگینهای قانون قدرت در آمار برای یک مشخصه نسبی از بزرگی یک ویژگی متغیر و ساختار داخلیسری های توزیع از میانگین های ساختاری استفاده می کنند که عمدتاً با نشان داده می شوند حالت و میانه.
روش- این رایج ترین نوع سری است. از مد استفاده می شود، به عنوان مثال، هنگام تعیین اندازه لباس، کفش هایی که بیشترین تقاضا را در بین خریداران دارند. حالت برای یک سری گسسته، نوع با بالاترین فرکانس است. هنگام محاسبه حالت برای یک سری تغییرات بازه ای، بسیار مهم است که ابتدا فاصله مودال (با حداکثر فرکانس) و سپس مقدار مقدار مدال ویژگی با استفاده از فرمول تعیین شود:

§ - ارزش مد
§ - حد پایین بازه مودال
§ - مقدار فاصله
§ - فرکانس فاصله معین
§ - فرکانس فاصله قبل از مدال
§ - فرکانس فاصله پس از مدال
میانه -این مقدار ویژگی، ĸᴏᴛᴏᴩᴏᴇ در پایه سری رتبه بندی شده قرار دارد و این سری را به دو قسمت مساوی از نظر تعداد تقسیم می کند.
برای تعیین میانه در یک سری مجزادر حضور فرکانس ها ابتدا نصف جمع فرکانس ها محاسبه می شود و سپس مشخص می شود که چه مقدار از متغیر بر روی آن قرار می گیرد. (اگر ردیف مرتب شده حاوی عدد فردعلامت می دهد، سپس تعداد میانه با فرمول محاسبه می شود:
M e \u003d (n (تعداد ویژگی ها در مجموع) + 1) / 2،
در مورد تعداد زوج از ویژگی ها، میانه برابر با میانگین دو ویژگی واقع در وسط سری خواهد بود).
هنگام محاسبه میانه برای سری تغییرات بازه ایابتدا فاصله میانه ای که میانه در آن قرار دارد را تعیین کنید و سپس مقدار میانه را طبق فرمول تعیین کنید:

§ - میانه مورد نظر
§ - کران پایین بازه ای که حاوی میانه است
§ - مقدار فاصله
§ - مجموع فرکانس ها یا تعداد اعضای سری
§ - مجموع فرکانس های انباشته شده بازه های قبل از میانه
§ - فرکانس فاصله متوسط
مثال. حالت و میانه را پیدا کنید.
تصمیم گیری: در این مثال، فاصله مودال در گروه سنی 30-25 سال است، زیرا این بازه بیشترین فراوانی (1054) را به خود اختصاص داده است.
بیایید مقدار حالت را محاسبه کنیم:
یعنی سن معدل دانش آموزان 27 سال است.
بیایید میانه را محاسبه کنیم. فاصله متوسط در گروه سنی 25 تا 30 سال است، زیرا در این بازه متغیری وجود دارد که جمعیت را به دو قسمت مساوی تقسیم می کند (Σf i /2 = 3462/2 = 1731). سپس داده های عددی لازم را در فرمول جایگزین می کنیم و مقدار میانه را بدست می آوریم:

این بدان معناست که نیمی از دانش آموزان زیر 27.4 سال و نیمی دیگر بالای 27.4 سال سن دارند.
علاوه بر حالت و میانه، از شاخص هایی مانند چارک های تقسیم سری رتبه بندی شده به 4 قسمت مساوی، دهک ها - 10 قسمتی و صدک ها - به 100 قسمت استفاده می شود.
20. مفهوم مشاهده انتخابی و دامنه آن.
مشاهده انتخابیهنگام اعمال مشاهده مداوم اعمال می شود از نظر فیزیکی غیر ممکنبه دلیل حجم زیاد داده یا از نظر اقتصادی غیر عملی. عدم امکان فیزیکی، به عنوان مثال، هنگام مطالعه جریان مسافر، قیمت بازار، بودجه خانواده رخ می دهد. عدم مصلحت اقتصادی هنگام ارزیابی کیفیت کالاهای مرتبط با تخریب آنها، به عنوان مثال، چشیدن، آزمایش آجر برای استحکام و غیره رخ می دهد.
واحدهای آماری انتخاب شده برای مشاهده می باشد چارچوب نمونهیا نمونه برداریو کل آرایه آنها - جمعیت عمومی(GS). که در آن تعداد واحدهای نمونهتعیین کنند nو در تمام GS - ن. نگرش n/nتماس گرفت اندازه نسبییا سهم نمونه.
کیفیت نتایج نمونه گیری بستگی دارد نمایندگی نمونه، یعنی اینکه چقدر در HS نماینده است. برای اطمینان از نماینده بودن نمونه، ضروری است که اصل انتخاب تصادفی واحدها، که فرض می کند گنجاندن یک واحد HS در نمونه نمی تواند تحت تأثیر هیچ عامل دیگری غیر از شانس باشد.
وجود داشته باشد 4 روش انتخاب تصادفیبرای نمونه:
- در واقع تصادفیانتخاب یا ʼʼروش لوتوʼʼ، زمانی که آمار اختصاص داده می شود اعداد دنباله ای، روی اشیاء خاصی (مثلاً کیگ) آورده می شود، که سپس در یک ظرف خاص (مثلاً در یک کیسه) مخلوط می شوند و به طور تصادفی انتخاب می شوند. در عمل، این روش با استفاده از یک مولد اعداد تصادفی یا جداول ریاضی اعداد تصادفی انجام می شود.
- مکانیکیانتخاب، که بر اساس آن هر ( N/n)-ام مقدار جمعیت. به عنوان مثال، اگر شامل 100000 مقدار باشد و شما بخواهید 1000 را انتخاب کنید، هر 100000 / 1000 = 100 مقدار در نمونه قرار می گیرد. ضمناً اگر رتبه بندی نشوند، نفر اول به طور تصادفی از صد نفر اول انتخاب می شود و تعداد بقیه صد نفر بیشتر می شود. به عنوان مثال، اگر اولین واحد شماره 19 بود، واحد بعدی باید شماره 119، سپس شماره 219، سپس شماره 319 و غیره باشد. در صورت رتبه بندی واحدهای جمعیت عمومی ابتدا شماره 50 و سپس شماره 150 و سپس شماره 250 و ... انتخاب می شود.
- انتخاب مقادیر از یک آرایه داده ناهمگن انجام می شود طبقه بندی شدهروش (طبقهای)، زمانی که جمعیت عمومی قبلاً به گروههای همگن تقسیم میشوند که انتخاب تصادفی یا مکانیکی برای آنها اعمال میشود.
- مسیر خاصنمونه گیری است سریالانتخابی، که در آن کمیتهای منفرد بهطور تصادفی یا مکانیکی انتخاب نمیشوند، بلکه سریهای آنها (توالیهایی از یک عدد به تعدادی متوالی)، که در آن مشاهده مداوم انجام میشود.
کیفیت مشاهدات نمونه نیز بستگی دارد نوع نمونه گیری: تکرار کردیا غیر تکراری.در انتخاب مجددمقادیر آماری یا سری آنها که در نمونه قرار گرفته اند، پس از استفاده به جامعه عمومی بازگردانده می شوند و فرصتی برای ورود به نمونه جدید دارند. در عین حال، همه مقادیر جمعیت عمومی احتمال یکسانی برای قرار گرفتن در نمونه را دارند. انتخاب بدون تکراربه این معنی که مقادیر آماری یا سری آنها در نمونه پس از استفاده به جامعه عمومی بازگردانده نمی شود و بنابراین احتمال ورود به نمونه بعدی برای مقادیر باقیمانده دومی افزایش می یابد.
نمونه گیری غیر تکراری نتایج دقیق تری می دهد و بنابراین بیشتر مورد استفاده قرار می گیرد. اما شرایطی وجود دارد که نمی توان آن را اعمال کرد (مطالعه جریان مسافر، تقاضای مصرف کننده و غیره) و سپس یک انتخاب مجدد انجام می شود.
21. خطای نمونه گیری محدود مشاهده، میانگین خطای نمونه گیری، ترتیب محاسبه آنها.
اجازه دهید روش های بالا برای تشکیل یک جامعه نمونه و خطاهای نمایندگی که در این مورد ایجاد می شود را با جزئیات در نظر بگیریم. در واقع تصادفینمونه بر اساس انتخاب واحدها از جامعه عمومی به صورت تصادفی بدون هیچ گونه عنصر سازگاری است. از نظر فنی، انتخاب تصادفی مناسب با قرعه کشی (مثلاً قرعه کشی) یا جدول اعداد تصادفی انجام می شود.
انتخاب واقعی تصادفی "در شکل خالص آن" در عمل مشاهده انتخابی به ندرت استفاده می شود، اما در میان انواع دیگر انتخاب اولیه است، اصول اساسی مشاهده انتخابی را اجرا می کند. چند سوال تئوری را در نظر بگیرید روش نمونه گیریو فرمول های خطا برای یک نمونه تصادفی ساده.
خطای نمونه گیری- ϶ᴛᴏ تفاوت بین مقدار پارامتر در جمعیت عمومی و مقدار آن محاسبه شده از نتایج مشاهده نمونه. توجه به این نکته ضروری است که برای مشخصه کمی متوسط، خطای نمونه گیری با تعیین می شود
نشانگر معمولاً خطای نمونه برداری حاشیه ای نامیده می شود. میانگین نمونه یک متغیر تصادفی است که می تواند انتخاب شود معانی مختلفبر اساس کدام واحدها در نمونه قرار گرفتند. بنابراین خطاهای نمونه گیری نیز متغیرهای تصادفی هستند و می توانند مقادیر متفاوتی به خود بگیرند. به همین دلیل میانگین از خطاهای احتمالی – میانگین خطای نمونه گیری، که بستگی به این دارد:
اندازه نمونه: هر چه عدد بزرگتر باشد، میانگین خطا کوچکتر است.
درجه تغییر در صفت مورد مطالعه: هر چه تنوع صفت کمتر و در نتیجه واریانس آن کمتر باشد میانگین خطای نمونه گیری کمتر می شود.
در انتخاب مجدد تصادفیمیانگین خطا محاسبه می شود. در عمل، واریانس کلی دقیقاً مشخص نیست، اما در نظریه احتمال ثابت شده است که ![]() . از آنجایی که مقدار n به اندازه کافی بزرگ نزدیک به 1 است، می توانیم فرض کنیم که . سپس میانگین خطای نمونه گیری باید محاسبه شود: . اما در موارد نمونه کوچک (برای n<30) коэффициент крайне важно учитывать, и среднюю ошибку малой выборки рассчитывать по формуле
. از آنجایی که مقدار n به اندازه کافی بزرگ نزدیک به 1 است، می توانیم فرض کنیم که . سپس میانگین خطای نمونه گیری باید محاسبه شود: . اما در موارد نمونه کوچک (برای n<30) коэффициент крайне важно учитывать, и среднюю ошибку малой выборки рассчитывать по формуле  .
.
در نمونه گیری تصادفیفرمول های داده شده با مقدار تصحیح می شوند. سپس میانگین خطای عدم نمونه گیری برابر است با:  و
و  . زیرا همیشه کمتر از، سپس ضریب () همیشه کمتر از 1 است. این بدان معنی است که میانگین خطا در انتخاب غیر تکراری همیشه کمتر از انتخاب تکراری است. نمونه برداری مکانیکیزمانی استفاده می شود که جمعیت عمومی به نحوی مرتب شده باشند (مثلاً لیست های رأی دهندگان به ترتیب حروف الفبا، شماره تلفن، شماره خانه ها، آپارتمان ها). انتخاب واحدها در بازه زمانی معینی که برابر با متقابل درصد نمونه برداری است انجام می شود. بنابراین، با یک نمونه 2٪، هر 50 واحد = 1 / 0.02، با 5٪، هر 1 / 0.05 = 20 واحد از جمعیت عمومی انتخاب می شود.
. زیرا همیشه کمتر از، سپس ضریب () همیشه کمتر از 1 است. این بدان معنی است که میانگین خطا در انتخاب غیر تکراری همیشه کمتر از انتخاب تکراری است. نمونه برداری مکانیکیزمانی استفاده می شود که جمعیت عمومی به نحوی مرتب شده باشند (مثلاً لیست های رأی دهندگان به ترتیب حروف الفبا، شماره تلفن، شماره خانه ها، آپارتمان ها). انتخاب واحدها در بازه زمانی معینی که برابر با متقابل درصد نمونه برداری است انجام می شود. بنابراین، با یک نمونه 2٪، هر 50 واحد = 1 / 0.02، با 5٪، هر 1 / 0.05 = 20 واحد از جمعیت عمومی انتخاب می شود.
مبدا به روش های مختلف انتخاب می شود: به طور تصادفی، از وسط فاصله، با تغییر در مبدا. نکته اصلی جلوگیری از خطای سیستماتیک است. به عنوان مثال، با یک نمونه 5 درصد، اگر 13 به عنوان اولین واحد انتخاب شود، سپس 33، 53، 73، و غیره بعدی.
از نظر دقت، انتخاب مکانیکی به نمونهبرداری تصادفی مناسب نزدیک است. به همین دلیل از فرمول های انتخاب تصادفی مناسب برای تعیین میانگین خطای نمونه گیری مکانیکی استفاده می شود.
در انتخاب معمولیجمعیت مورد بررسی ابتدا به گروه های همگن و تک نوع تقسیم می شود. به عنوان مثال، هنگام بررسی شرکت ها، اینها صنایع، زیربخش ها هستند، در حالی که مطالعه جمعیت - مناطق، گروه های اجتماعی یا سنی است. در مرحله بعد، از هر گروه به صورت مکانیکی یا تصادفی یک انتخاب مستقل انجام می شود.
نمونه گیری معمولی نتایج دقیق تری نسبت به روش های دیگر می دهد. نوعبندی جمعیت عمومی، نمایش هر گروه گونهشناختی را در نمونه تضمین میکند، که امکان حذف تأثیر واریانس بین گروهی بر میانگین خطای نمونه را فراهم میکند. بنابراین، هنگام یافتن خطای یک نمونه معمولی با توجه به قانون جمع واریانس ها ()، توجه به میانگین واریانس های گروه بسیار مهم است. سپس میانگین خطای نمونه گیری: با انتخاب مکرر، با انتخاب غیر تکراری  ، جایی که
، جایی که  میانگین واریانس های درون گروهی در نمونه است.
میانگین واریانس های درون گروهی در نمونه است.
انتخاب سریال (یا تو در تو).زمانی استفاده می شود که جامعه قبل از شروع بررسی نمونه به سری یا گروه ها تقسیم شود. این مجموعه ها بسته های محصولات نهایی، گروه های دانشجویی، تیم ها هستند. سری ها برای معاینه به صورت مکانیکی یا تصادفی انتخاب می شوند و در داخل مجموعه بررسی کامل واحدها انجام می شود. به همین دلیل، میانگین خطای نمونه گیری فقط به واریانس بین گروهی (بین سری) بستگی دارد که با فرمول محاسبه می شود:  جایی که r تعداد سری های انتخاب شده است. میانگین سری i است. میانگین خطای نمونه گیری سریال محاسبه می شود: با انتخاب مجدد، با انتخاب غیر تکراری
جایی که r تعداد سری های انتخاب شده است. میانگین سری i است. میانگین خطای نمونه گیری سریال محاسبه می شود: با انتخاب مجدد، با انتخاب غیر تکراری  ، که در آن R تعداد کل سری ها است. ترکیب شدهانتخاب ترکیبی از روش های انتخاب در نظر گرفته شده است.
، که در آن R تعداد کل سری ها است. ترکیب شدهانتخاب ترکیبی از روش های انتخاب در نظر گرفته شده است.
میانگین خطای نمونه گیری برای هر روش انتخابی عمدتاً به اندازه مطلق نمونه و تا حدی کمتر به درصد نمونه بستگی دارد. فرض کنید 225 مشاهده در مورد اول از جمعیت 4500 واحدی و در مورد دوم از 225000 واحد انجام شده است. واریانس در هر دو حالت برابر با 25 است. سپس در حالت اول با انتخاب 5% خطای نمونه گیری به صورت زیر خواهد بود:  در حالت دوم، با انتخاب 0.1% برابر با:
در حالت دوم، با انتخاب 0.1% برابر با:
 با کاهش 50 برابری درصد نمونه گیری، خطای نمونه گیری اندکی افزایش یافت، زیرا حجم نمونه تغییر نکرد. فرض کنید حجم نمونه به 625 مشاهده افزایش یافته است. در این حالت خطای نمونه گیری به صورت زیر است:
با کاهش 50 برابری درصد نمونه گیری، خطای نمونه گیری اندکی افزایش یافت، زیرا حجم نمونه تغییر نکرد. فرض کنید حجم نمونه به 625 مشاهده افزایش یافته است. در این حالت خطای نمونه گیری به صورت زیر است:  افزایش 2.8 برابری نمونه با همان اندازه جامعه عمومی، اندازه خطای نمونه گیری را بیش از 1.6 برابر کاهش می دهد.
افزایش 2.8 برابری نمونه با همان اندازه جامعه عمومی، اندازه خطای نمونه گیری را بیش از 1.6 برابر کاهش می دهد.
22.روش ها و روش های تشکیل جامعه نمونه.
در آمار از روش های مختلفی برای تشکیل مجموعه های نمونه استفاده می شود که با توجه به اهداف مطالعه تعیین می شود و به ویژگی های موضوع مطالعه بستگی دارد.
شرط اصلی انجام یک نظرسنجی نمونه، جلوگیری از بروز خطاهای سیستماتیک ناشی از نقض اصل فرصت های برابر برای ورود هر واحد از جامعه عمومی به نمونه است. پیشگیری از خطاهای سیستماتیک در نتیجه استفاده از روش های مبتنی بر علمی برای تشکیل یک جامعه نمونه حاصل می شود.
روش های زیر برای انتخاب واحدها از جمعیت عمومی وجود دارد: 1) انتخاب فردی - واحدهای فردی در نمونه انتخاب می شوند. 2) انتخاب گروه - گروه ها یا مجموعه ای از واحدهای مورد مطالعه از نظر کیفی در نمونه قرار می گیرند. 3) انتخاب ترکیبی ترکیبی از انتخاب فردی و گروهی است. روش های انتخاب با قوانین تشکیل جامعه نمونه تعیین می شود.
نمونه باید:
- تصادفی مناسبشامل این واقعیت است که نمونه در نتیجه انتخاب تصادفی (غیر عمدی) واحدهای فردی از جمعیت عمومی تشکیل می شود. در این حالت معمولاً تعداد واحدهای انتخاب شده در مجموعه نمونه بر اساس نسبت پذیرفته شده نمونه تعیین می شود. سهم نمونه نسبت تعداد واحدهای جمعیت نمونه n به تعداد واحدهای جمعیت عمومی N, ᴛ.ᴇ است.
- مکانیکیشامل این واقعیت است که انتخاب واحدها در نمونه از جمعیت عمومی انجام می شود که به فواصل مساوی (گروه ها) تقسیم می شوند. در این حالت، اندازه فاصله در جامعه عمومی برابر است با متقابل نسبت نمونه. بنابراین، با یک نمونه 2٪، هر 50 واحد (1:0.02)، با یک نمونه 5٪، هر 20 واحد (1:0.05) انتخاب می شود. Τᴀᴋᴎᴍ ᴏϬᴩᴀᴈᴏᴍ، مطابق با نسبت پذیرفته شده انتخاب، جمعیت عمومی به طور مکانیکی به گروههای مساوی تقسیم می شود. از هر گروه در نمونه فقط یک واحد انتخاب می شود.
- معمول -که در آن ابتدا جمعیت عمومی به گروه های معمولی همگن تقسیم می شود. علاوه بر این، از هر گروه معمولی، یک انتخاب جداگانه از واحدها در نمونه توسط یک نمونه تصادفی یا مکانیکی انجام می شود. یکی از ویژگی های مهم نمونه معمولی این است که نتایج دقیق تری را در مقایسه با سایر روش های انتخاب واحد در یک نمونه به دست می دهد.
- سریال- که در آن جمعیت عمومی به گروه های هم اندازه تقسیم می شود - سری. سری ها در مجموعه نمونه انتخاب می شوند. در داخل مجموعه، مشاهده مستمر واحدهایی که در مجموعه قرار گرفته اند انجام می شود.
- ترکیب شده- نمونه باید دو مرحله ای باشد. در این حالت ابتدا جمعیت عمومی به گروه هایی تقسیم می شوند. در مرحله بعد، گروه ها انتخاب می شوند و در دومی، واحدهای فردی انتخاب می شوند.
در آمار، روش های زیر برای انتخاب واحدها در یک نمونه متمایز می شود:
- تک مرحلهنمونه - هر واحد انتخاب شده بلافاصله بر اساس یک مبنای معین (نمونه های تصادفی و سریال) مورد مطالعه قرار می گیرد.
- چند مرحله اینمونه گیری - انتخاب از جمعیت عمومی گروه های فردی انجام می شود و واحدهای فردی از گروه ها انتخاب می شوند (نمونه معمولی با روش مکانیکی انتخاب واحدها در جامعه نمونه).
علاوه بر این، متمایز کنید:
- انتخاب مجدد- طبق طرح توپ برگشتی. در عین حال، هر واحد یا سری که در نمونه قرار گرفته است به جامعه عمومی بازگردانده می شود و بنابراین، فرصتی برای گنجاندن مجدد در نمونه دارد.
- انتخاب غیر تکراری- طبق طرح توپ برگشت نشده. نتایج دقیق تری برای همان حجم نمونه دارد.
23. تعیین حجم نمونه بسیار مهم (با استفاده از جدول دانشجو).
یکی از اصول علمی در تئوری نمونه گیری اطمینان از انتخاب تعداد کافی واحد است. از لحاظ نظری، اهمیت فوقالعاده رعایت این اصل در اثبات قضایای حدی نظریه احتمال ارائه میشود، که به فرد اجازه میدهد تعیین کند که چند واحد باید از جامعه عمومی انتخاب شود تا کافی باشد و نماینده بودن نمونه را تضمین کند.
کاهش خطای استاندارد نمونه و در نتیجه افزایش دقت برآورد، همیشه با افزایش حجم نمونه همراه است، در این راستا، در حال حاضر در مرحله سازماندهی یک مشاهده نمونه، لازم است تصمیم بگیرید که اندازه نمونه باید چقدر باشد تا از دقت مورد نیاز نتایج مشاهدات اطمینان حاصل شود. محاسبه اندازه نمونه بسیار مهم با استفاده از فرمول های مشتق شده از فرمول های خطاهای نمونه برداری حاشیه ای (A) که مربوط به یک نوع و روش انتخاب دیگر است، ساخته می شود. بنابراین، برای یک اندازه نمونه تصادفی تکراری (n)، داریم:

ماهیت این فرمول این است که با انتخاب مجدد تصادفی یک عدد بسیار مهم، حجم نمونه با مجذور ضریب اطمینان رابطه مستقیم دارد. (t2)و واریانس ویژگی تغییرات (?2) و با مجذور خطای نمونه برداری حاشیه ای (?2) نسبت معکوس دارد. به ویژه، با دو برابر شدن خطای حاشیه ای، حجم نمونه مورد نیاز باید چهار برابر کاهش یابد. از سه پارامتر، دو پارامتر (t و؟) توسط محقق تنظیم می شود. در عین حال محقق بر اساس هدف
و اهداف نمونه پیمایشی باید این سوال را مشخص کند: در چه ترکیب کمی بهتر است این پارامترها برای ارائه بهترین گزینه گنجانده شود؟ در یک مورد، او ممکن است از پایایی نتایج به دست آمده (t) بیشتر از اندازه گیری دقت (؟) راضی باشد، در مورد دیگر، برعکس. حل مسئله مربوط به مقدار خطای نمونه گیری حاشیه ای دشوارتر است، زیرا محقق در مرحله طراحی مشاهده نمونه این شاخص را ندارد، در ارتباط با این موضوع، در عمل مرسوم است که خطای نمونه برداری حاشیه ای را تعیین می کند. ، به عنوان یک قاعده، در 10٪ از سطح متوسط مورد انتظار صفت. ایجاد یک سطح متوسط فرضی را میتوان به روشهای مختلفی انجام داد: استفاده از دادههای بررسیهای مشابه قبلی، یا استفاده از دادههای چارچوب نمونهگیری و گرفتن نمونه آزمایشی کوچک.
سخت ترین چیز برای ایجاد در هنگام طراحی یک مشاهده نمونه، پارامتر سوم در فرمول (5.2) - واریانس جامعه نمونه است. در این مورد، استفاده از تمام اطلاعات در دسترس محقق از بررسی های مشابه و آزمایشی قبلی ضروری است.
سوال تعیین حجم نمونه بسیار مهم در صورتی پیچیده تر می شود که بررسی نمونه شامل مطالعه چندین ویژگی واحد نمونه باشد. در این مورد، میانگین سطوح هر یک از ویژگی ها و تنوع آنها، به عنوان یک قاعده، متفاوت است، و از این نظر، تنها با در نظر گرفتن هدف، می توان تصمیم گرفت که کدام پراکندگی از کدام یک از ویژگی ها را ترجیح دهد. و اهداف نظرسنجی
هنگام طراحی یک مشاهده نمونه، مقدار از پیش تعیین شده خطای نمونه گیری مجاز مطابق با اهداف یک مطالعه خاص و احتمال نتیجه گیری بر اساس نتایج مشاهده در نظر گرفته می شود.
به طور کلی، فرمول خطای حاشیه ای مقدار میانگین نمونه به شما امکان می دهد تعیین کنید:
‣‣‣ میزان انحرافات احتمالی شاخص های جمعیت عمومی از شاخص های جامعه نمونه؛
‣‣‣ اندازه نمونه لازم، با ارائه دقت مورد نیاز، که در آن محدودیت های خطای احتمالی از مقدار مشخصی تجاوز نمی کند.
‣‣‣ احتمال اینکه خطا در نمونه دارای حد معینی باشد.
توزیع دانش آموزیدر تئوری احتمال، این یک خانواده یک پارامتری از توزیع های کاملاً پیوسته است.
24. سری از دینامیک (بازه، لحظه)، بسته شدن سری از دینامیک.
سری دینامیک- اینها مقادیر شاخص های آماری هستند که در یک توالی زمانی مشخص ارائه می شوند.
هر سری زمانی شامل دو جزء است:
1) شاخص های دوره زمانی(سال، چهارم، ماه، روز یا تاریخ)؛
2) شاخص های مشخص کننده شی مورد مطالعهبرای دوره های زمانی یا در تاریخ های مربوطه که نامیده می شود سطوح یک عدد.
سطوح سری هم به صورت مقادیر مطلق و هم میانگین یا نسبی بیان می شوند. با توجه به وابستگی به ماهیت شاخص ها، سری های دینامیکی از مقادیر مطلق، نسبی و متوسط ساخته می شوند. سری های دینامیکی مقادیر نسبی و متوسط بر اساس سری مشتق از مقادیر مطلق ساخته می شوند. سری های بازه ای و لحظه ای دینامیک وجود دارد.
سری فاصله پویاحاوی مقادیر شاخص ها برای دوره های زمانی خاص است. در سری بازهای، سطوح را میتوان جمعبندی کرد، حجم پدیده را برای مدت طولانیتری بهدست آورد یا به اصطلاح مجموعهای انباشته شده را به دست آورد.
سریال لحظه ای پویامقادیر شاخص ها را در یک نقطه زمانی خاص (تاریخ زمانی) منعکس می کند. در مجموعههای لحظهای، محقق ممکن است فقط به تفاوت پدیدهها علاقه داشته باشد که منعکسکننده تغییر سطح سری بین تاریخهای معین است، زیرا مجموع سطوح در اینجا محتوای واقعی ندارد. مجموع تجمعی در اینجا محاسبه نمی شود.
مهمترین شرط برای ساخت صحیح سری های زمانی است مقایسه سطح سریمربوط به دوره های مختلف سطوح باید در مقادیر همگن ارائه شوند، پوشش کامل قسمت های مختلف پدیده باید یکسان باشد.
به منظور جلوگیری از تحریف دینامیک واقعی، محاسبات اولیه در مطالعه آماری (بسته شدن سری زمانی) انجام می شود که مقدم بر تحلیل آماری سری های زمانی است. زیر بستن ردیف های دینامیکمرسوم است که ترکیب را در یک ردیف از دو یا چند ردیف درک کنیم که سطوح آن بر اساس روش شناسی مختلف محاسبه می شود یا با مرزهای سرزمینی مطابقت ندارد و غیره. بسته شدن سری دینامیک ممکن است به معنای کاهش سطوح مطلق سری دینامیک به یک مبنای مشترک باشد که ناسازگاری سطوح سری دینامیک را از بین می برد.
25. مفهوم قابل مقایسه بودن سری های دینامیک، ضرایب، رشد و نرخ رشد.
سری دینامیک- اینها مجموعه ای از شاخص های آماری است که توسعه پدیده های طبیعت و جامعه را در زمان مشخص می کند. مجموعه های آماری منتشر شده توسط کمیته آمار دولتی روسیه شامل تعداد زیادی سری زمانی به صورت جدولی است. مجموعه ای از پویایی ها امکان آشکارسازی الگوهای توسعه پدیده های مورد مطالعه را فراهم می کند.
سری دینامیک شامل دو نوع نشانگر است. شاخص های زمان(سال، ربع، ماه و غیره) یا نقاط زمانی (در ابتدای سال، در آغاز هر ماه و غیره). نشانگرهای سطح ردیف. شاخص های سطوح سری های زمانی در مقادیر مطلق (تولید یک محصول به تن یا روبل)، مقادیر نسبی (سهم جمعیت شهری بر حسب درصد) و مقادیر متوسط (متوسط حقوق کارگران صنعت بر اساس) بیان می شوند. سال و غیره). به صورت جدولی، سری زمانی شامل دو ستون یا دو ردیف است.
ساخت صحیح سری های زمانی مستلزم برآوردن تعدادی از الزامات است:
- تمام شاخص های یک سری از پویایی ها باید از نظر علمی اثبات شده و قابل اعتماد باشند.
- شاخص های یک سری از دینامیک باید در زمان قابل مقایسه باشند، ᴛ.ᴇ. باید برای دوره های زمانی یکسان یا در همان تاریخ ها محاسبه شود.
- شاخص های تعدادی از پویایی ها باید در سراسر قلمرو قابل مقایسه باشند.
- شاخص های یک سری از پویایی ها باید از نظر محتوا قابل مقایسه باشند، ᴛ.ᴇ. بر اساس یک روش واحد، به همان روش محاسبه می شود.
- شاخص های یک سری از پویایی ها باید در طیف وسیعی از مزارع در نظر گرفته شده قابل مقایسه باشند. تمام شاخص های یک سری از دینامیک باید در همان واحدهای اندازه گیری داده شود.
شاخصهای آماری میتوانند نتایج فرآیند مورد مطالعه را در یک دوره زمانی مشخص کنند یا وضعیت پدیده مورد مطالعه را در یک مقطع زمانی مشخص، ᴛ.ᴇ. شاخص ها به صورت مقطعی (تناوبی) و لحظه ای هستند. بر این اساس، در ابتدا سری دینامیک یا بازه ای یا لحظه ای هستند. سری لحظه ای دینامیک به نوبه خود با فواصل زمانی مساوی و نابرابر می آید.
سری اولیه دینامیک به یک سری مقادیر متوسط و یک سری مقادیر نسبی (زنجیره و پایه) تبدیل می شود. به چنین سری های زمانی سری های زمانی مشتق شده می گویند.
روش محاسبه میانگین سطح در سری دینامیک، با توجه به نوع سری دینامیک متفاوت است. با استفاده از مثال، انواع سری های زمانی و فرمول های محاسبه سطح متوسط را در نظر بگیرید.
دستاوردهای مطلق (Δy) نشان می دهد که سطح بعدی سری چند واحد نسبت به قبلی (ستون 3. - افزایش مطلق زنجیره ای) یا در مقایسه با سطح اولیه (ستون 4. - افزایش مطلق پایه) تغییر کرده است. فرمول های محاسباتی را می توان به صورت زیر نوشت:

با کاهش مقادیر مطلق سری، به ترتیب "کاهش"، "کاهش" وجود خواهد داشت.
نرخ های رشد مطلق نشان می دهد که به عنوان مثال، در سال 1998 ᴦ. تولید محصول "الف" نسبت به سال 97 افزایش یافته است. 4 هزار تن و نسبت به سال 1994 . - 34 هزار تن؛ برای سالهای دیگر جدول را ببینید. 11.5 گرم
میزبانی شده در ref.rf
3 و 4.
عامل رشدنشان می دهد که سطح سری نسبت به قبلی (ستون 5 - عوامل رشد یا کاهش زنجیره) یا نسبت به سطح اولیه (ستون 6 - عوامل رشد یا کاهش پایه) چند برابر تغییر کرده است. فرمول های محاسباتی را می توان به صورت زیر نوشت:

نرخ رشدنشان دهید که سطح بعدی سری در مقایسه با قبلی (ستون 7 - نرخ رشد زنجیره ای) یا در مقایسه با سطح اولیه (ستون 8 - نرخ های رشد پایه) چند درصد است. فرمول های محاسباتی را می توان به صورت زیر نوشت:

بنابراین، برای مثال، در سال 1997 ᴦ. حجم تولید محصول "الف" نسبت به سال 96 . 105.5% (
نرخ رشدنشان می دهد که سطح دوره گزارش چند درصد نسبت به قبلی (ستون 9 - نرخ رشد زنجیره ای) یا نسبت به سطح اولیه (ستون 10 - نرخ های رشد پایه) افزایش یافته است. فرمول های محاسباتی را می توان به صورت زیر نوشت:
T pr \u003d T p - 100٪ یا T pr \u003d افزایش مطلق / سطح دوره قبل * 100٪
بنابراین، به عنوان مثال، در سال 1996 ᴦ. نسبت به سال 1995. محصول «الف» نسبت به سال 1994، 3.8 درصد (100.103 - 103.8 درصد) یا (8:210) در 100 درصد بیشتر تولید شده است. - با 9٪ (109٪ - 100٪).
اگر سطوح مطلق در سری کاهش یابد، آنگاه نرخ کمتر از 100٪ خواهد بود و بر این اساس، نرخ کاهش (نرخ رشد با علامت منفی) وجود خواهد داشت.
ارزش مطلق 1 درصد افزایش(گرم
میزبانی شده در ref.rf
11) نشان می دهد که در یک دوره معین چند واحد باید تولید شود تا سطح دوره قبل 1٪ افزایش یابد. در مثال ما، در سال 1995 ᴦ. تولید 2.0 هزار تن ضروری بود و در سال 1998 . - 2.3 هزار تن، ᴛ.ᴇ. بسیار بزرگتر.
دو روش برای تعیین مقدار قدر مطلق رشد 1% وجود دارد:
§ سطح دوره قبل تقسیم بر 100.
§ افزایش مطلق زنجیره تقسیم بر نرخ رشد زنجیره مربوطه.
مقدار مطلق 1% افزایش = 
در دینامیک، به ویژه در یک دوره طولانی، تجزیه و تحلیل مشترک نرخ رشد با محتوای هر درصد افزایش یا کاهش مهم است.
توجه داشته باشید که روش در نظر گرفته شده برای تجزیه و تحلیل سری های زمانی هم برای سری های زمانی که سطوح آن در مقادیر مطلق بیان می شود (t، هزار روبل، تعداد کارکنان و غیره) و برای سری های زمانی، سطوح که در شاخص های نسبی (درصد ضایعات، درصد خاکستر زغال سنگ و غیره) یا مقادیر متوسط (میانگین عملکرد بر حسب c/ha، متوسط حقوق و غیره) بیان می شوند.
در کنار شاخص های تحلیلی در نظر گرفته شده محاسبه شده برای هر سال در مقایسه با سطح قبلی یا اولیه، هنگام تجزیه و تحلیل سری های زمانی، محاسبه میانگین شاخص های تحلیلی برای دوره بسیار مهم است: میانگین سطح سری، میانگین افزایش مطلق سالانه. (کاهش) و متوسط نرخ رشد سالانه و نرخ رشد .
روشهای محاسبه میانگین سطح یک سری از دینامیک در بالا مورد بحث قرار گرفت. در سری بازهای دینامیک مورد نظر، میانگین سطح سری با فرمول میانگین حسابی ساده محاسبه میشود:
میانگین تولید سالانه محصول برای سال های 1994-1998. 218.4 هزار تن بوده است.
میانگین افزایش مطلق سالانه نیز با فرمول میانگین حسابی محاسبه می شود
انحراف استاندارد - مفهوم و انواع. طبقه بندی و ویژگی های دسته "انحراف استاندارد" 2017، 2018.
انحراف استاندارد یکی از آن اصطلاحات آماری در دنیای شرکتها است که چهره افرادی را که موفق میشوند در یک مکالمه یا ارائه آن را خراب کنند، افزایش میدهد و برای کسانی که نمیدانند چیست اما خجالت میکشند، سوء تفاهم مبهمی ایجاد میکند. پرسیدن. در واقع، اکثر مدیران مفهوم انحراف معیار را درک نمی کنند و اگر شما یکی از آنها هستید، وقت آن رسیده است که از دروغ زندگی کردن دست بردارید. در مقاله امروز، به شما نشان خواهم داد که چگونه این آمار کم ارزش می تواند به شما در درک بهتر داده هایی که با آنها کار می کنید کمک کند.
انحراف معیار چه چیزی را اندازه گیری می کند؟
تصور کنید که صاحب دو فروشگاه هستید. و برای جلوگیری از ضرر، کنترل واضح موجودی سهام مهم است. در تلاش برای یافتن اینکه چه کسی بهترین مدیر سهام است، تصمیم می گیرید سهام شش هفته گذشته را تجزیه و تحلیل کنید. میانگین هزینه هفتگی موجودی هر دو فروشگاه تقریباً یکسان و حدود 32 واحد معمولی است. در نگاه اول میانگین ارزش سهام نشان می دهد که هر دو مدیر به یک شکل کار می کنند.

اما اگر نگاه دقیق تری به فعالیت های فروشگاه دوم بیندازید، می بینید که اگرچه میانگین مقدار صحیح است، اما تغییرپذیری سهام بسیار بالاست (از 10 تا 58 تومان). بنابراین، می توان نتیجه گرفت که میانگین همیشه داده ها را به درستی تخمین نمی زند. اینجاست که انحراف معیار به میان می آید.
انحراف استاندارد نشان می دهد که چگونه مقادیر نسبت به میانگین در ما توزیع می شوند. به عبارت دیگر، می توانید بفهمید که رواناب از هفته به هفته چقدر است.
در مثال ما از تابع Excel STDEV برای محاسبه انحراف استاندارد به همراه میانگین استفاده کردیم.

در مورد مدیر اول، انحراف استاندارد 2 بود. این به ما می گوید که هر مقدار در نمونه به طور متوسط 2 از میانگین انحراف دارد. خوب است؟ بیایید از زاویه دیگری به سوال نگاه کنیم - انحراف استاندارد 0 به ما می گوید که هر مقدار در نمونه برابر با مقدار میانگین آن است (در مورد ما 32.2). به عنوان مثال، انحراف استاندارد 2 تفاوت زیادی با 0 ندارد، که نشان می دهد بیشتر مقادیر نزدیک به میانگین هستند. هر چه انحراف معیار به صفر نزدیکتر باشد، میانگین قابل اعتمادتر است. علاوه بر این، انحراف استاندارد نزدیک به 0 نشان دهنده تنوع کمی در داده ها است. یعنی یک مقدار سینک با انحراف استاندارد 2 نشان دهنده ثبات باورنکردنی اولین مدیر است.
در مورد فروشگاه دوم، انحراف معیار 18.9 بود. یعنی هزینه رواناب به طور متوسط 18.9 از مقدار متوسط هفته به هفته انحراف دارد. انتشار دیوانه کننده! هر چه انحراف استاندارد از 0 بیشتر باشد، میانگین دقت کمتری دارد. در مورد ما، رقم 18.9 نشان می دهد که ارزش متوسط (32.8 دلار در هفته) به سادگی قابل اعتماد نیست. همچنین به ما می گوید که رواناب هفتگی بسیار متغیر است.
این مفهوم انحراف معیار به طور خلاصه است. اگرچه بینشی در مورد سایر اندازهگیریهای آماری مهم (حالت، میانه…) ارائه نمیکند، در واقع انحراف معیار نقش مهمی در بیشتر محاسبات آماری بازی میکند. درک اصول انحراف معیار، ماهیت بسیاری از فرآیندهای فعالیت شما را روشن می کند.
چگونه انحراف معیار را محاسبه کنیم؟
بنابراین، اکنون می دانیم که رقم انحراف معیار چه می گوید. بیایید ببینیم چگونه به حساب می آید.
یک مجموعه داده از 10 تا 70 را با افزایش 10 در نظر بگیرید. همانطور که می بینید، من قبلاً انحراف معیار آنها را با استفاده از تابع STDEV در سلول H2 (نارنجی) محاسبه کرده ام.

در زیر مراحل اکسل برای رسیدن به 21.6 آمده است.
لطفاً توجه داشته باشید که تمام محاسبات برای درک بهتر تجسم شده است. در واقع، در اکسل، محاسبه آنی است و تمام مراحل را پشت صحنه می گذارد.
اکسل ابتدا میانگین نمونه را پیدا می کند. در مورد ما، میانگین 40 بود که در مرحله بعد از هر مقدار نمونه کم می شود. هر تفاوت حاصل مربع و خلاصه می شود. جمع ما برابر با 2800 است که باید بر تعداد عناصر نمونه منهای 1 تقسیم شود. از آنجایی که 7 عنصر داریم، معلوم می شود که باید 2800 را بر 6 تقسیم کنیم. از نتیجه، جذر را پیدا می کنیم، این رقم. انحراف معیار خواهد بود.

برای کسانی که در اصل محاسبه انحراف معیار با استفاده از تجسم کاملاً روشن نیستند، من یک تفسیر ریاضی از یافتن این مقدار ارائه می دهم.

توابع محاسبه انحراف استاندارد در اکسل
انواع مختلفی از فرمول های انحراف استاندارد در اکسل وجود دارد. شما فقط باید =STDEV را تایپ کنید و خودتان خواهید دید.

شایان ذکر است که توابع STDEV.V و STDEV.G (توابع اول و دوم لیست) به ترتیب توابع STDEV و STDEV (پنجمین و ششمین توابع لیست) را کپی می کنند که برای سازگاری با قبلی حفظ شده اند. نسخه های اکسل
به طور کلی تفاوت در انتهای توابع In و G بیانگر اصل محاسبه انحراف معیار یک نمونه یا جمعیت است. قبلاً تفاوت بین این دو آرایه را در قسمت قبلی توضیح دادم.
یکی از ویژگی های توابع STDEV و STDEVPA (توابع سوم و چهارم در لیست) این است که هنگام محاسبه انحراف استاندارد یک آرایه، مقادیر منطقی و متنی در نظر گرفته می شود. متن و بولی های واقعی 1 و بولی های نادرست 0 هستند. تصور موقعیتی برای من سخت است که به این دو تابع نیاز داشته باشم، بنابراین فکر می کنم می توان آنها را نادیده گرفت.
انحراف استاندارد یک شاخص کلاسیک از تغییرپذیری از آمار توصیفی است.
انحراف معیار, انحراف معیار, RMS, انحراف استاندارد نمونه (English standard deviation, STD, STDev) یک معیار بسیار رایج برای پراکندگی در آمار توصیفی است. اما، چون تحلیل تکنیکال مشابه آمار است، این شاخص می تواند (و باید) در تحلیل تکنیکال برای تشخیص میزان پراکندگی قیمت ابزار تجزیه و تحلیل شده در طول زمان مورد استفاده قرار گیرد. با نماد یونانی Sigma "σ" مشخص می شود.
با تشکر از کارل گاوس و پیرسون برای این واقعیت که ما فرصت استفاده از انحراف استاندارد را داریم.
استفاده كردن انحراف معیار در تحلیل تکنیکال، این را می چرخانیم "شاخص پراکندگی" که در "شاخص نوسانات"حفظ معنی اما تغییر اصطلاحات.
انحراف معیار چیست؟
اما علاوه بر محاسبات کمکی میانی، انحراف استاندارد برای محاسبه خود کاملاً قابل قبول استو کاربردها در تحلیل تکنیکال همانطور که توسط یک خواننده فعال مجله ما اشاره کرد، " من هنوز نمی فهمم که چرا RMS در مجموعه شاخص های استاندارد مراکز معاملات داخلی گنجانده نشده است«.
واقعا، انحراف معیار می تواند به روشی کلاسیک و "خالص" تغییرپذیری یک ابزار را اندازه گیری کند. اما متاسفانه این شاخص در تحلیل اوراق بهادار چندان رایج نیست.
اعمال انحراف استاندارد
محاسبه دستی انحراف معیار چندان جالب نیست.اما برای تجربه مفید است انحراف معیار را می توان بیان کردفرمول STD=√[(∑(x-x) 2)/n]، که به نظر می رسد مجموع مجذور اختلاف بین آیتم های نمونه و میانگین، تقسیم بر تعداد آیتم های نمونه.
اگر تعداد عناصر در نمونه از 30 بیشتر شود، مخرج کسری زیر ریشه مقدار n-1 را می گیرد. در غیر این صورت از n استفاده می شود.
گام به گام محاسبه انحراف استاندارد:
- میانگین حسابی نمونه داده را محاسبه کنید
- این میانگین را از هر عنصر نمونه کم کنید
- تمام تفاوت های حاصل مربع هستند
- تمام مربع های حاصل را جمع کنید
- مجموع حاصل را بر تعداد عناصر موجود در نمونه تقسیم کنید (یا اگر n>30 باشد بر n-1)
- جذر ضریب حاصل را محاسبه کنید (نامیده می شود پراکندگی)
دستورالعمل
بگذارید چندین عدد مشخص کننده وجود داشته باشد - یا کمیت های همگن. به عنوان مثال، نتایج اندازه گیری ها، توزین ها، مشاهدات آماری و غیره. تمام مقادیر ارائه شده باید با همان اندازه گیری اندازه گیری شوند. برای پیدا کردن انحراف معیار، موارد زیر را انجام دهید.
میانگین حسابی همه اعداد را تعیین کنید: همه اعداد را جمع کنید و حاصل را بر تعداد کل اعداد تقسیم کنید.
پراکندگی (پراکندگی) اعداد را تعیین کنید: مجذور انحرافات قبلی را جمع کنید و مجموع حاصل را بر تعداد اعداد تقسیم کنید.
هفت بیمار با دمای 34، 35، 36، 37، 38، 39 و 40 درجه سانتیگراد در بخش بستری هستند.
تعیین میانگین انحراف از میانگین الزامی است.
تصمیم:
"در بخش": (34+35+36+37+38+39+40)/7=37 ºС;
انحرافات دما از میانگین (در این مورد، مقدار نرمال): 34-37، 35-37، 36-37، 37-37، 38-37، 39-37، 40-37، معلوم می شود: -3، -2، -1، 0، 1، 2، 3 (ºС)؛
مجموع اعداد به دست آمده را بر تعداد آنها تقسیم کنید. برای دقت در محاسبه بهتر است از ماشین حساب استفاده کنید. حاصل تقسیم، میانگین حسابی جمع است.
به تمام مراحل محاسبه دقت کنید زیرا خطا در حداقل یکی از محاسبات منجر به نشانگر نهایی نادرست می شود. محاسبات دریافتی را در هر مرحله بررسی کنید. میانگین حسابی متری برابر با مجموع اعداد دارد، یعنی اگر میانگین حضور را تعیین کنید، تمام شاخص ها "شخص" خواهند بود.
این روش محاسبه فقط در محاسبات ریاضی و آماری کاربرد دارد. بنابراین، به عنوان مثال، میانگین حسابی در علوم کامپیوتر الگوریتم محاسباتی متفاوتی دارد. میانگین حسابی یک شاخص بسیار مشروط است. احتمال یک رویداد را نشان می دهد، مشروط بر اینکه فقط یک عامل یا شاخص داشته باشد. برای عمیق ترین تحلیل، عوامل زیادی باید در نظر گرفته شوند. برای این کار از محاسبه کمیت های عمومی تر استفاده می شود.
میانگین حسابی یکی از معیارهای گرایش مرکزی است که به طور گسترده در ریاضیات و محاسبات آماری استفاده می شود. یافتن میانگین حسابی برای چندین مقدار بسیار ساده است، اما هر کار تفاوت های ظریف خاص خود را دارد که برای انجام محاسبات صحیح به سادگی باید دانست.
نتایج کمی چنین آزمایشاتی.
نحوه پیدا کردن میانگین حسابی
پیدا کردن میانگین عدد حسابیبرای آرایه ای از اعداد، باید با تعیین مجموع جبری این مقادیر شروع کنید. به عنوان مثال، اگر آرایه حاوی اعداد 23، 43، 10، 74 و 34 باشد، مجموع جبری آنها برابر با 184 خواهد بود. هنگام نوشتن، میانگین حسابی با حرف μ (mu) یا x (x با یک نشان داده می شود. بار). در مرحله بعد، جمع جبری باید بر تعداد اعداد آرایه تقسیم شود. در این مثال، پنج عدد وجود داشت، بنابراین میانگین حسابی 184/5 و 36.8 خواهد بود.ویژگی های کار با اعداد منفی
اگر آرایه شامل اعداد منفی، سپس یافتن میانگین حسابی طبق الگوریتم مشابهی اتفاق می افتد. فقط هنگام محاسبه در محیط برنامه نویسی یا در صورت وجود شرایط اضافی در کار، تفاوت وجود دارد. در این موارد، یافتن میانگین حسابی اعداد با نشانه های مختلفبه سه مرحله خلاصه می شود:1. یافتن میانگین حسابی رایج با روش استاندارد.
2. یافتن میانگین حسابی اعداد منفی.
3. محاسبه میانگین حسابی اعداد مثبت.
پاسخ های هر یک از اقدامات با کاما از هم جدا شده اند.
کسرهای طبیعی و اعشاری
اگر آرایه ای از اعداد ارائه شود اعداد اعشاری، حل با توجه به روش محاسبه میانگین حسابی اعداد صحیح رخ می دهد، اما نتیجه با توجه به الزامات مسئله برای صحت پاسخ کاهش می یابد.هنگام کار با کسرهای طبیعی، باید آنها را به یک مخرج مشترک کاهش داد که در تعداد اعداد آرایه ضرب می شود. شمارنده پاسخ مجموع اعداد داده شده عناصر کسری اصلی خواهد بود.
X$. ابتدا بیایید تعریف زیر را یادآور شویم:
تعریف 1
جمعیت- مجموعه ای از اشیاء تصادفی انتخاب شده از یک نوع معین که مشاهدات روی آنها برای به دست آوردن مقادیر خاص یک متغیر تصادفی انجام می شود که در شرایط بدون تغییر هنگام مطالعه یک متغیر تصادفی از یک نوع مشخص انجام می شود.
تعریف 2
واریانس عمومی- میانگین حسابی مجذور انحراف مقادیر متغیر جمعیت عمومی از مقدار میانگین آنها.
اجازه دهید مقادیر متغیر $x_1,\ x_2,\dots, x_k$ به ترتیب دارای فرکانسهای $n_1,\ n_2,\dots,n_k$ باشند. سپس واریانس کلی با فرمول محاسبه می شود:
بیایید یک مورد خاص را در نظر بگیریم. بگذارید همه گونههای $x_1،\ x_2،\dots، x_k$ متمایز باشند. در این حالت $n_1,\ n_2,\dots ,n_k=1$. ما دریافتیم که در این مورد واریانس کلی با فرمول محاسبه می شود:
همچنین مفهوم انحراف معیار کلی با این مفهوم مرتبط است.
تعریف 3
انحراف استاندارد عمومی
\[(\sigma )_r=\sqrt(D_r)\]
واریانس نمونه
اجازه دهید یک مجموعه نمونه با توجه به یک متغیر تصادفی $X$ به ما داده شود. ابتدا بیایید تعریف زیر را یادآور شویم:
تعریف 4
جمعیت نمونه -- بخشی از اشیاء انتخاب شده از جمعیت عمومی.
تعریف 5
واریانس نمونه-- میانگین مقادیر حسابیگزینه نمونه گیری
اجازه دهید مقادیر متغیر $x_1,\ x_2,\dots, x_k$ به ترتیب دارای فرکانسهای $n_1,\ n_2,\dots,n_k$ باشند. سپس واریانس نمونه با فرمول محاسبه می شود:
بیایید یک مورد خاص را در نظر بگیریم. بگذارید همه گونههای $x_1،\ x_2،\dots، x_k$ متمایز باشند. در این حالت $n_1,\ n_2,\dots ,n_k=1$. ما دریافتیم که در این مورد، واریانس نمونه با فرمول محاسبه می شود:
مرتبط با این مفهوم نیز مفهوم انحراف معیار نمونه است.
تعریف 6
انحراف استاندارد نمونه-- جذر واریانس کلی:
\[(\sigma )_v=\sqrt(D_v)\]
واریانس اصلاح شده
برای یافتن واریانس اصلاح شده $S^2$، لازم است واریانس نمونه را در کسری $\frac(n)(n-1)$ ضرب کنیم، یعنی.
این مفهوم همچنین با مفهوم انحراف استاندارد اصلاح شده همراه است که با فرمول پیدا می شود:
در مواردی که مقدار متغیر گسسته نیست، اما بازهها را نشان میدهد، در فرمولهای محاسبه واریانس کلی یا نمونه، مقدار $x_i$ مقدار وسط بازهای است که $ در نظر گرفته میشود. x_i.$ متعلق است
مثالی از مسئله برای یافتن واریانس و انحراف معیار
مثال 1
جامعه نمونه با استفاده از جدول توزیع زیر آورده شده است:
تصویر 1.
واریانس نمونه، انحراف استاندارد نمونه، واریانس تصحیح شده و انحراف استاندارد تصحیح شده را برای آن بیابید.
برای حل این مشکل ابتدا یک جدول محاسبه می کنیم:
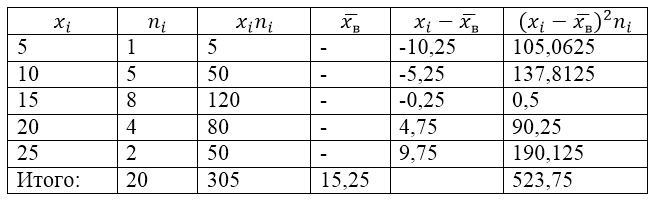
شکل 2.
مقدار $\overline(x_v)$ (میانگین نمونه) در جدول با فرمول پیدا می شود:
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)\]
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)=\frac(305)(20)=15.25\]
واریانس نمونه را با استفاده از فرمول پیدا کنید:
انحراف استاندارد نمونه:
\[(\sigma )_v=\sqrt(D_v)\تقریباً 5,12\]
واریانس تصحیح شده:
\[(S^2=\frac(n)(n-1)D)_v=\frac(20)(19)\cdot 26.1875\تقریباً 27.57\]
انحراف معیار تصحیح شد.