 入り口
入り口要約: 統計におけるサンプリング方法。 サンプル (サンプル母集団)
統計研究は非常に労力と費用がかかるため、継続的な観察を選択的な観察に置き換えるというアイデアが生まれました。
非連続観察の主な目的は、調査対象の部分について調査されている統計母集団の特徴を取得することです。
選択的観察は、ランダム選択の規定に基づいて、母集団の一般的な指標を単一の部分に対してのみ確立する統計調査の方法です。
サンプリング法では、調査対象の母集団の特定の部分のみが調査され、調査対象の統計的母集団は一般母集団と呼ばれます。
サンプル母集団、または単にサンプルは、統計調査の対象となる一般母集団から選択された単位の一部と呼ぶことができます。
サンプリング方法の値: 最小数研究中の単位に応じて、統計調査はより短期間で、最小限の資金と労力で行われます。
一般集団において、研究対象の特性を持つユニットの割合を一般割合と呼びます( R)、研究されている可変形質の平均値は一般的な平均です( バツ)。
サンプル母集団において、調査対象の特性の割合はサンプル比率、または部分 (w で示される) と呼ばれ、サンプル内の平均値は次のようになります。 標本平均。
試験中にその規則がすべて守られた場合、 科学組織の場合、サンプリング方法はかなり正確な結果を与えるため、この方法は継続的な観測からのデータを確認するために使用することをお勧めします。
この方法は、学習する最小単位数を学習する際に徹底的かつ正確な学習を可能にするため、州統計や部門以外の統計で広く普及しています。
研究対象の統計母集団は、さまざまな特性を持つ単位で構成されます。 サンプル母集団の構成は母集団の構成とは異なる場合があり、サンプルと母集団の特性間のこの不一致がサンプリング誤差を構成します。
標本観察に固有の誤差は、標本観察のデータと母集団全体との間の不一致の大きさを特徴づけます。 標本観察時に発生する誤差は代表性誤差と呼ばれ、ランダム誤差と系統的誤差に分けられます。
観察の不完全な性質によりサンプル母集団が母集団全体を正確に再現しない場合、これはランダム誤差と呼ばれ、そのサイズは法則に基づいて十分な精度で決定されます。 多数そして確率論。
系統誤差は、観察対象の母集団単位の選択におけるランダム性の原則に違反した結果として発生します。
2. 種類と選択方式
サンプリング誤差のサイズとそれを決定する方法は、選択の種類と設計によって異なります。
観測単位の母集団の選択には 4 つのタイプがあります。
1) ランダム。
2) 機械的。
3)典型的。
4) シリアル (ネスト)。
ランダムな選択– 無作為抽出による最も一般的な選択方法で、抽選法とも呼ばれます。この方法では、統計母集団の単位ごとにシリアル番号の付いたチケットが用意されます。
次に、必要な統計母集団のユニット数がランダムに選択されます。 これらの条件下では、発行されたチケットの総数から賞金が発生する番号の特定の部分がランダムに選択される場合、各チケットがサンプルに含まれる同じ確率 (たとえば、抽選) を持ちます。 この場合、すべての数値にサンプルに含まれる均等な機会が与えられます。
機械的選択- これは、母集団全体をランダムな基準に従って均一な体積のグループに分割し、各グループから 1 つの単位だけを取り出す方法です。調査対象の統計母集団のすべての単位は、特定の順序で事前に配置されていますが、サンプルサイズに応じて、必要なユニット数が一定の間隔で機械的に選択されます。
典型的な選択 –これは、調査対象の統計母集団を、本質的で典型的な特性に従って質的に均一な同じ種類のグループに分割し、次にこれらの各グループから、比重に比例して特定の数のユニットをランダムに選択する方法です。人口全体の中のグループの。
典型的な選択では、サンプル内のすべての典型的なグループの代表が含まれるため、より正確な結果が得られます。
シリアル (クラスター) の選択。ランダムまたは機械的に選択されたグループ (系列、ネスト) 全体が選択の対象となります。 このようなグループまたはシリーズごとに継続的な観察が実行され、結果が母集団全体に転送されます。
サンプルの精度はサンプリング方式にも依存します。 サンプリングは、反復または非反復サンプリング スキームに従って実行できます。
再選択。選択された各ユニットまたはシリーズは母集団全体に返され、サンプルに再入力することができます。これはいわゆるリターン ボール スキームです。
繰り返しのない選択。調査対象の各ユニットは削除され、住民には戻されないため、再調査は行われません。 この仕組みを返球といいます。
非反復サンプリングでは、同じサンプルサイズで、調査対象の母集団のより多くの単位が観察されるため、より正確な結果が得られます。
組み合わせた選択 1 つ以上の段階を経る場合があります。 選択された母集団単位が調査される場合、サンプルは単一段階と呼ばれます。
母集団の選択が段階的に連続して行われ、各段階の選択段階に独自の選択単位がある場合、サンプルは多段階と呼ばれます。
多段階サンプリング - サンプリングのすべての段階で同じサンプリング単位が維持されますが、調査プログラムの範囲とサンプルサイズが異なるいくつかの段階、つまりサンプリング調査が実行されます。
一般母集団と標本母集団のパラメータの特性は、次の記号で示されます。
N– 一般人口の量;
n- サンプルサイズ;
バツ- 全体平均;
バツ– サンプル平均。
R– 一般的なシェア。
w –サンプルシェア。
2 – 一般分散(一般集団における特性の分散)。
2 – 同じ特性のサンプル分散。
?- 平均 標準偏差一般人口において。
? – サンプルの標準偏差。
3. サンプリングエラー
サンプル観察内の各ユニットは、他のユニットと平等に選択される機会がなければなりません。これが適切なランダム サンプルの基礎です。
適切なランダムサンプリング 抽選またはその他の同様の手段によって、人口全体からユニットを選択することです。
ランダム性の原理は、サンプルに項目が含まれるか除外されるかは、偶然以外の要因には影響されないということです。
サンプルシェアサンプル母集団のユニット数と一般母集団のユニット数の比です。
純粋な形での適切なランダム選択は、他のすべてのタイプの選択の中でもオリジナルであり、選択的な統計的観察の基本原則が含まれ、実装されています。
サンプリング法で使用される一般指標の主なタイプは、定量的特性の平均値と代替特性の相対値の 2 つです。
サンプルの割合 (w)、または特殊性は、研究対象の特性を持つユニットの数の比率によって決定されます。 うーん、サンプル母集団内のユニットの総数 (n):
サンプル指標の信頼性を特徴付けるために、平均サンプリング誤差と最大サンプリング誤差が区別されます。
サンプリング誤差は代表性誤差とも呼ばれ、対応するサンプルと一般的な特性の差です。
?x =|x – x|;
?w =|x – p|。
サンプル観測値のみがサンプリング誤差の影響を受けます。
サンプル平均とサンプル比率は次の確率変数です。 さまざまな意味サンプルに含まれる調査対象の統計母集団の単位に応じて異なります。 したがって、サンプリング誤差も確率変数であり、異なる値をとる可能性があります。 したがって、次の平均を求めます。 考えられるエラー– 平均サンプリング誤差。
平均サンプリング誤差はサンプル サイズによって決まります。他の条件が同じであれば、数値が大きいほど、平均サンプリング誤差は小さくなります。 サンプル調査で対象とする一般集団の数を増やすことにより、一般集団全体の特徴をより正確に把握できます。
平均サンプリング誤差は、調査対象の特性の変動の程度に依存します。つまり、変動の程度は分散によって特徴付けられます。 2または w(l – w)– 代替記号の場合。 形質の変動と分散が小さいほど、平均サンプリング誤差は小さくなり、その逆も同様です。
ランダムに繰り返しサンプリングを行う場合、平均誤差は理論的には次の式を使用して計算されます。
1) 平均的な量的特性の場合:
どこ? 2 – 定量的特性の分散の平均値。
2) 共有の場合 (代替属性):
それでは、母集団における形質の分散はどのようなものでしょうか? 2 は正確にはわかっていませんが、実際には、大数の法則に基づいてサンプル母集団に対して計算された分散 S 2 の値が使用されます。これによれば、サンプルサイズが十分に大きいサンプル母集団は、分散 S 2 を非常に正確に再現します。一般人口の特徴。
ランダムリサンプリングの平均サンプリング誤差の計算式は次のとおりです。 のために 平均サイズ量的特性: 一般的な分散は、次の関係による選択的分散を通じて表現されます。
ここで、S 2 は分散値です。
機械的サンプリング– これは、一般集団からサンプル集団にユニットを選択することであり、中立的な基準に従って均等なグループに分割されます。 これは、そのような各グループから 1 つのユニットだけがサンプルとして選択されるように実行されます。
機械的サンプリングでは、調査対象となる統計母集団のユニットをあらかじめ一定の順序で並べておき、その後、一定の間隔で所定の数のユニットを機械的に選択します。 この場合、母集団の間隔のサイズはサンプル比率の逆数値に等しくなります。
十分なとき 人口が多い機械的選択は結果の精度の点で自己ランダムに近いため、機械的サンプリングの平均誤差を求めるには、自己ランダム非反復サンプリングの式が使用されます。
異質な集団からユニットを選択するには、いわゆる典型サンプルが使用されます。これは、研究対象の指標が依存する特性に従って、一般集団のすべてのユニットをいくつかの質的に均質で類似したグループに分類できる場合に使用されます。
次に、純粋にランダムなサンプルまたは機械的なサンプルを使用して、各典型的なグループからサンプル母集団へのユニットの個別の選択が実行されます。
サンプルサンプリングは通常、複雑な統計母集団を調査するときに使用されます。
通常のサンプリングでは、より正確な結果が得られます。 一般母集団の型付けにより、そのようなサンプルの代表性、つまりサンプル内の各類型グループの表現が保証され、平均サンプリング誤差に対するグループ間の分散の影響を排除することができます。 したがって、典型的なサンプルの平均誤差を決定する場合、グループ内の分散の平均が変動の指標として機能します。
連続サンプリングには、そのようなグループ内のすべてのユニットを例外なく観察の対象にするために、同じグループの一般集団からランダムに選択することが含まれます。
グループ (系列) 内ではすべてのユニットが例外なく検査されるため、平均サンプリング誤差 (等しい系列を選択した場合) はグループ間 (系列間) の分散のみに依存します。
4. サンプル結果を一般の人々に広める方法
標本観察の最終目標は、標本結果に基づく母集団の特徴です。
サンプリング方法は、特定のサンプル指標に従って母集団の特徴を取得するために使用されます。 研究の目的に応じて、これは一般集団のサンプル指標を直接再計算するか、補正係数を計算することによって行われます。
直接再計算の方法は、サンプルシェアの指標を使用することです。 wまたは平均的な バツサンプリング誤差を考慮して、一般集団に適用します。
補正係数法は、サンプリング法の目的が継続会計の結果を明らかにすることである場合に使用されます。 この方法は、毎年行われる家畜の人口調査からのデータを明確にするために使用されます。
サンプリング法の理論では、代表性を確保するためにさまざまな選択方法やサンプリングの種類が開発されてきました。 下 選択方法母集団からユニットを選択する手順を理解する。 選択方法には、繰り返しと非繰り返しの 2 つがあります。 で 繰り返されたサンプリングでは、ランダムに選択された各ユニットが調査後に一般集団に戻され、その後の選択により再びサンプルに含めることができます。 この選択方法は「返球」スキームに基づいており、母集団の各単位のサンプルに含まれる確率は、選択された単位の数に関係なく変化しません。 で 繰り返し可能なサンプリングでは、ランダムに選択された各ユニットは、検査後に一般集団に戻されません。 この選択方法は「返球しない」スキームに基づいており、一般集団の各単位のサンプルに含まれる確率は、選択が進むにつれて増加します。
サンプル母集団を形成する方法論に応じて、次の主な方法論が区別されます。 サンプリングの種類:
実際にはランダムです。
機械的;
典型的(層別、ゾーン化)。
シリアル (ネスト);
組み合わせた;
多段階。
多相。
相互浸透する。
実際にはランダムサンプリング科学的原則とランダムな選択ルールに厳密に従って形成されます。 本当にランダムなサンプルを取得するには 人口サンプリング単位に厳密に分割され、十分な数の単位がランダムな繰り返しまたは非繰り返しの順序で選択されます。
ランダムな順序は、くじ引きのようなものです。 実際には、乱数の特別なテーブルを使用する場合に最もよく使用されます。 たとえば、1587 ユニットを含む母集団から 40 ユニットを選択する場合、1587 未満の 40 個の 4 桁の数字がテーブルから選択されます。
ランダムサンプル自体が繰り返しサンプルとして構成されている場合、標準誤差は式 (6.1) に従って計算されます。 非反復サンプリング法では、標準誤差を計算する式は次のようになります。
ここで、1 – n/ N– 一般集団におけるサンプルに含まれなかったユニットの割合。 このシェアは常にあるので、 1未満の場合、他の条件が等しい場合、非繰り返し選択中の誤差は、繰り返し選択中の誤差よりも常に小さくなります。 非反復選択は、反復選択よりも整理しやすく、より頻繁に使用されます。 ただし、非反復サンプリング中の標準誤差の値は、より簡単な式 (5.1) を使用して決定できます。 このような置き換えは、サンプルに含まれていない一般母集団のユニットの割合が大きく、したがって値が 1 に近い場合に可能です。
乱数表を使用する場合、一般母集団のすべての単位に番号を付ける必要があるため、無作為選択のルールに厳密に従ってサンプルを作成することは実際には非常に困難であり、場合によっては不可能です。 多くの場合、母集団が非常に大きいため、このような予備作業を行うのは非常に困難で非現実的です。そのため、実際には、厳密には無作為ではない他のタイプのサンプルが使用されます。 ただし、これらはランダム選択の条件に最大限に近似するように編成されています。
きれいなとき 機械的サンプリングユニットの一般集団全体は、まず第一に、研究対象の形質に関して中立的な順序、たとえばアルファベット順に編集された選択ユニットのリストの形式で提示されなければなりません。 次に、選択ユニットのリストが、選択されるユニットの数と同じ数の部分に分割されます。 次の前に 確立されたルール、研究対象の特性の変動に関係しないため、リストの各部分から 1 つのユニットが選択されます。 このタイプのサンプリングでは常にランダムなサンプリングが行われるとは限らず、結果として得られるサンプルには偏りがある可能性があります。 これは、第一に、一般集団における単位の順序には非ランダムな性質の要素がある可能性があるという事実によって説明されます。 第二に、基準点が誤って設定されている場合、母集団の各部分からサンプリングを行うと、バイアス誤差が生じる可能性があります。 ただし、実際には、無作為サンプルよりも機械サンプルを組織する方が簡単であり、サンプル調査を行う場合には、このタイプのサンプリングが最もよく使用されます。 機械的サンプリングの標準誤差は、実際のランダムな非反復サンプリングの公式によって決定されます (6.2)。
典型的な(ゾーン化された、階層化された)サンプル 2 つの目標があります:
研究者が興味を持っている特徴に従って、一般集団の対応する典型的なグループがサンプル内で確実に表現されるようにする。
サンプル調査結果の精度を高めます。
典型的なサンプルでは、その形成が始まる前に、ユニットの一般集団が典型的なグループに分類されます。 同時にとても 大事なポイントは 正しい選択グループ化の標識。 選択された典型的なグループには、同じ数の選択単位が含まれていても、異なる数の選択単位が含まれていてもよい。 前者の場合、サンプル母集団は各グループからの選択の均等な割合で形成され、後者の場合、一般母集団におけるその割合に比例した割合で形成されます。 サンプルが等しい割合の選択で形成された場合、それは本質的に、それぞれが典型的なグループである、より小さな母集団からの厳密にランダムなサンプルの数と同等になります。 各グループからの選択は、ランダム(繰り返しまたは非繰り返し)または機械的な方法で実行されます。 典型的なサンプルでは、選択の割合が等しい場合と異なる場合の両方で、サンプル母集団内の各典型的なグループの代表が必須であるため、研究対象の特性のグループ間変動が結果の精度に及ぼす影響を排除することができます。が確保されています。 標本の標準誤差は総分散の量に依存しますか? 2, そしてグループ分散の平均値?i 2 。 他のすべての条件が等しい場合、グループ分散の平均は常に合計分散よりも小さいため、典型的なサンプルの標準誤差は、ランダムなサンプル自体の標準誤差よりも小さくなります。
典型的なサンプルの標準誤差を決定する場合、次の式が使用されます。
選択方法を繰り返す場合

非反復的な選択方法の場合:

– サンプル母集団のグループ分散の平均。
シリアル(クラスター)サンプリング- これは、調査対象のユニットではなく、ユニットのグループ (シリーズ、ネスト) がランダムな順序で選択される場合のサンプル母集団の形成の一種です。 選択したシリーズ (ネスト) 内のすべてのユニットが検査されます。 シリアルサンプリングは、個々のユニットをサンプリングするよりも実際に組織化して実行するのが簡単です。 しかし、このタイプのサンプリングでは、第一に、各系列の代表性が保証されず、第二に、調査結果に対する調査特性の系列間変動の影響が排除されません。 この変動が大きい場合、代表性のランダム誤差の増加につながります。 サンプルの種類を選択するとき、研究者はこの状況を考慮する必要があります。 シリアル サンプリングの標準誤差は、次の式で求められます。
繰り返し選択方式では、

ここで? はサンプル母集団の系列間分散です。 r– 選択されたシリーズの数;
非反復的な選択方法を使用する場合 -

どこ R– 母集団内の系列の数。
実際には、サンプル調査の目的や目的、組織や実施の可能性に応じて、特定の方法やサンプルの種類が使用されます。 ほとんどの場合、選択方法とサンプリングの種類を組み合わせて使用されます。 このようなサンプルは次のように呼ばれます。 組み合わせた。組み合わせ可能です さまざまな組み合わせ: 機械的サンプリングと連続サンプリング、典型的と機械的、連続的と実際にランダムなど。組み合わせサンプリングは、調査を組織し実施するための人件費と金銭的コストを最小限に抑え、最大の代表性を確保するために使用されます。
結合サンプルの場合、サンプルの標準誤差は各段階の誤差で構成され、対応するサンプルの二乗誤差の合計の平方根として決定できます。 したがって、結合サンプル中に機械サンプルと典型的なサンプルを組み合わせて使用した場合、標準誤差は次の式で決定できます。

どこ?1と? 2 はそれぞれ機械的サンプルと典型的なサンプルの標準誤差です。
特殊性 多段階抽出選択の段階に従って、サンプル母集団が徐々に形成されるという事実にあります。 第1段階では、所定の選択方法および種類の選択を使用して、第1段階ユニットが選択される。 第 2 段階では、サンプルに含まれる第 1 段階の各ユニットから、第 2 段階のユニットが選択されます。段階の数は 2 つ以上でも構いません。 最終段階では、サンプル母集団が形成され、その単位が調査の対象となります。 たとえば、家計のサンプル調査の場合、最初の段階では国の領土主題が選択され、2番目の段階では選択された地域の地区が選択され、3番目の段階ではそれぞれの地域が選択されます。 自治体形成企業や組織が選択され、最終的に第 4 段階で選択された企業から家族が選択されます。
このようにして、最終段階でサンプル母集団が形成されます。 多段階サンプリングは他のタイプに比べて柔軟性が高くなりますが、一般に同じサイズの単一段階サンプルよりも生成される結果の精度が低くなります。 ただし、これには重要な利点が 1 つあります。それは、多段階選択のためのサンプリング フレームは、サンプルに含まれるユニットに対してのみ各段階で構築する必要があるということです。これは非常に重要です。サンプリングフレームを作りました。
異なるサイズのグループに対する多段階サンプリングの標準サンプリング誤差は、次の式で求められます。

ここで?1、?2、?3 , ... – さまざまな段階での標準誤差。
n1、n2, n3 , .. 。 – 対応する選択段階でのサンプルの数。
グループの体積が等しくない場合、理論的にはこの式は使用できません。 しかし、すべての段階での選択の合計割合が一定である場合、実際には、この式を使用した計算によって誤差値が歪むことはありません。
エッセンス 多相サンプリングこれは、最初に形成されたサンプル母集団に基づいてサブサンプルが形成され、このサブサンプルから次のサブサンプルが形成されるという事実にあります。最初のサンプル母集団は最初の段階を表し、そこからのサブサンプルは 2 番目の段階を表します。次のような場合には、多相サンプリングを使用することをお勧めします。
勉強のため さまざまな兆候必要なサンプルサイズが等しくない。
研究された特性の変動性は同じではなく、必要な精度も異なります。
最初のサンプル フレーム (最初のフェーズ) では、すべてのユニットについてそれほど詳細ではない情報を収集する必要があり、後続の各フェーズでは、ユニットについてより詳細な情報を収集する必要があります。
マルチフェーズ サンプリングの疑いのない利点の 1 つは、最初のフェーズで取得した情報を後続のフェーズの追加情報として使用できること、第 2 フェーズの情報を後続のフェーズの追加情報として使用できることなどです。このような情報の使用が増加します。サンプル調査の結果の正確さ。
多相サンプリングを構成する場合、さまざまな方法と選択の種類を組み合わせて使用できます (通常のサンプリングと機械的サンプリングなど)。 多相選択は多段階選択と組み合わせることができます。 各段階で、サンプリングは多段階で行うことができます。
多相サンプリングの標準誤差は、そのサンプル母集団が形成された選択方法とサンプリングの種類の式に従って、各相ごとに個別に計算されます。
相互貫入発掘- 同じ方法および種類で収集された、同じ集団からの 2 つ以上の独立したサンプル。 短期間でサンプル調査の予備結果を得る必要がある場合は、相互貫入サンプルを使用することをお勧めします。 クロスサンプリングは調査結果を評価するのに効果的です。 独立したサンプルで結果が同じであれば、これはサンプル調査データの信頼性を示します。 クロスサンプリングは、異なる研究者に異なるサンプルを調査させることで、異なる研究者の研究をテストするために使用される場合があります。
相互貫入サンプルの標準誤差は、典型的な比例サンプル (5.3) と同じ式によって決定されます。 相互貫入サンプルは他のタイプと比較して、より多くの労力と費用が必要となるため、研究者はサンプル調査を設計する際にこれを考慮する必要があります。
エラーを制限する さまざまな方法でサンプリングの選択と種類は式によって決まりますか? = て?、どこ? は対応する標準誤差です。
事象確率の区間推定。 純粋にランダムなサンプリング方法を使用してサンプル サイズを計算するための式。関心のある事象の確率を決定するために、サンプリング方法を使用します。 n独立した実験。それぞれのイベントでイベント A が発生する (または発生しない) (確率 R各実験におけるイベント A の発生は一定です)。 次に、イベントの発生の相対頻度 p* あ一連の nテストは確率の点推定値として取得されます pイベントの発生 あ別の裁判で。 この場合、値 p* は サンプルシェア イベントの発生 あ、そして、p - 一般株式 .
中心極限定理 (Moivre-Laplace の定理) の帰結により、サンプル サイズが大きいイベントの相対頻度は、パラメーター M(p*)=p および M(p*)=p で正規分布していると考えることができます。
したがって、n>30 の場合、一般シェアの信頼区間は次の式を使用して構築できます。

ここで、u cr は、与えられた信頼確率 γ を考慮して、ラプラス関数のテーブルから求められます: 2Ф(u cr)=γ。
サンプルサイズが小さい n≤30 の場合、最大誤差 ε はスチューデント分布表から決定されます。 ![]() ここで、tcr =t(k; α)、自由度の数 k=n-1、確率 α=1-γ (両側領域)。
ここで、tcr =t(k; α)、自由度の数 k=n-1、確率 α=1-γ (両側領域)。
選択がランダムに繰り返される方法で実行された場合 (一般母集団は無限です)、式は有効ですが、そうでない場合は、選択が繰り返されないように調整する必要があります (表)。
一般シェアの平均サンプリング誤差
| 人口 | 無限 | 最終巻 N |
| 選択の種類 | 繰り返し | 繰り返しのない |
| 平均サンプリング誤差 |
純粋にランダムなサンプリング方法を使用してサンプル サイズを計算するための式
| 選定方法 | サンプルサイズを決定するための式 | ||
| 平均的な | 共有用 | ||
| 繰り返し | |||
| 繰り返しのない | |||
一般的な共有の問題
「信頼区間は指定された p0 値をカバーしますか?」という質問に対して、 - 統計的仮説 H 0:p=p 0 をチェックすることで答えることができます。 実験はベルヌーイ検定スキーム (独立、確率) に従って実行されると仮定します。 pイベントの発生 あは一定です)。 体積サンプル別 nイベント A の発生の相対頻度 p * を決定します。 メートル- イベントの発生数 あ一連の nテスト。 仮説 H 0 を検証するには、サンプル サイズが十分に大きく、標準正規分布を持つ統計が使用されます (表 1)。表 1 - 一般的なシェアに関する仮説
仮説 | H 0:p=p 0 | H 0:p 1 =p 2 |
| 仮定 | ベルヌーイテスト回路 | ベルヌーイテスト回路 |
| 推定値の例 | 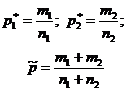 |
|
| 統計 K |  |  |
| 統計分布 K | 標準ノーマル N(0,1) |
例その1。 同社の経営陣は、ランダムな反復サンプリングを使用して、従業員 900 名を対象にサンプル調査を実施しました。 回答者のうち女性は270名でした。 会社のチーム全体における女性の真の割合をカバーする確率 0.95 の信頼区間を構築します。
解決。 条件によると、女性のサンプル割合は(全回答者に占める女性の相対頻度)となります。 選択が繰り返され、サンプル サイズが大きい (n=900) ため、最大サンプリング誤差は次の式で求められます。 ![]()
u cr の値は、関係 2Ф(u cr) = γ、つまり、ラプラス関数の表から求められます。 ![]() ラプラス関数 (付録 1) は、u cr =1.96 で値 0.475 をとります。 したがって、限界誤差は、
ラプラス関数 (付録 1) は、u cr =1.96 で値 0.475 をとります。 したがって、限界誤差は、 ![]() および望ましい信頼区間
および望ましい信頼区間
(p – ε、p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
したがって、確率 0.95 で、会社のチーム全体における女性の割合が 0.12 ~ 0.48 の範囲にあることを保証できます。
例その2。 駐車場の所有者は、駐車場が 80% 以上埋まっている場合、その日は「幸運」であると考えます。 この年、駐車場の検査は 40 件実施され、そのうち 24 件は「合格」でした。 確率 0.98 で、年間の「幸運な」日の真の割合を推定するための信頼区間を見つけます。
解決。 「幸運な」日のサンプル割合は次のとおりです。
ラプラス関数のテーブルを使用して、与えられた値に対する u cr の値を見つけます。
信頼確率
Ф(2.23) = 0.49、ucr = 2.33。
選択が反復的ではない (つまり、2 つのチェックが同じ日に実行されなかった) と考えると、限界エラーが見つかります。 ![]()
ここで、n = 40、N = 365 (日)。 ここから ![]()
一般シェアの信頼区間: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
確率 0.98 では、年間の「幸運な」日の割合は 0.43 ~ 0.77 の範囲になると予想できます。
例その3。 バッチ内の 2500 個の製品を検査した結果、400 個の製品が最高グレードであることがわかりましたが、n ~ m の製品はそうではありませんでした。 精度 0.01 で最高グレードの割合を 95% の信頼度で決定するには、いくつの製品をチェックする必要がありますか?
再選択のためのサンプルサイズを決定するための公式を使用して解決策を探します。
Ф(t) = γ/2 = 0.95/2 = 0.475、ラプラス表によるこの値は t=1.96 に対応します。
サンプル比率 w = 0.16; サンプリング誤差 ε = 0.01
例その4。 製品が規格に適合する確率が少なくとも 0.97 であれば、製品のバッチは合格となります。 テストされたバッチから無作為に選択された 200 個の製品のうち、193 個が基準を満たすことが判明しました。 有意水準 α=0.02 でバッチを受け入れることは可能ですか?
解決。 主仮説と対立仮説を立ててみましょう。
H 0:p=p 0 =0.97 - 一般シェアは不明 p指定された値 p 0 =0.97 に等しい。 条件に関しては、検査されたバッチの部品が規格に適合する確率は 0.97 に等しくなります。 それらの。 製品のロットを受け入れることができます。
H1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
観測された統計値 K(表) 与えられた値に対して計算 p 0 =0.97、n=200、m=193

等式からラプラス関数の表から臨界値を求めます。
![]()
条件によれば、α = 0.02 であるため、F(Kcr) = 0.48、Kcr = 2.05 となります。 クリティカル領域は左側、つまり左側です。 間隔 (-∞;-K kp)= (-∞;-2.05) です。 観測値 K obs = -0.415 は臨界領域に属さないため、この有意水準では主仮説を棄却する理由はありません。 一括での商品もお受けできます。
例その5。 2 つの工場が同じ種類の部品を生産しています。 品質を評価するために、これらの工場の製品からサンプルを採取したところ、次のような結果が得られました。 第 1 工場で選ばれた 200 個の製品のうち 20 個が不良品で、第 2 工場で選ばれた 300 個の製品のうち 15 個が不良品でした。
有意水準 0.025 で、これらの工場で製造された部品の品質に有意な差があるかどうかを調べます。
条件によれば、α = 0.025 であるため、F(Kcr) = 0.4875、Kcr = 2.24 となります。 両側代替の場合、許容値の範囲は (-2.24;2.24) の形式になります。 観測値 K obs =2.15 はこの範囲内に収まります。 この重要性レベルでは、主要な仮説を拒否する理由はありません。 工場は同じ品質の製品を生産します。
プラン:
1. 数理統計の問題。
2. サンプルの種類。
3. 選択方法。
4. サンプルの統計的分布。
5. 経験的分布関数。
6. ポリゴンとヒストグラム。
7. バリエーションシリーズの数値特性。
8. 分布パラメータの統計的推定。
9. 分布パラメータの区間推定。
1. 数理統計の問題点と手法
数学統計 科学的および実用的な目的で統計的観察データの結果を収集、分析、処理する方法に特化した数学の一分野です。
均質なオブジェクトのセットを、これらのオブジェクトを特徴づける定性的または定量的な特徴に関して研究する必要があるとします。 たとえば、部品のバッチがある場合、部品の標準は定性的な兆候として機能し、部品の制御されたサイズは定量的な兆候として機能します。
場合によっては、完全な研究が行われることもあります。 各オブジェクトの必要な特性が検査されます。 実際には、完全な調査が使用されることはほとんどありません。 たとえば、母集団に非常に多くの物体が含まれている場合、包括的な調査を実施することは物理的に不可能です。 物体の調査がその破壊を伴う場合、または多額の材料費が必要な場合、完全な調査を実施することは意味がありません。 このような場合、限られた数のオブジェクトが母集団全体 (サンプル母集団) からランダムに選択され、研究の対象となります。
数理統計の主なタスクは、目的に応じてサンプルデータを使用して母集団全体を研究することです。 集団の確率的特性の研究: 分布法則、数値特性など。 不確実な状況下で経営上の意思決定を行うため。
2. サンプルの種類
人口 サンプルの作成元となるオブジェクトのセットです。
サンプル母集団(サンプル) ランダムに選択されたオブジェクトのコレクションです。
人口の体積 このコレクション内のオブジェクトの数です。 人口の規模は次のように表されます。 N、選択的 – n。
例:
1000 個の部品のうち 100 個の部品が検査のために選択された場合、一般母集団の体積 N = 1000、およびサンプルサイズ n = 100。
サンプルを選択するには 2 つの方法があります。オブジェクトを選択して観察した後、それを母集団に戻す場合と戻さない場合があります。 それ。 サンプルは反復サンプルと非反復サンプルに分けられます。
繰り返す呼ばれた サンプル、選択されたオブジェクト (次のオブジェクトを選択する前) が母集団に返されます。
繰り返しのない呼ばれた サンプル、選択されたオブジェクトは母集団に返されません。
実際には、通常、繰り返しのないランダムサンプリングが使用されます。
標本データに基づいて対象母集団の特徴を十分な自信を持って判断できるようにするには、標本オブジェクトがそれを正確に表現している必要があります。 サンプルは母集団の割合を正確に表す必要があります。 サンプルは次のとおりです。 代表者(代表者)。
大数の法則により、サンプルがランダムに実行された場合、サンプルは代表的なものになると主張できます。
母集団のサイズが十分に大きく、サンプルがこの母集団のごく一部のみを構成する場合、反復サンプルと非反復サンプルの区別はなくなります。 制限されたケースでは、無限の母集団が考慮され、サンプルのサイズが有限である場合、この差はなくなります。
例:
アメリカの雑誌「リテラリー・レビュー」は、統計的手法を用いて、1936 年に予定されているアメリカ大統領選挙の結果に関する予測の研究を実施しました。 このポストの候補者は F.D. ルーズベルトとA.M.ランドン。 電話帳は、研究対象となったアメリカ人一般の情報源として使用されました。 このうち400万件の住所が無作為に選ばれ、同誌の編集者らが大統領候補者に対する態度を表明するよう求めるはがきを送った。 調査結果を処理した後、同誌はランドンが次の選挙で大差で勝利するという社会学的予測を発表した。 そして…私は間違っていました:ルーズベルトが勝ちました。
この例は、代表的ではないサンプルの例と考えることができます。 実際のところ、20 世紀前半の米国では、ランドンの意見を支持する裕福な層だけが電話を持っていました。
3. 選定方法
実際にはさまざまな選択方法が使用されますが、次の 2 つのタイプに分類できます。
1. 選択には母集団をいくつかの部分に分割する必要はありません (a) 単純でランダムな非反復; b) 単純なランダムな繰り返し).
2. 選択。母集団をいくつかの部分に分割します。 (A) 典型的な選択; b) 機械的選択; V) シリアル 選択).
単純なランダム 彼らはこれをそう呼んでいます 選択、オブジェクトが母集団全体から一度に 1 つずつ (ランダムに) 抽出されます。
典型的な呼ばれた 選択、そこではオブジェクトが母集団全体からではなく、その「典型的な」部分のそれぞれから選択されます。 たとえば、部品が複数の機械で製造される場合、選択はすべての機械で製造された部品のセット全体からではなく、各機械の製品から個別に行われます。 この選択は、調査対象の形質が一般集団のさまざまな「典型的な」部分で著しく異なる場合に使用されます。
機械式呼ばれた 選択この方法では、一般母集団が、サンプルに含めるべきオブジェクトの数と同じ数のグループに「機械的に」分割され、各グループから 1 つのオブジェクトが選択されます。 たとえば、機械で製造された部品の 20% を選択する必要がある場合、5 番目ごとに部品が選択されます。 パーツの 5% を選択する必要がある場合は、20 番目ごとなど。 このような選択では、サンプルの代表性が保証されない場合があります (20 個ごとに研磨されたローラーが選択され、選択後すぐにカッターが交換された場合、鈍いカッターで回転されたすべてのローラーが選択されます)。
シリアル呼ばれた 選択、一度に 1 つずつではなく、継続的な調査の対象となる「シリーズ」でオブジェクトが一般集団から選択されます。 たとえば、製品が多数の自動機械で製造されている場合、少数の機械の製品のみが総合的な検査の対象となります。
実際には、上記の方法を組み合わせた複合選択がよく使用されます。
4. サンプルの統計的分布
一般母集団からサンプルを抽出し、その値を x 1 とすると、–1 回観察、x 2 -n 2 回、... x k - n k 回観察。 n= n 1 +n 2 +...+n k – サンプルサイズ。 観測値呼ばれています オプション、昇順で書かれたオプションのシーケンスは次のとおりです。 バリエーションシリーズ。 観測値の数呼ばれています 周波数(絶対周波数)、およびサンプルサイズとの関係- 相対周波数または 統計的確率。
変異の数が多い場合、またはサンプルが連続母集団から取得された場合、変異系列は個々の点の値からではなく、母集団内の値の間隔から編集されます。 このようなバリエーションシリーズを次のように呼びます。 間隔。間隔の長さは等しくなければなりません。
統計的サンプル分布 オプションとそれに対応する頻度または相対頻度のリストと呼ばれます。
統計分布は、一連の間隔とそれに対応する頻度 (この値の間隔内にある頻度の合計) として指定することもできます。
周波数の点変化系列は、次の表で表すことができます。
| x i |
×1 |
×2 |
… |
Xのk |
| 私は |
n1 |
n2 |
… |
ンク |
同様に、相対周波数の点変化系列を想像することができます。
さらに:
例:
あるテキスト X の文字数は 1000 であることが判明しました。最初に見つかった文字は文字「i」、2 番目は文字「i」、3 番目は文字「a」、4 番目は「」でした。ゆ」。 次に、「o」、「e」、「u」、「e」、「s」の文字が続きました。
それらが占める位置をそれぞれアルファベットで書き留めてみましょう: 33、10、1、32、16、6、21、31、29。
これらの数値を昇順に並べると、1、6、10、16、21、29、31、32、33 のバリエーション シリーズが得られます。
テキスト内の文字の出現頻度: 「a」 - 75、「e」 - 87、「i」 - 75、「o」 - 110、「u」 - 25、「s」 - 8、「e」 - 3 、「ゆ」」 - 7、「い」 - 22。
一連の周波数の点変化を作成しましょう。
例:
規定量サンプリング頻度分布 n = 20。
相対周波数の点変化系列を作成します。
| x i |
2 |
6 |
12 |
| 私は |
3 |
10 |
7 |
解決:
相対周波数を求めてみましょう。
| x i |
2 |
6 |
12 |
| 私は |
0,15 |
0,5 |
0,35 |
区間分布を作成する場合、区間の数または各区間のサイズを選択するためのルールがあります。 ここでの基準は最適な比率です。間隔の数が増えると代表性は向上しますが、データ量とその処理時間が増加します。 違い x max - x min の最大値と最小値の間のオプションが呼び出されます 範囲サンプル。
間隔の数を数えるには k 通常、経験的なスタージェスの公式が使用されます (最も近い便利な整数に丸めることを意味します)。 k = 1 + 3.322 log n。
したがって、それぞれの間隔の大きさは、 h 次の式を使用して計算できます:
5. 経験的分布関数
一般集団からのサンプルを考えてみましょう。 量的特性 X の統計的頻度分布を既知にし、次の表記を導入しましょう: n x– x 未満の特性値が観察された観察の数。 n – 観測値の総数 (サンプルサイズ)。 イベント X の相対頻度<х равна nx/n。 x が変化すると、相対周波数も変化します。つまり、 相対頻度n x /n- x の関数があります。 なぜなら それは経験的に発見され、そのときそれは経験的と呼ばれます。
経験的分布関数(標本分布関数) 関数を呼び出す、各 x についてイベント X の相対頻度を決定します。<х.
ここで、 は x より小さいオプションの数です。
n - サンプルサイズ。
サンプルの経験的分布関数とは対照的に、母集団の分布関数 F(x) は次のように呼ばれます。 理論的な分布関数.
経験的分布関数と理論的分布関数の違いは、理論的関数 F (x) が事象 X の確率を決定することです。
それ。 一般母集団の理論的 (積分) 分布関数を近似するには、サンプルの経験的分布関数を使用することをお勧めします。
F*(x)すべてのプロパティを持っています F(x)。
1. 価値観 F*(x)区間に属します。
2. F*(x) は非減少関数です。
3. が最小のオプションの場合、x に対して F*(x) = 0 となります。 < ×1; x k が最大のオプションの場合、x > x k の場合、F*(x) = 1 になります。
それらの。 F*(x) F(x) を推定するのに役立ちます。
サンプルが変分系列で与えられる場合、経験関数は次の形式になります。
経験関数のグラフは累積と呼ばれます。
例:
指定された標本分布から経験関数をプロットします。
解決:
サンプルサイズ n = 12 + 18 +30 = 60。最小のオプションは 2、つまり xで <
2. イベントX<6,
(x 1
= 2) наблюдалось 12 раз, т.е. F*(x)=12/60=0.2 2時に <
バツ <
6. イベントX<10, (x 1 =2, x 2 = 6) наблюдалось 12 + 18 = 30 раз, т.е.F*(x)=30/60=0,5
при 6 <
バツ <
10. なぜなら x=10 が最大のオプションである場合、 F*(x) = 1 x>10の場合。 目的の経験関数は次の形式になります。
累計:
Cumulate を使用すると、グラフィック表示された情報を理解することができます。たとえば、次のような質問に答えることができます。「属性の値が 6 未満または 6 以上であった観測値の数を決定します。F*(6) =0.2」 「すると、観察された特性の値が 6 未満であった観察の数は 0.2* となります。 n = 0.2*60 = 12。観察された特性の値が少なくとも 6 であった観察の数は、(1-0.2)* に等しくなります。 n = 0.8*60 = 48。
区間変動系列が与えられた場合、経験的分布関数をコンパイルするには、点変動系列と同様に区間の中点が見つかり、そこから経験的分布関数が取得されます。
6. ポリゴンとヒストグラム
わかりやすくするために、多項式とヒストグラムなどのさまざまな統計分布グラフが作成されています。
周波数範囲 -これは破線であり、そのセグメントは点 ( x 1 ; n 1 )、( x 2 ; n 2 )、…、( x k ; n k ) を接続します。ここで、 はオプション、 は対応する周波数です。
相対周波数多角形 -これは破線であり、そのセグメントは点 ( x 1 ; w 1 )、( x 2 ; w 2 )、…、( x k ; w k ) を接続します。ここで、 x i はオプション、 w i は次の値に対応する相対周波数です。彼ら。
例:
指定されたサンプリング分布から相対周波数の多項式を構築します。
解決:
連続特性の場合、特性のすべての観測値が含まれる区間を長さ h のいくつかの部分区間に分割し、各部分区間ごとに n i を求めるヒストグラムを作成することをお勧めします。 i 番目の区間に該当するバリアントの頻度の合計。 (たとえば、人の身長や体重を測定するときは、連続的な属性を扱います)。
頻度ヒストグラム -これは、長さ h の部分間隔を底辺とし、高さが比率 (周波数密度) に等しい長方形からなる階段状の図形です。
四角 i 番目の部分長方形は、i 番目の間隔バリアントの度数の合計に等しくなります。 周波数ヒストグラムの面積は、すべての周波数の合計に等しくなります。 サンプルサイズ。
例:
電気ネットワーク内の電圧変化 (ボルト単位) の結果が表示されます。 電圧値が次の場合、変動系列を作成し、多角形と周波数ヒストグラムを作成します: 227、215、230、232、223、220、228、222、221、226、226、215、218、220、 216、220、225、212、217、220。
解決:
バリエーションシリーズを作ってみましょう。 n = 20、x min =212、x max =232 となります。
スタージェスの公式を適用して間隔の数を計算してみましょう。
周波数の間隔変動系列は次の形式になります。
|
|
周波数密度 |
|
212-21 6 |
0,75 |
|
|
21 6-22 0 |
0,75 |
|
|
220-224 |
1,75 |
|
|
224-228 |
||
|
228-232 |
0,75 |
頻度ヒストグラムを作成しましょう。
まず間隔の中点を見つけて、周波数多角形を構築しましょう。
相対頻度ヒストグラム長方形からなる階段状の図形と呼ばれ、その底辺は長さ h の部分間隔であり、高さは比率 w に等しい 私/h (相対周波数密度)。
四角 i 番目の部分長方形は、i 番目の区間に入るバリアントの相対頻度に等しくなります。 それらの。 相対度数のヒストグラムの面積は、すべての相対度数の合計に等しくなります。 ユニット。
7. 変動系列の数値特性
一般母集団と標本母集団の主な特徴を考えてみましょう。
一般中等教育一般集団の特性値の算術平均と呼ばれます。
さまざまな値の場合、x 1、x 2、x 3、...、x n。 ボリューム N の一般集団の特徴は次のとおりです。
特性値に対応する周波数 N 1 +N 2 +…+N k =N がある場合、
標本平均はサンプル母集団の特性値の算術平均と呼ばれます。
特性値に対応する周波数 n 1 +n 2 +…+n k = n がある場合、
例:
サンプルのサンプル平均を計算します: x 1 = 51.12; x 2 = 51.07; x 3 = 52.95; x 4 = 52.93; x 5 = 51.1; x 6 = 52.98; × 7 = 52.29; × 8 = 51.23; × 9 = 51.07; × 10 = 51.04。
解決:
一般的な差異は、一般平均からの一般集団の特性 X の値の二乗偏差の算術平均と呼ばれます。
体積 N の一般母集団の特性のさまざまな値 x 1 、 x 2 、 x 3 、...、 x N について、次のようになります。
特性値に対応する周波数 N 1 +N 2 +…+N k =N がある場合、
一般的な標準偏差 (標準)一般分散の平方根と呼ばれます
サンプルの分散は、特性の観測値の平均値からの偏差の二乗の算術平均と呼ばれます。
ボリューム n のサンプル母集団特徴のさまざまな値 x 1 、 x 2 、 x 3 、...、 x n については、次のようになります。
特性値に対応する周波数 n 1 +n 2 +…+n k = n がある場合、
サンプル標準偏差 (標準)は標本分散の平方根と呼ばれます。
例:
サンプル母集団は分布表によって指定されます。 標本の分散を求めます。
解決:
定理: 分散は、属性値の平均二乗と全体の平均の二乗の差に等しくなります。
例:
この分布の分散を求めます。
解決:
8. 分布パラメータの統計的推定
特定のサンプルを使用して一般集団を研究するとします。 この場合、未知パラメータ Q の推定値となる近似値のみを取得することができます。 明らかに、推定値はサンプルごとに異なる場合があります。
統計的評価Q*理論的分布の未知のパラメーターは、観測されたサンプル値に応じて関数 f と呼ばれます。 サンプルから未知のパラメータを統計的に推定するタスクは、研究者にとって未知の実際のパラメータの値の最も正確な近似値を与える、利用可能な統計的観察データから関数を構築することです。
統計的推定値は、その表示方法 (数値または間隔) に応じて、点と間隔に分けられます。
ポイントは統計的な推定値ですパラメータ Q *=f (x 1, x 2, ..., x n) の 1 つの値によって決定される理論的分布のパラメータ Q、ここで×1、×2、 ..., x n- 特定のサンプルの定量的特性 X に関する経験的観察の結果。
異なるサンプルから得られるこのようなパラメータ推定値は、ほとんどの場合、互いに異なります。 絶対差 /Q *-Q / と呼ばれます サンプリング(推定)誤差。
統計的推定値が推定対象のパラメータに関して信頼できる結果を生み出すためには、統計的推定値は偏りがなく、効率的で、一貫性がなければなりません。
ポイント推定、推定されたパラメータと等しい(等しくない)数学的期待値はと呼ばれます。 置き換えられていない(置き換えられている)。 M(Q *)=Q 。
差分M( Q *)-Q が呼び出されます 偏りまたは系統誤差。 不偏推定の場合、バイアスは 0 です。
効果的 評価 Q *、与えられたサンプル サイズ n に対して可能な最小の分散を持つもの: D min(n = 定数)。 効果的な推定量は、他の不偏かつ一貫した推定量と比較して最小の分散を持ちます。
裕福なこれを統計と呼ぶ 評価 Q *、これは n に相当します推定パラメータに対する確率の傾向 Q 、つまり サンプルサイズの増加に伴い n 推定値は確率的にパラメータの真の値に近づく傾向があります Q.
一貫性の要件は大数の法則と一致しています。つまり、研究対象のオブジェクトに関する初期情報が多ければ多いほど、結果はより正確になります。 サンプルサイズが小さい場合、パラメータの点推定により重大な誤差が生じる可能性があります。
大好きです サンプル(量)n)順序集合と考えることができます×1、×2、 ..., x n独立した同一分布の確率変数。
さまざまなサンプルサイズのサンプル平均 n 同じ集団からでも違うでしょう。 つまり、標本平均は確率変数と考えることができ、標本平均の分布とその数値的特徴について話すことができることを意味します。
サンプル平均は、統計的推定に課せられるすべての要件を満たします。 一般平均値の不偏で効率的かつ一貫した推定値が得られます。
証明できるのは、。 したがって、標本分散は母集団分散の偏った推定値であり、母集団分散を過小評価しています。 つまり、サンプルサイズが小さいと、系統誤差が発生します。 不偏で一貫した推定値を得るには、次の値を取るだけで十分です。、これは修正分散と呼ばれます。 あれは
実際には、一般的な分散を推定するには、修正された分散が使用されます。 n < 30.その他の場合( n >30) からの偏差 ほとんど目立ちません。 したがって、大きな値の場合、 n オフセット誤差は無視できます。
また、相対周波数がn i / n は、不偏かつ一貫した確率推定値です。 P (X =x i )。 経験的分布関数 F*(x ) は、理論上の分布関数の不偏かつ一貫した推定値です。 F(x)=P(X< x ).
例:
サンプル表から期待値と分散の不偏推定値を見つけます。
| x i |
|||
| 私は |
解決:
サンプルサイズ n = 20。
数学的期待値の不偏推定値はサンプル平均です。
不偏分散推定値を計算するには、まず標本分散を求めます。
次に、不偏推定値を求めてみましょう。
9. 分布パラメータの区間推定値
間隔は、調査対象の間隔の終わりという 2 つの数値によって決定される統計的推定値です。
番号> 0、つまり | Q - Q *|< 、間隔推定の精度を特徴づけます。
信頼できる呼ばれた 間隔 、与えられた確率で不明なパラメータ値をカバーします Q 。 パラメータのすべての可能な値のセットに対する信頼区間の補完 Q 呼ばれた クリティカルエリア。 臨界領域が信頼区間の片側のみに位置する場合、信頼区間は次のように呼ばれます。 片面: 左側、クリティカル領域が左側にのみ存在する場合、および 右利き右側だけなら。 それ以外の場合は、信頼区間が呼び出されます。 両側性.
信頼性、または信頼レベル、 Q を推定します (Q を使用) *) は、次の不等式が満たされる確率です。 Q - Q *|< .
ほとんどの場合、信頼確率は事前に設定され (0.95; 0.99; 0.999)、それが 1 に近いという要件が課されます。
確率呼ばれた エラーの確率、または有意水準。
しましょう | Q - Q *|< 、 それから。 つまり、確率的にはパラメータの真の値は Q 区間に属します。 偏差が小さいほど、見積もりがより正確になります。
信頼区間の境界 (端) は次のように呼ばれます。 信頼限界、または臨界限界。
信頼区間の限界値はパラメータの分布則に依存します。質問*。
偏差値信頼区間の幅の半分に等しいと呼ばれます。 評価の精度。
信頼区間を構築する方法は、アメリカの統計学者ユー・ニューマンによって最初に開発されました。 推定精度、信頼確率 とサンプルサイズ n 相互に接続されています。 したがって、2 つの量の具体的な値がわかれば、いつでも 3 番目の量を計算できます。
標準偏差がわかっている場合に、正規分布の数学的期待値を推定するための信頼区間を見つけます。
正規分布の法則に従って一般母集団からサンプルを採取するとします。 一般的な標準偏差を知ろう、しかし理論的な分布の数学的期待は不明です().
次の式は正しいです。
それらの。 与えられた偏差値に応じて未知の一般平均が区間に属する確率を見つけることができます。 およびその逆。 この式から、サンプル サイズが増加し、信頼確率の値が固定されると、値は明らかになります。- 減少、つまり 評価の精度が上がります。 信頼性 (信頼確率) が増加すると、値は-増加、つまり 評価の精度が下がります。
例:
テストの結果、次の値が得られました -25、34、-20、10、21。 これらは標準偏差 2 の正規分布の法則に従うことが知られています。 の推定値 a* を求めます。数学的期待値 a. それに対する 90% 信頼区間を構築します。
解決:
不偏推定値を求めてみましょう
それから
a の信頼区間は次のとおりです: 4 – 1.47< ある< 4+ 1,47 или 2,53 < a < 5, 47
標準偏差が不明な場合に、正規分布の数学的期待値を推定するための信頼区間を見つけます。
一般集団は正規分布の法則に従うことを知っておいてください。。 信頼性でカバーされる信頼区間の精度この場合、パラメータ a の真の値は次の式で計算されます。
, ここで、n はサンプルサイズです。 , - 生徒の係数 (与えられた値から求められます)と 表「学生分布の重要なポイント」より)。
例:
テストの結果、-35、-32、-26、-35、-30、-17の値が得られました。 それらは正規分布の法則に従うことが知られています。 信頼確率 0.9 で母集団の数学的期待値 a の信頼区間を求めます。
解決:
不偏推定値を求めてみましょう.
見つけます.
それから
信頼区間は次の形式になります。(-29.2 - 5.62; -29.2 + 5.62) または (-34.82; -23.58)。
正規分布の分散と標準偏差の信頼区間を求める
正規法則に従って分布する値の特定の一般母集団から、ボリュームのランダムなサンプルを採取しましょうn < 30、標本分散が計算されます: 偏りありs 2 を修正しました。 次に、指定された信頼性を持つ間隔推定値を見つけます。一般的な差異についてD一般的な標準偏差以下の式が使用されます。
または,
価値観- 臨界点値のテーブルを使用して検出ピアソン分布。
分散の信頼区間は、これらの不等式のすべての辺を二乗することによって求められます。
例:
15本のボルトの品質をチェックしました。 製造時の誤差が正規分布の法則に従うと仮定すると、サンプルの標準偏差は次のようになります。5 mmに等しい、確実に決定未知のパラメータの信頼区間
区間の境界を二重不等式の形式で表します。
分散の両側信頼区間の終点は、適切な表 (自由度および信頼性の数に応じた分散の信頼区間の限界) を使用して、特定の信頼レベルとサンプル サイズに対する算術演算を実行することなく決定できます。 。 これを行うには、テーブルから取得した区間の両端に、修正された分散 s 2 を乗算します。.
例:
先ほどの問題を別の方法で解いてみましょう。
解決:
修正された分散を求めてみましょう。
「自由度と信頼性の数に応じた分散の信頼区間の限界」の表を使用して、次の分散の信頼区間の境界を見つけます。k=14と:下限値0.513、上限値2.354。
結果の境界に次の値を掛けてみましょう。s 2 を計算して根を抽出します (分散ではなく標準偏差の信頼区間が必要なため)。
例からわかるように、信頼区間のサイズはその構築方法に依存し、同様ではありますが不均等な結果が得られます。
十分に大きなサイズのサンプルの場合 (n>30) 一般標準偏差の信頼区間の境界は、次の式で決定できます。 - 表にまとめられ、対応する参照表に記載されている特定の数値。
1-の場合 q<1, то формула имеет вид:
例:
先ほどの問題を 3 番目の方法で解決しましょう。
解決:
以前に見つかったs= 5,17. q(0.95; 15) = 0.46 – 表から求められます。
それから:
研究は通常、事実を使用した検証を必要とする何らかの仮定から始まります。 この仮定、つまり仮説は、特定のオブジェクトのセットにおける現象や特性の関係に関連して定式化されます。
このような仮定を事実に照らしてテストするには、その仮定の根拠となる対応する特性を測定する必要があります。 しかし、すべての青年の攻撃性を測定することが不可能であるのと同様に、すべての女性と男性の不安を測定することは不可能です。 したがって、研究を実施するときは、関連する人々の集団を代表する比較的少数のグループのみに限定されます。
人口— これは、研究仮説が定式化される関連するオブジェクトのセット全体です。
たとえば、すべての男性。 またはすべての女性。 あるいは都市の住民全員。 研究者が研究結果に基づいて結論を導き出す対象となる一般母集団は、たとえば、特定の学校の 1 年生全員など、数がそれほど多くない場合があります。
したがって、一般集団は、その数が無限ではないものの、原則として継続的な研究にはアクセスできない、潜在的な被験者の集合体です。
サンプルまたはサンプル母集団- これは、その特性を研究するために一般集団から特別に選択された、数が限られたオブジェクトのグループ(心理学では被験者、回答者)です。 したがって、サンプルを使用して一般集団の特性を研究することは、 サンプリング研究。 ほとんどすべての心理学研究は選択的であり、その結論は一般集団にも適用されます。
したがって、仮説が立てられ、対応する母集団が特定された後、研究者はサンプルを整理するという問題に直面します。 サンプルは、サンプル研究の結論の一般化が正当化されるようなもの、つまり一般化、一般集団への拡張である必要があります。 研究結論の妥当性に関する主な基準— これらは、サンプルの代表性と (経験的) 結果の統計的信頼性です。
サンプルの代表性- 言い換えれば、その代表性とは、一般集団における変動性の観点から、研究対象の現象を完全に表現するサンプルの能力です。
もちろん、研究対象の現象のあらゆる範囲と変動のニュアンスを完全に把握できるのは一般人だけです。 したがって、代表性はサンプルが限られている限り常に制限されます。 そして、研究結果の一般化の境界を決定する際の主な基準となるのは、サンプルの代表性です。 ただし、研究者にとって十分なサンプルの代表性を得ることができるテクニックがあります (これらのテクニックは「実験心理学」コースで学習します)。
最初の主要な手法は、単純なランダム (ランダム化) 選択です。 これには、母集団の各メンバーがサンプルに含まれる他のメンバーと等しいチャンスを持つような条件を確保することが含まれます。 ランダム選択により、一般集団のさまざまな代表者をサンプルに含めることができます。 この場合、選択中にパターンが出現しないように特別な措置が取られます。 そしてこれにより、最終的には、研究対象の特性が、すべてではないにしても、可能な限り最大限の多様性でサンプル内で表現されることを期待できます。
代表性を確保する 2 番目の方法は、層別ランダムサンプリング、つまり一般母集団の特性に基づいた選択です。 これには、調査対象の資産の変動に影響を与える可能性のある資質 (性別、収入、教育レベルなどが考えられます) を事前に決定することが含まれます。 次に、一般集団におけるこれらの性質が異なるグループ (層) の数の割合が決定され、サンプル内の対応するグループの割合が同じであることが保証されます。 次に、単純なランダム選択の原理に従って、被験者がサンプルの各サブグループに選択されます。
統計的有意性、統計的有意性、研究結果は統計的推論方法を使用して決定されます。
私たちは意思決定をするとき、研究結果から特定の結論を導き出すとき、間違いを犯さないように保証されていますか? もちろん違います。 結局のところ、私たちの決定はサンプル母集団の研究結果と心理学的知識のレベルに基づいています。 私たちは間違いを完全に免れないわけではありません。 統計では、このような誤差は、1000 件中 1 件以下の頻度で発生する場合には許容されると見なされます (誤差の確率 α = 0.001、または関連する正しい結論の信頼確率 p = 0.999)。 100 件中 1 件の場合 (誤差の確率 α = 0.01、または正しい結論の関連する信頼確率 p = 0.99)、または 100 件中 5 件の場合 (誤りの確率 α = 0.05、または正しい結論出力の関連する信頼確率) p=0.95)。 心理学で決定が下されるのは最後の 2 つのレベルです。
統計的有意性について話すとき、「有意水準」(α と表記) という概念が使用されることがあります。 p と α の数値は、最大 1,000 まで相互に補完します。これは、一連の完全なイベントです。つまり、正しい結論を下したか、間違いを犯したかのどちらかです。 これらのレベルは計算されるものではなく、与えられるものです。 重要度のレベルは、一種の「赤い」線として理解でき、その交差により、このイベントはランダムではないと言えます。 すべての優れた科学レポートや出版物では、導き出された結論には、その結論が導き出された p 値または α 値の表示が伴う必要があります。
統計的推論の方法については、数学統計コースで詳しく説明します。 ここで、数値には特定の要件があることに注意してください。 サンプルサイズ。
残念ながら、必要なサンプルサイズを事前に決定するための厳密なガイドラインはありません。 さらに、研究者は通常、必要かつ十分な数についての質問に対する答えを得るのが遅すぎます - すでに調査されたサンプルのデータを分析した後でのみです。 ただし、最も一般的な推奨事項は次のように定式化できます。
1. 診断技術を開発する場合、200 人から 1000 ~ 2500 人までの最大のサンプル サイズが必要です。
2. 2 つのサンプルを比較する必要がある場合、その合計数は少なくとも 50 人でなければなりません。 比較されるサンプルの数はほぼ同じである必要があります。
3. 何らかの特性間の関係を研究する場合、サンプルサイズは少なくとも 30 ~ 35 人である必要があります。
4. 多ければ多いほど 変動性特性を研究するほど、サンプルサイズを大きくする必要があります。 したがって、性別、年齢などによるサンプルの均一性を高めることで、ばらつきを減らすことができます。これにより、結論を一般化する能力が低下します。
依存サンプルと独立サンプル。一般的な研究状況は、研究者にとって関心のある特性が、さらに比較する目的で 2 つ以上のサンプルで研究される場合です。 これらのサンプルは、組織化の手順に応じて、異なる割合になる可能性があります。 独立したサンプル これらは、あるサンプル内の任意の被験者が選択される確率が、別のサンプル内のどの被験者の選択にも依存しないという事実によって特徴付けられます。 に対して、 依存サンプルあるサンプルの各被験者が、ある基準に従って別のサンプルの被験者と一致するという事実によって特徴付けられます。
一般に、依存サンプルには比較サンプルへの被験者のペアごとの選択が含まれ、独立サンプルには被験者の独立した選択が含まれます。
「部分的に依存している」(または「部分的に独立している」)サンプルのケースは受け入れられないことに注意してください。これは予期せずにサンプルの代表性に違反します。
結論として、心理学研究には 2 つのパラダイムが区別できることに注意してください。
いわゆる R 方法論特定の影響、要因、または他の特性の影響下での特定の特性(心理的)の変動の研究が含まれます。 サンプルとは被験者のセットです。
別のアプローチ Q-方法論、さまざまな刺激(条件、状況など)の影響下での被験者(個人)の変動の研究が含まれます。 という状況に対応します。 サンプルは刺激のセットです。