 Giriş
GirişÖzet: İstatistikte örnekleme yöntemi. Örnek (Örnek popülasyon)
İstatistiksel çalışmalar çok zaman alıcı ve pahalıdır, bu nedenle fikir, sürekli gözlemin seçici olanla değiştirilmesi fikri ortaya çıktı.
Sürekli olmayan gözlemin temel amacı, incelenen kısmı için incelenen istatistiksel popülasyonun özelliklerini elde etmektir.
seçici gözlem- bu, rastgele seçim hükümlerine dayanarak, nüfusun genelleştirici göstergelerinin yalnızca tek bir bölüm için oluşturulduğu bir istatistiksel araştırma yöntemidir.
Örnekleme yönteminde, incelenen popülasyonun yalnızca belirli bir kısmı incelenirken, incelenecek istatistiksel popülasyona genel popülasyon denir.
Bir örneklem veya basitçe örneklem, genel popülasyondan seçilen ve istatistiksel araştırmaya tabi tutulacak birimlerin bir parçası olarak adlandırılabilir.
Örnekleme yönteminin değeri: ne zaman minimum sayı incelenen birimlerden, istatistiksel araştırmalar daha kısa sürelerde ve en az fon ve emek harcaması ile gerçekleştirilecektir.
Genel popülasyonda, incelenen özelliğe sahip birimlerin oranına genel oran denir (belirtilen R), ve çalışılan değişken özelliğinin ortalama değeri genel ortalamadır (belirtilen X).
Örnek popülasyonda, çalışılan özelliğin payına örnek payı veya kısım (w ile gösterilir) denir, örnekteki ortalama değer örnek ortalama.
Sınav süresi boyunca tüm kuralları bilimsel organizasyon, o zaman örnekleme yöntemi oldukça doğru sonuçlar verecektir ve bu nedenle sürekli gözlem verilerini kontrol etmek için bu yöntemin kullanılması tavsiye edilir.
Bu yöntem, devlet ve departman dışı istatistiklerde yaygınlaşmıştır, çünkü incelenen minimum birim sayısını incelerken, kapsamlı ve doğru bir çalışmaya olanak tanır.
İncelenen istatistiksel popülasyon, değişken özelliklere sahip birimlerden oluşur. Örneklemin bileşimi genel popülasyonun bileşiminden farklı olabilir, örneklemin özellikleri ile genel popülasyon arasındaki bu farklılık örnekleme hatasını oluşturur.
Seçici gözlemin doğasında bulunan hatalar, seçici gözlem verileri ile tüm popülasyon arasındaki tutarsızlığın boyutunu karakterize eder. Örnekleme sırasında meydana gelen hatalar temsili hatalar olarak adlandırılır ve rastgele ve sistematik olarak ikiye ayrılır.
Örnek popülasyon, gözlemin sürekli olmaması nedeniyle tüm popülasyonu doğru bir şekilde üretmiyorsa, buna rastgele hatalar denir ve boyutları yasaya dayalı olarak yeterli doğrulukla belirlenir. büyük sayılar ve olasılık teorisi.
Sistematik hatalar, gözlem için popülasyon birimlerinin rastgele seçilmesi ilkesinin ihlali sonucu ortaya çıkar.
2. Seçim türleri ve şemaları
Örnekleme hatasının boyutu ve bunu belirleme yöntemleri, seçimin türüne ve şemasına bağlıdır.
Dört tür gözlem birimi seçimi vardır:
1) rastgele;
2) mekanik;
3) tipik;
4) seri (iç içe).
rastgele seçim- rastgele bir örnekte en yaygın seçim yöntemi, istatistiksel popülasyonun her birimi için seri numaralı bir biletin hazırlandığı piyango yöntemi olarak da adlandırılır.
Daha sonra, istatistiksel popülasyonun gerekli sayıda birimi rastgele seçilir. Bu koşullar altında, her birinin örneğe girme olasılığı aynıdır, örneğin, kazançları hesaba katan sayıların belirli bir kısmı verilen toplam bilet sayısından rastgele seçildiğinde. Bu durumda, tüm sayılara örneğe girmek için eşit fırsat sağlanır.
mekanik seçim- bu, tüm popülasyonun rastgele bir temelde homojen büyüklükteki gruplara ayrıldığı, ardından her gruptan sadece bir birim alındığı bir yöntemdir.Çalışılan istatistiksel popülasyonun tüm birimleri belirli bir sırayla önceden düzenlenir, ancak buna bağlı olarak numune boyutu, gerekli sayıda birim belirli aralıklarla mekanik olarak seçilir.
Tipik seçim - Bu, incelenen istatistiksel popülasyonun temel, tipik bir özelliğe göre niteliksel olarak homojen, benzer gruplara bölündüğü, daha sonra bu grubun her birinden rastgele olarak belirli sayıda birimin seçildiği bir yöntemdir. tüm nüfus.
Tipik seçim, numunedeki tüm tipik grupların temsilcilerini içerdiğinden daha doğru sonuçlar verir.
Seri (iç içe) seçimi. Rastgele veya mekanik olarak seçilen tüm gruplar (seri, yuvalar) seçime tabidir. Bu tür her grup için seri, sürekli gözlem yapılır ve sonuçlar tüm popülasyona aktarılır.
Örnekleme doğruluğu aynı zamanda seçim şemasına da bağlıdır. Örnekleme, tekrarlı ve tekrarsız seçim şemasına göre yapılabilir.
yeniden seçim. Seçilen her birim veya seri, tüm popülasyona döndürülür ve yeniden örneklenebilir.Bu, geri dönen top şeması olarak adlandırılır.
Tekrarlayan seçim. Anket yapılan her birim geri çekilir ve popülasyona iade edilmez, bu nedenle yeniden anket yapılmaz. Bu şemaya geri dönüşsüz top denir.
Tekrarlamayan seçim daha doğru sonuçlar verir, çünkü aynı örneklem büyüklüğü ile gözlem, çalışılan popülasyonun daha fazla birimini kapsar.
Kombine seçim bir veya daha fazla adımdan geçebilir. Bir kez seçilen popülasyonun birimleri çalışmaya tabi tutulursa, bir örnek tek aşamalı olarak adlandırılır.
Popülasyonun seçimi aşamalardan, ardışık aşamalardan geçiyorsa ve her aşamada, seçim aşamasının kendi seçim birimi varsa, bir örnek çok aşamalı olarak adlandırılır.
Çok aşamalı örnekleme - örneklemenin tüm aşamalarında, aynı örnekleme birimi korunur, ancak birkaç aşamada, anket programının genişliği ve örneklem boyutunda birbirinden farklı olan örnek anketlerin aşamaları gerçekleştirilir.
Genel ve örnek popülasyonların parametrelerinin özellikleri aşağıdaki sembollerle gösterilir:
N- genel nüfusun hacmi;
n- örnek boyut;
X- genel ortalama;
Xörnek ortalamadır;
R– genel hisse;
w -örnek paylaşım;
2 - genel varyans (genel popülasyonda bir özelliğin dağılımı);
2 - aynı özelliğin örnek varyansı;
?- ortalama standart sapma genel popülasyonda;
? örnekteki standart sapmadır.
3. Örnekleme hataları
Örnek gözlemdeki her birim, diğerleriyle seçilmek için eşit fırsata sahip olmalıdır - bu, rastgele bir örneklemenin temelidir.
Kendinden rasgele örnekleme - bu, tüm genel nüfustan piyango veya benzer bir şekilde birimlerin seçilmesidir.
Rastgelelik ilkesi, bir nesnenin örneğe dahil edilmesinin veya çıkarılmasının şans dışında hiçbir faktörden etkilenmemesidir.
Örnek paylaşımörneklemdeki birim sayısının genel popülasyondaki birim sayısına oranıdır:
Saf haliyle kendiliğinden rasgele seçim, diğer tüm seçim türleri arasında ilkidir; seçici istatistiksel gözlemin temel ilkelerini içerir ve uygular.
Örnekleme yönteminde kullanılan iki ana genelleme göstergesi türü, nicel bir özelliğin ortalama değeri ve alternatif bir özelliğin göreli değeridir.
Örnek payı (w) veya özelliği, incelenen özelliğe sahip birimlerin sayısının oranı ile belirlenir. m, toplam örnekleme birimi sayısına (n):
Örnek göstergelerin güvenilirliğini karakterize etmek için örneğin ortalama ve marjinal hataları ayırt edilir.
Temsil hatası olarak da adlandırılan örnekleme hatası, karşılık gelen örnek ile genel özellikler arasındaki farktır:
?x = | x - x |;
?w =|х – p|.
Yalnızca örneklenmiş gözlemlerde örnekleme hatası var
Örnek ortalama ve örnek oranı alan rastgele değişkenlerdir çeşitli anlamlarörneğe dahil edilen çalışılan istatistiksel popülasyonun birimlerine bağlı olarak. Buna göre örnekleme hataları da rastgele değişkenlerdir ve farklı değerler de alabilirler. Bu nedenle, ortalama belirlenir olası hatalar ortalama örnekleme hatasıdır.
Ortalama örnekleme hatası, örneklem büyüklüğü tarafından belirlenir: popülasyon ne kadar büyükse, diğer her şey eşitse, ortalama örnekleme hatası o kadar küçük olur. Genel popülasyonun artan sayıda birimiyle örnek bir anketi kapsayarak, tüm popülasyonu giderek daha doğru bir şekilde karakterize ediyoruz.
Ortalama örnekleme hatası, çalışılan özelliğin varyasyon derecesine bağlıdır, sırayla varyasyon derecesi, varyans ile karakterize edilir? 2 veya w(l - w)- alternatif bir işaret için. Özellik varyasyonu ve varyansı ne kadar küçükse, ortalama örnekleme hatası o kadar küçüktür ve bunun tersi de geçerlidir.
Rastgele yeniden örnekleme için ortalama hatalar aşağıdaki formüller kullanılarak teorik olarak hesaplanır:
1) ortalama nicel özellik için:
nerede? 2 - nicel bir özelliğin dağılımının ortalama değeri.
2) bir pay için (alternatif işaret):
Peki popülasyondaki özelliğin varyansı nasıl? 2 tam olarak bilinmemekle birlikte, pratikte, yeterince büyük bir örneklem büyüklüğüne sahip örnek popülasyonun, örnek popülasyonun özelliklerini doğru bir şekilde yeniden ürettiğine göre, büyük sayılar yasası temelinde örnek popülasyon için hesaplanan varyans S 2 değerini kullanırlar. Genel popülasyon.
Rastgele yeniden örnekleme için ortalama örnekleme hatası formülleri aşağıdaki gibidir. İçin orta boy nicel özellik: genel varyans, seçmeli yoluyla aşağıdaki oranla ifade edilir:
burada S 2 dağılım değeridir.
mekanik örnekleme- bu, nötr bir kritere göre eşit gruplara ayrılan genelden bir örnek setindeki birimlerin seçimidir; örneklemdeki her bir gruptan sadece bir birim seçilecek şekilde yapılır.
Mekanik seçim ile, incelenen istatistiksel popülasyonun birimleri önceden belirli bir sıraya göre düzenlenir, ardından belirli bir aralıkta belirli sayıda birim mekanik olarak seçilir. Bu durumda, genel popülasyondaki aralığın büyüklüğü, örneklem payının karşılığına eşittir.
Yeterli olduğunda büyük nüfus sonuçların doğruluğu açısından mekanik seçim, rastgele olana yakındır.Bu nedenle, mekanik bir örneklemenin ortalama hatasını belirlemek için, rastgele bir tekrarsız örnekleme formülleri kullanılır.
Heterojen bir popülasyondan birimleri seçmek için, sözde tipik örnek kullanılır, genel popülasyonun tüm birimleri, incelenen göstergelerin bağlı olduğu özelliklere göre niteliksel olarak homojen, benzer gruplara bölünebildiğinde kullanılır.
Daha sonra, her tipik gruptan, rastgele veya mekanik bir numune ile numuneye ayrı bir birim seçimi yapılır.
Tipik örnekleme genellikle karmaşık istatistiksel popülasyonların çalışmasında kullanılır.
Tipik örnekleme daha doğru sonuçlar verir. Genel popülasyonun tiplendirilmesi, böyle bir örneğin temsil edilmesini, içindeki her bir tipolojik grubun temsil edilmesini sağlar, bu da gruplar arası varyansın ortalama örnek hatası üzerindeki etkisini hariç tutmayı mümkün kılar. Bu nedenle, tipik bir örneğin ortalama hatası belirlenirken, grup içi varyansların ortalaması, bir varyasyon göstergesi görevi görür.
Seri örnekleme, bu tür gruplardaki istisnasız tüm birimleri gözleme tabi tutmak için eşit büyüklükteki gruplardan oluşan genel bir popülasyondan rastgele seçimi içerir.
İstisnasız tüm birimler gruplar (seriler) içinde incelendiği için ortalama örnekleme hatası (eşit seriler seçildiğinde) sadece gruplar arası (seriler arası) varyansa bağlıdır.
4. Örnek sonuçlarını popülasyona yaymanın yolları
Örnek sonuçları temelinde genel popülasyonun karakterizasyonu, örnek gözleminin nihai amacıdır.
Örnekleme yöntemi, örneklemin belirli göstergeleri için genel popülasyonun özelliklerini elde etmek için kullanılır. Çalışmanın amaçlarına bağlı olarak, bu, genel nüfus için örnek göstergelerin doğrudan yeniden hesaplanması veya düzeltme faktörlerinin hesaplanması yöntemi ile gerçekleştirilir.
Doğrudan yeniden hesaplama yöntemi, onunla birlikte örnek payının göstergelerinin olmasıdır. w veya orta Xörnekleme hatası dikkate alınarak genel popülasyona genişletilir.
Düzeltme faktörleri yöntemi, örnekleme yönteminin amacı tam muhasebe sonuçlarını iyileştirmek olduğunda kullanılır. Bu yöntem, nüfusun yıllık hayvan sayımlarının verilerini iyileştirmek için kullanılır.
Örnekleme yöntemi teorisinde, temsililiği sağlamak için çeşitli seçim yöntemleri ve örnekleme türleri geliştirilmiştir. Altında seçim yöntemi genel popülasyondan birimleri seçme prosedürünü anlar. İki seçim yöntemi vardır: tekrarlanan ve tekrarlanmayan. saat tekrarlanan Seçim sürecinde, rastgele seçilen her birim, incelemesinden sonra genel popülasyona geri döndürülür ve sonraki seçim sırasında tekrar örnekleme düşebilir. Bu seçim yöntemi, “geri dönen top” şemasına göre oluşturulmuştur: genel popülasyonun her bir birimi için örneğe girme olasılığı, seçilen birimlerin sayısından bağımsız olarak değişmez. saat tekrar etmeyen seçim, rastgele seçilen her birim, incelemeden sonra genel popülasyona geri döndürülmez. Bu seçim yöntemi, “geri gönderilmeyen top” şemasına göre oluşturulmuştur: seçim yapıldıkça genel popülasyonun her bir birimi için örneğe girme olasılığı artar.
Örnek bir popülasyon oluşturma metodolojisine bağlı olarak, aşağıdaki ana olanlar ayırt edilir: örnek türleri:
aslında rastgele;
mekanik;
tipik (tabakalı, bölgeli);
seri (iç içe);
kombine;
çok aşamalı;
çok fazlı;
iç içe.
Gerçek rastgele örnek bilimsel ilke ve rastgele seçim kurallarına sıkı sıkıya bağlı olarak oluşturulmuştur. Gerçek rastgele örneği almak için nüfus kesinlikle seçim birimlerine bölünür ve daha sonra rastgele tekrarlanan veya tekrarlanmayan bir sırayla yeterli sayıda birim seçilir.
Rastgele sıralama, kura çekmek gibidir. Uygulamada, en sık özel rasgele sayı tabloları kullanılırken kullanılır. Örneğin 1587 birim içeren bir popülasyondan 40 birim seçilmesi gerekiyorsa, tablodan 1587'den küçük 40 adet dört basamaklı sayı seçilir.
Gerçek rasgele örneğin tekrarlı olarak düzenlenmesi durumunda standart hata formül (6.1)'e göre hesaplanır. Tekrarlı olmayan bir örnekleme yöntemiyle standart hatayı hesaplama formülü şöyle olacaktır:
nerede 1 - n/ N- örneğe dahil edilmeyen genel popülasyon birimlerinin oranı. Bu pay her zaman olduğu için birden az, o zaman tekrarlı olmayan seçimdeki hata, ceteris paribus, tekrarlanan seçimden her zaman daha azdır. Tekrarlanmayan seçimi organize etmek, tekrarlanan seçime göre daha kolaydır ve çok daha sık kullanılır. Ancak tekrarlı olmayan örneklemede standart hatanın değeri daha basit bir formül (5.1) kullanılarak belirlenebilir. Böyle bir değiştirme, genel popülasyonun örneğe dahil edilmeyen birimlerinin oranı büyükse ve bu nedenle değer bire yakınsa mümkündür.
Rastgele seçim kurallarına tam olarak uygun bir örnek oluşturmak, pratik olarak çok zordur ve bazen imkansızdır, çünkü rastgele sayı tablolarını kullanırken, genel popülasyonun tüm birimlerini numaralandırmak gerekir. Oldukça sık, genel nüfus o kadar büyüktür ki, bu tür ön çalışmaları yürütmek son derece zor ve uygun değildir, bu nedenle pratikte, her biri kesinlikle rastgele olmayan başka tür numuneler kullanılır. Ancak, rastgele seçim koşullarına maksimum yakınlık sağlanacak şekilde düzenlenirler.
ne zaman saf mekanik örnekleme birimlerin tüm popülasyonu, her şeyden önce, örneğin alfabetik olarak, incelenen özelliğe göre bazı nötr sırayla derlenen bir seçim birimleri listesi şeklinde sunulmalıdır. Daha sonra örnekleme birimleri listesi, birimleri seçmek için gerekli olduğu kadar eşit parçaya bölünür. Sonraki yerleşik kural, incelenen özelliğin varyasyonu ile ilgili olmayan, listenin her bölümünden bir birim seçilir. Bu tür örnekleme her zaman rastgele bir seçim sağlamayabilir ve elde edilen örnek yanlı olabilir. Bu, ilk olarak, genel popülasyonun birimlerinin sıralanmasının rastgele olmayan bir yapıya sahip olabileceği gerçeğiyle açıklanmaktadır. İkincisi, eğer köken yanlış belirlenirse, popülasyonun her bir bölümünden örnekleme de bir yanlılık hatasına yol açabilir. Bununla birlikte, mekanik bir numuneyi uygun bir rastgele olandan organize etmek pratik olarak daha kolaydır ve bu tür numune alma genellikle numune anketlerinde kullanılır. Mekanik örnekleme için standart hata, fiili rastgele tekrarlamayan örnekleme (6.2) formülü ile belirlenir.
Tipik (bölgeli, tabakalı) numune iki hedefi vardır:
araştırmacının ilgilendiği özelliklere göre genel popülasyonun karşılık gelen tipik gruplarının örnekleminde temsil sağlamak;
örnek anket sonuçlarının doğruluğunu artırmak.
Tipik bir örnekle, oluşum başlamadan önce, birimlerin genel popülasyonu tipik gruplara ayrılır. Aynı zamanda, çok önemli nokta dır-dir doğru seçim gruplama özelliği Seçilen tipik gruplar, aynı veya farklı sayıda seçim birimi içerebilir. İlk durumda, her gruptan aynı seçim payı ile örneklem seti, ikinci durumda genel popülasyondaki payı ile orantılı bir pay ile oluşturulmaktadır. Örnek, eşit bir seçim payı ile oluşturulmuşsa, özünde, her biri tipik bir grup olan daha küçük popülasyonlardan uygun şekilde rastgele bir dizi örneğe eşdeğerdir. Her gruptan seçim rastgele (tekrarlı veya tekrarsız) veya mekanik sırayla gerçekleştirilir. Hem eşit hem de eşit olmayan bir seçim payına sahip tipik bir örnekle, örneklemdeki tipik grupların her birinin zorunlu temsilini sağladığından, çalışılan özelliğin gruplar arası varyasyonunun sonuçlarının doğruluğu üzerindeki etkisini ortadan kaldırmak mümkündür. Ayarlamak. Numunenin standart hatası, toplam varyansın büyüklüğüne bağlı olmayacak mı? 2, ve grup dağılımlarının ortalamasının değeri üzerine?i 2 . Grup varyanslarının ortalaması her zaman toplam varyanstan daha küçük olduğundan, diğer şeyler eşit olduğunda, tipik bir örneğin standart hatası, rastgele bir örneğin kendisinin standart hatasından daha az olacaktır.
Tipik bir numunenin standart hatalarını belirlerken aşağıdaki formüller kullanılır:
Tekrarlanan seçim ile

Tekrarlanmayan bir seçim yöntemiyle:

örnek popülasyondaki grup varyanslarının ortalamasıdır.
Seri (iç içe) örnekleme- bu, araştırılacak birimler değil, birim grupları (seri, yuva) rastgele seçildiğinde bir tür örnek oluşturmadır. Seçilen seriler (yuvalar) içerisinde tüm birimler incelenir. Seri örneklemenin organize edilmesi ve yürütülmesi, bireysel birimlerin seçiminden pratik olarak daha kolaydır. Bununla birlikte, bu tür örnekleme, ilk olarak, serilerin her birinin temsil edilmesini sağlamaz ve ikinci olarak, incelenen özelliğin seriler arası varyasyonunun anket sonuçları üzerindeki etkisini ortadan kaldırmaz. Bu varyasyon önemli olduğunda, rastgele temsiliyet hatasını artıracaktır. Araştırmacı, örneklem türünü seçerken bu durumu dikkate almalıdır. Seri örneklemenin standart hatası aşağıdaki formüllerle belirlenir:
Tekrarlanan seçim yöntemiyle -

nerede örnek popülasyonun seriler arası varyansı; r– seçilen serilerin sayısı;
Tekrarlanmayan bir seçim yöntemiyle -

nerede R genel popülasyondaki seri sayısıdır.
Uygulamada, örnek anketlerin amaç ve hedeflerine ve ayrıca bunları organize etme ve yürütme olanaklarına bağlı olarak belirli yöntem ve örnekleme türleri kullanılmaktadır. Çoğu zaman, örnekleme yöntemleri ve örnekleme türlerinin bir kombinasyonu kullanılır. Bu tür örnekler denir kombine. Kombinasyon şu şekilde mümkündür: farklı kombinasyonlar: mekanik ve seri numune alma, tipik ve mekanik, seri ve fiilen rastgele, vb. Birleştirilmiş numune, anketi organize etmek ve yürütmek için en düşük işçilik ve parasal maliyetlerle en büyük temsili sağlamak için kullanılır.
Birleştirilmiş bir örnekle, örneğin standart hatasının değeri, her adımındaki hatalardan oluşur ve karşılık gelen örneklerin hatalarının karelerinin toplamının karekökü olarak belirlenebilir. Bu nedenle, kombine örnekleme ile birlikte mekanik ve tipik örnekleme kullanılmışsa, standart hata formülle belirlenebilir.

nerede?1 ve? 2 sırasıyla mekanik ve tipik numunelerin standart hatalarıdır.
tuhaflık çok aşamalı örneklemeörneğin seçim aşamalarına göre kademeli olarak oluşturulması gerçeğinden oluşur. İlk aşamada, birinci aşamanın birimleri önceden belirlenmiş bir yöntem ve seçim türü kullanılarak seçilir. İkinci aşamada, örnekleme dahil edilen ilk aşamanın her bir biriminden ikinci aşamanın birimleri seçilir vb. Aşama sayısı ikiden fazla olabilir. Son aşamada ise birimleri ankete tabi tutulacak bir örneklem oluşturulur. Bu nedenle, örneğin, örnek bir hane bütçesi araştırması için, ilk aşamada, ikinci aşamada - seçilen bölgelerdeki ilçeler, üçüncü aşamada - her birinde ülkenin bölgesel konuları seçilir. belediye işletmeler veya kuruluşlar seçilir ve son olarak dördüncü aşamada seçilen işletmelerdeki aileler seçilir.
Böylece son aşamada örnekleme seti oluşturulmuştur. Çok aşamalı örnekleme, genel olarak aynı boyuttaki tek aşamalı bir örnekten daha az doğru sonuçlar vermesine rağmen, diğer türlere göre daha esnektir. Bununla birlikte, aynı zamanda, çok aşamalı seçimdeki örnekleme çerçevesinin her aşamada yalnızca örneklemdeki birimler için oluşturulmasının gerekli olduğu önemli bir avantajı vardır ve bu çok önemlidir, çünkü genellikle hazır örnekleme çerçevesi yoktur.
Farklı hacimlerdeki gruplarla çok aşamalı seçimde örneklemenin standart hatası, formülle belirlenir.

nerede?1,?2,?3 , ... farklı aşamalardaki standart hatalardır;
n1, n2, n3 , .. . ilgili seçim aşamalarındaki örnek sayısıdır.
Grupların hacim olarak aynı olmaması durumunda teorik olarak bu formül kullanılamaz. Ancak, tüm aşamalardaki toplam seçim oranı sabitse, pratikte bu formülle yapılan hesaplama, hatanın bozulmasına yol açmaz.
Öz çok fazlı örnekleme başlangıçta oluşturulan örnekleme seti temelinde, bu alt örnekten bir sonraki alt örnekten, vb. bir alt örneğin oluşturulması gerçeğinden oluşur. İlk örnekleme seti birinci aşamadır, ondan gelen alt örnek ikincidir, vb. Aşağıdaki durumlarda çok fazlı örnekleme kullanılması tavsiye edilir:
Çalışmak için çeşitli işaretler farklı bir numune boyutu gereklidir;
incelenen işaretlerin dalgalanması aynı değildir ve gerekli doğruluk farklıdır;
ilk numunenin (birinci aşama) tüm birimleri için daha az ayrıntılı bilgi toplanmalı ve sonraki her aşamanın birimleri için daha ayrıntılı bilgi toplanmalıdır.
Çok aşamalı örneklemenin şüphesiz avantajlarından biri, ilk aşamada elde edilen bilgilerin sonraki aşamalarda ek bilgi olarak kullanılabilmesi, ikinci aşamaya ait bilgilerin sonraki aşamalarda ek bilgi olarak kullanılabilmesi vb. bilgilerin kullanılması, örnek anket sonuçlarının doğruluğunu artırır.
Çok aşamalı bir örnekleme düzenlenirken, çeşitli yöntem ve seçim türlerinin bir kombinasyonu kullanılabilir (mekanik örnekleme ile tipik örnekleme, vb.). Çok aşamalı seçim, çok aşamalı ile birleştirilebilir. Her aşamada, örnekleme çok aşamalı olabilir.
Çok fazlı bir numunedeki standart hata, numunesinin oluşturulduğu seçim yöntemi ve numune türü formüllerine göre her faz için ayrı ayrı hesaplanır.
iç içe seçimler- bunlar aynı genel popülasyondan aynı yöntem ve tiple oluşturulmuş iki veya daha fazla bağımsız örnektir. Numune araştırmalarının ön sonuçlarını kısa sürede elde etmek gerekirse, iç içe geçen numunelere başvurmanız tavsiye edilir. İç içe geçen numuneler, anket sonuçlarını değerlendirmek için etkilidir. Sonuçlar bağımsız örneklemlerde aynıysa, bu örnek anket verilerinin güvenilirliğini gösterir. İç içe geçen örnekler bazen her araştırmacının farklı bir örneklem anketi yürütmesini sağlayarak farklı araştırmacıların çalışmalarını test etmek için kullanılabilir.
İç içe geçen numuneler için standart hata, tipik orantılı numune alma (5.3) ile aynı formülle belirlenir. İç içe geçen örnekler diğer türlere göre daha fazla emek ve para gerektirir, bu nedenle araştırmacı bir örnek anket tasarlarken bunu dikkate almalıdır.
Hataları sınırla çeşitli yollar seçimi ve örnekleme türleri formülle belirlenir? = t?, nerede? karşılık gelen standart hatadır.
Olay olasılığının aralık tahmini. Rastgele seçim yöntemi durumunda örnek sayısını hesaplama formülleri.Bizi ilgilendiren olayların olasılıklarını belirlemek için örnekleme yöntemini kullanıyoruz: n Her birinde A olayının meydana gelebileceği (veya gerçekleşmeyeceği) bağımsız deneyler (olasılık R A olayının her deneyde meydana gelmesi sabittir). Daha sonra olayların oluşumlarının nispi sıklığı p* ANCAK bir dizide n testler olasılık için bir nokta tahmini olarak alınır p bir olayın meydana gelmesi ANCAK ayrı bir testte. Bu durumda p* değerine denir. örnek paylaşım olay oluşumları ANCAK ve r - genel hisse .
Merkezi limit teoreminin (Moivre-Laplace teoremi) doğal sonucu sayesinde, büyük bir örneklem boyutuna sahip bir olayın nispi frekansı, M(p*)=p parametreleriyle normal olarak dağılmış olarak kabul edilebilir ve
Bu nedenle, n>30 için genel kesir için güven aralığı aşağıdaki formüller kullanılarak oluşturulabilir:

burada u cr, verilen güven olasılığı γ: 2Ф(u cr)=γ dikkate alınarak Laplace fonksiyonunun tablolarına göre bulunur.
Küçük bir numune boyutu n≤30 ile, marjinal hata ε, Öğrenci dağılım tablosundan belirlenir: ![]() burada t cr =t(k; α) ve serbestlik derecesi sayısı k=n-1 olasılık α=1-γ (iki taraflı alan).
burada t cr =t(k; α) ve serbestlik derecesi sayısı k=n-1 olasılık α=1-γ (iki taraflı alan).
Formüller, seçim tekrarlı bir şekilde rastgele yapılmışsa geçerlidir (genel popülasyon sonsuzdur), aksi takdirde tekrarlanmayan seçim (tablo) için bir düzeltme yapılması gerekir.
Genel oran için ortalama örnekleme hatası
| Nüfus | Sonsuz | nihai hacim N |
| Seçim türü | tekrarlanan | tekrar etmeyen |
| Ortalama örnekleme hatası |
Uygun bir rastgele seçim yöntemiyle örnek boyutunu hesaplamak için formüller
| Seçim yöntemi | Örnek boyutu formülleri | ||
| orta için | paylaşım için | ||
| tekrarlanan | |||
| tekrar etmeyen | |||
Genel hisse ile ilgili sorunlar
"Verilen p 0 değeri güven aralığını kapsıyor mu?" - istatistiksel hipotez H 0:p=p 0 test edilerek cevaplanabilir. Deneylerin Bernoulli test şemasına göre (bağımsız, olasılık p bir olayın meydana gelmesi ANCAK devamlı). Hacim örneğine göre n A olayının meydana gelmesinin nispi sıklığını p* belirleyin: burada m- olayın meydana gelme sayısı ANCAK bir dizide n testler. H 0 hipotezini test etmek için, yeterince büyük bir örneklem büyüklüğü ile standart bir normal dağılıma sahip olan istatistikler kullanılır (Tablo 1).Tablo 1 - Genel paya ilişkin hipotezler
Hipotez | H0:p=p0 | H 0:p 1 \u003d p 2 |
| varsayımlar | Bernoulli test şeması | Bernoulli test şeması |
| Örnek tahminler | 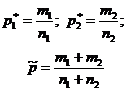 |
|
| İstatistik K |  |  |
| İstatistik dağılımı K | Standart normal N(0,1) |
Örnek 1. Şirket yönetimi, rastgele yeniden örneklemeyi kullanarak 900 çalışanıyla rastgele bir anket gerçekleştirdi. Ankete katılanlar arasında 270 kadın vardı. 0.95 olasılıkla, şirketin tüm ekibindeki kadınların gerçek oranını kapsayan bir güven aralığı çizin.
Çözüm. Duruma göre, kadınların örnek oranı (tüm katılımcılar arasında kadınların göreceli sıklığı). Seçim tekrarlandığından ve örneklem büyüklüğü büyük olduğundan (n=900), marjinal örnekleme hatası formül ile belirlenir. ![]()
u cr değeri, 2Ф(u cr)=γ bağıntısından Laplace fonksiyonunun tablosundan bulunur, yani. ![]() Laplace işlevi (Ek 1) u cr =1,96'da 0,475 değerini alır. Bu nedenle marjinal hata
Laplace işlevi (Ek 1) u cr =1,96'da 0,475 değerini alır. Bu nedenle marjinal hata ![]() ve istenen güven aralığı
ve istenen güven aralığı
(p – ε, p + ε) = (0,3 – 0,18; 0,3 + 0,18) = (0,12; 0,48)
Bu nedenle, 0.95 olasılıkla, firmanın tüm ekibindeki kadın oranının 0.12 ile 0.48 arasında olduğu garanti edilebilir.
Örnek #2. Otopark sahibi, otoparkın %80'den fazla dolu olması durumunda günü "şanslı" olarak değerlendirir. Yıl içerisinde 24'ü “başarılı” olmak üzere 40 adet otopark denetimi gerçekleştirilmiştir. 0.98 olasılıkla, yıl boyunca "şanslı" günlerin gerçek yüzdesini tahmin etmek için güven aralığını bulun.
Çözüm. “İyi” günlerin örnek kısmı
Laplace fonksiyonunun tablosuna göre, verilen bir değer için u cr değerini buluyoruz.
güven seviyesi
Ф(2.23) = 0.49, u cr = 2.33.
Seçimin tekrarlı olmadığı düşünüldüğünde (yani, aynı gün içinde iki kontrol yapılmamıştır), marjinal hatayı buluruz: ![]()
burada n=40 , N = 365 (gün). Buradan ![]()
ve genel kesir için güven aralığı: (p – ε, p + ε) = (0,6 – 0,17; 0,6 + 0,17) = (0,43; 0,77)
0.98 olasılıkla, yıl içindeki "iyi" günlerin oranının 0,43 ile 0,77 arasında olması beklenebilir.
Örnek #3. Partideki 2500 öğeyi kontrol ettikten sonra, 400 öğenin en yüksek dereceli olduğunu, ancak n-m'nin olmadığını buldular. %95 kesinlik ile 0,01 doğrulukla birinci sınıf kalitenin payını belirlemek için kaç ürünü kontrol etmeniz gerekiyor?
Yeniden seçim için numunenin boyutunu belirlemek için formüle göre bir çözüm arıyoruz.
Ф(t) = γ/2 = 0.95/2 = 0.475 ve Laplace tablosuna göre bu değer t=1.96'ya karşılık gelir.
Numune fraksiyonu w = 0.16; örnekleme hatası ε = 0.01
Örnek #4. Ürünün standardı karşılama olasılığı en az 0.97 ise, bir ürün partisi kabul edilir. Test edilen lottan rastgele seçilen 200 ürün arasından 193 ürünün standardı karşıladığı tespit edildi. Partiyi α=0.02 anlamlılık düzeyinde kabul etmek mümkün müdür?
Çözüm. Ana ve alternatif hipotezleri formüle ediyoruz.
H 0: p \u003d p 0 \u003d 0.97 - bilinmeyen genel pay p belirtilen değere eşittir p 0 =0.97. Koşulla ilgili olarak - test edilen partinin parçasının standarda uygun olma olasılığı 0.97'dir; şunlar. toplu ürün kabul edilebilir.
H1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Gözlemlenen istatistik değeri K(tablo) verilen değerler için hesaplayın p 0 =0.97, n=200, m=193

Kritik değer, eşitlikten Laplace fonksiyonunun tablosundan bulunur.
![]()
α=0.02 koşuluna göre, dolayısıyla F(Kcr)=0.48 ve Kcr=2.05. Kritik bölge solaktır, yani. (-∞;-K kp)= (-∞;-2.05) aralığıdır. Gözlenen Kobs = -0.415 değeri kritik bölgeye ait değildir, bu nedenle bu anlamlılık düzeyinde ana hipotezi reddetmek için bir neden yoktur. Bir grup ürün kabul edilebilir.
Örnek numarası 5. İki fabrika aynı tip parça üretiyor. Kalitelerini değerlendirmek için bu fabrikaların ürünlerinden numuneler alınmış ve aşağıdaki sonuçlar elde edilmiştir. İlk fabrikanın seçilen 200 ürününden 20'si kusurlu, ikinci fabrikanın 300 ürününden 15'i kusurluydu.
0.025 anlamlılık düzeyinde, bu fabrikalar tarafından üretilen parçaların kalitesinde önemli bir fark olup olmadığını öğrenin.
α=0.025 koşuluna göre, dolayısıyla F(Kcr)=0.4875 ve Kcr=2.24. İki taraflı bir alternatif ile kabul edilebilir değerlerin alanı (-2.24; 2.24) şeklindedir. Gözlenen Kobs =2.15 değeri bu aralığa düşer, yani. bu anlamlılık düzeyinde, ana hipotezi reddetmek için hiçbir neden yoktur. Fabrikalar aynı kalitede ürünler üretiyor.
Plan:
1. Matematiksel istatistik problemleri.
2. Örnek türleri.
3. Seçim yöntemleri.
4. Numunenin istatistiksel dağılımı.
5. Ampirik dağıtım fonksiyonu.
6. Çokgen ve histogram.
7. Varyasyon serilerinin sayısal özellikleri.
8. Dağıtım parametrelerinin istatistiksel tahminleri.
9. Dağılım parametrelerinin aralık tahminleri.
1. Matematiksel istatistiklerin görevleri ve yöntemleri
Matematik istatistikleri Bilimsel ve pratik amaçlar için istatistiksel gözlemsel verilerin sonuçlarını toplama, analiz etme ve işleme yöntemlerine ayrılmış bir matematik dalıdır.
Bu nesneleri karakterize eden bazı nitel veya nicel özelliklere göre bir dizi homojen nesneyi incelemek istensin. Örneğin, bir parça partisi varsa, o zaman parçanın standardı niteliksel bir işaret olarak hizmet edebilir ve parçanın kontrollü boyutu niceliksel bir işaret olarak hizmet edebilir.
Bazen sürekli bir çalışma yapılır, yani. her nesneyi istenen özelliğe göre inceleyin. Uygulamada, kapsamlı bir anket nadiren kullanılır. Örneğin, popülasyon çok sayıda nesne içeriyorsa, sürekli bir anket yapmak fiziksel olarak imkansızdır. Nesnenin araştırması, imhasıyla ilişkiliyse veya büyük malzeme maliyetleri gerektiriyorsa, tam bir anket yapmanın bir anlamı yoktur. Bu gibi durumlarda, tüm popülasyondan sınırlı sayıda nesne (örnek seti) rastgele seçilir ve çalışmalarına tabi tutulur.
Matematiksel istatistiklerin ana görevi, amaca bağlı olarak, örnek verilere dayalı olarak tüm popülasyonu incelemektir, yani. popülasyonun olasılıksal özelliklerinin incelenmesi: dağılım yasası, sayısal özellikler, vb. Belirsizlik koşulları altında yönetimsel kararlar almak için.
2. Örnek türleri
Nüfus örneğin yapıldığı nesneler kümesidir.
Örnek popülasyon (örnek) rastgele seçilmiş nesneler topluluğudur.
Popülasyon boyutu bu koleksiyondaki nesnelerin sayısıdır. Genel nüfusun hacmi belirtilir N, seçici - n.
Örnek:
1000 parçadan 100 parça inceleme için seçilirse, genel nüfusun hacmi N = 1000 ve örnek boyutu n = 100.
Örnekleme iki şekilde yapılabilir: nesne seçilip üzerinde gözlemlendikten sonra genel popülasyona döndürülebilir veya döndürülmeyebilir. O. Numuneler tekrarlı ve tekrarsız olarak ikiye ayrılır.
tekrarlananaranan örnekleme, seçilen nesnenin (bir sonrakini seçmeden önce) genel popülasyona döndürüldüğü.
tekrarlanmayanaranan örnekleme, seçilen nesnenin genel popülasyona döndürülmediği.
Uygulamada, genellikle tekrarlanmayan rastgele seçim kullanılır.
Örneklemin verilerinin genel popülasyonda ilginin özelliği hakkında yeterli güvenle yargıya varabilmesi için, örneğin nesnelerinin onu doğru bir şekilde temsil etmesi gerekir. Örnek, popülasyonun oranlarını doğru bir şekilde temsil etmelidir. örnek olmalıdır temsilci (temsilci).
Büyük sayılar kanunu sayesinde, örneklemin rastgele yapılması durumunda temsili olacağı iddia edilebilir.
Genel popülasyonun büyüklüğü yeterince büyükse ve örneklem bu popülasyonun yalnızca önemsiz bir parçasıysa, tekrarlanan ve tekrarlanmayan örnekler arasındaki ayrım silinir; sınırlayıcı durumda, sonsuz bir genel popülasyon göz önüne alındığında ve örneklem sonlu bir büyüklüğe sahip olduğunda bu fark ortadan kalkar.
Örnek:
Amerikan dergisi Literary Review'da, istatistiksel yöntemler kullanılarak, 1936'da yaklaşan ABD başkanlık seçimlerinin sonucuna ilişkin tahminler üzerine bir çalışma yapılmıştır. Bu görev için başvuranlar F.D. Roosevelt ve A.M. Landon. Telefon abonelerinin referans kitapları, incelenen Amerikalıların genel nüfusu için bir kaynak olarak alındı. Bunlardan 4 milyon adres rastgele seçildi ve derginin editörleri, cumhurbaşkanlığı adaylarına karşı tutumlarını ifade etmelerini isteyen kartpostallar gönderdi. Anket sonuçlarını işledikten sonra dergi, Landon'ın yaklaşan seçimleri büyük bir farkla kazanacağına dair sosyolojik bir tahmin yayınladı. Ve ... yanılmışım: Roosevelt kazandı.
Bu örnek, temsili olmayan bir örneklem örneği olarak görülebilir. Gerçek şu ki, Amerika Birleşik Devletleri'nde yirminci yüzyılın ilk yarısında, yalnızca Landon'ın görüşlerini destekleyen nüfusun zengin kısmının telefonları vardı.
3. Seçim yöntemleri
Uygulamada, 2 türe ayrılabilen çeşitli seçim yöntemleri kullanılır:
1. Seçim, popülasyonun parçalara bölünmesini gerektirmez (a) basit rastgele tekrar yok; b) basit rastgele tekrar).
2. Genel nüfusun parçalara ayrıldığı seçim. (a) tipik seçim; b) mekanik seçim; içinde) seri seçim).
Basit rastgele bunu ara seçim nesnelerin tüm genel popülasyondan birer birer (rastgele) çıkarıldığı .
Tipikaranan seçim nesnelerin tüm genel popülasyondan değil, "tipik" bölümlerinin her birinden seçildiği . Örneğin, bir parça birkaç makinede yapılıyorsa, seçim tüm makineler tarafından üretilen tüm parça setinden değil, her makinenin ürünlerinden ayrı ayrı yapılır. Bu tür seçim, incelenen özellik, genel popülasyonun çeşitli "tipik" bölümlerinde fark edilir şekilde dalgalanma gösterdiğinde kullanılır.
Mekanikaranan seçim genel popülasyonun "mekanik olarak" örneğe dahil edilecek nesneler olduğu kadar çok gruba ayrıldığı ve her gruptan bir nesnenin seçildiği . Örneğin, makine tarafından yapılan parçaların %20'sini seçmeniz gerekiyorsa, her 5'inci parça seçilir; parçaların %5'inin seçilmesi gerekiyorsa - her 20'de bir, vb. Bazen böyle bir seçim, temsili bir numune sağlamayabilir (her 20. döner silindir seçilirse ve seçimden hemen sonra kesici değiştirilirse, kör kesicilerle döndürülen tüm silindirler seçilecektir).
Seriaranan seçim nesnelerin genel popülasyondan birer birer değil, sürekli bir ankete tabi tutulan “seri” olarak seçildiği . Örneğin, ürünler büyük bir otomatik makine grubu tarafından üretiliyorsa, sadece birkaç makinenin ürünleri sürekli bir incelemeye tabi tutulur.
Uygulamada, yukarıdaki yöntemlerin birleştirildiği kombine seçim sıklıkla kullanılır.
4. Numunenin istatistiksel dağılımı
Genel popülasyondan bir örnek alınsın ve x 1 değeri-bir kez gözlemlendi, x 2 -n 2 kez, ... x k - n k kez. n= n 1 +n 2 +...+n k örnek boyutudur. gözlemlenen değerleraranan seçenekler, ve dizi artan sırada yazılmış bir değişkendir - varyasyon serisi. gözlem sayısıaranan frekanslar (mutlak frekanslar) ve bunların örneklem büyüklüğü ile ilişkisi- bağıl frekanslar veya istatistiksel olasılıklar.
Seçeneklerin sayısı büyükse veya örnek sürekli bir genel popülasyondan yapılmışsa, varyasyon serisi bireysel puan değerleriyle değil, genel popülasyonun değer aralıklarıyla derlenir. Böyle bir dizi denir Aralık. Aralıkların uzunlukları eşit olmalıdır.
Numunenin istatistiksel dağılımı seçenekler listesi ve bunlara karşılık gelen frekanslar veya göreli frekanslar olarak adlandırılır.
İstatistiksel dağılım, bir aralık dizisi ve bunlara karşılık gelen frekanslar (bu değer aralığına düşen frekansların toplamı) olarak da belirtilebilir.
Nokta varyasyon frekans serisi bir tablo ile temsil edilebilir:
| x ben |
x 1 |
x2 |
… |
x k |
| ben |
1 |
n 2 |
… |
nk |
Benzer şekilde, bir nokta varyasyonel bağıl frekans serisi temsil edilebilir.
Ve:
Örnek:
Bazı metinlerdeki X harflerinin sayısının 1000'e eşit olduğu ortaya çıktı. İlk harf "i", ikincisi - "i" harfi, üçüncüsü - "a" harfi, dördüncü - "u". Sonra "o", "e", "y", "e", "s" harfleri geldi.
Alfabede işgal ettikleri yerleri sırasıyla yazalım: 33, 10, 1, 32, 16, 6, 21, 31, 29.
Bu sayıları artan düzende sıraladıktan sonra bir varyasyon dizisi elde ederiz: 1, 6, 10, 16, 21, 29, 31, 32, 33.
Metindeki harflerin görünme sıklığı: "a" - 75, "e" -87, "i" - 75, "o" - 110, "y" - 25, "s" - 8, "e" - 3, "yu "- 7," ben "- 22.
Nokta varyasyonlu bir frekans serisi oluşturuyoruz:
Örnek:
Belirtilen hacim örnekleme frekans dağılımı n = 20.
Göreceli frekansların bir nokta varyasyon serisi yapın.
| x ben |
2 |
6 |
12 |
| ben |
3 |
10 |
7 |
Çözüm:
Göreceli frekansları bulun:
| x ben |
2 |
6 |
12 |
| ben |
0,15 |
0,5 |
0,35 |
Bir aralık dağılımı oluştururken, aralık sayısını veya her aralığın boyutunu seçmek için kurallar vardır. Buradaki kriter optimal orandır: aralık sayısındaki artışla temsil edilebilirlik artar, ancak veri miktarı ve bunları işleme süresi artar. Fark x max - x min arasındaki en büyük ve en küçük değerler değişkenine değişken denir büyük ölçekteörnekler.
Aralık sayısını saymak için k genellikle Sturgess'in ampirik formülünü uygular (en yakın uygun tam sayıya yuvarlamayı ifade eder): k = 1 + 3.322 log n .
Buna göre, her aralığın değeri h formül kullanılarak hesaplanabilir:
5. ampirik dağıtım fonksiyonu
Genel popülasyondan bir örnek düşünün. X nicel özniteliğinin frekanslarının istatistiksel dağılımı bilinsin, notasyonu tanıtalım: n xx'ten küçük bir özellik değerinin gözlemlendiği gözlem sayısıdır; n toplam gözlem sayısıdır (örnek boyutu). Göreli olay frekansı X<х равна nx/n . Eğer x değişirse, bağıl frekans da değişir, yani. göreceli sıklıknx /nx'in bir fonksiyonudur. Çünkü ampirik olarak bulunur, buna ampirik denir.
Ampirik dağılım işlevi (örnek dağılım işlevi) işlevi çağırher x için X olayının göreli frekansını belirleyen ,<х.
x'ten küçük seçeneklerin sayısı nerede,
n - örnek boyutu.
Numunenin ampirik dağılım fonksiyonundan farklı olarak, popülasyonun dağılım fonksiyonu F(x) olarak adlandırılır. teorik dağılım fonksiyonu.
Ampirik ve teorik dağılım fonksiyonları arasındaki fark, teorik fonksiyon F(x)'in bir X olayının olasılığını belirlemesidir.
O. genel popülasyonun teorik (bütünsel) dağılım fonksiyonunun yaklaşık bir temsili için örneğin ampirik dağılım fonksiyonunun kullanılması tavsiye edilir.
F*(x) tüm özelliklere sahip F(x).
1. Değerler F*(x) aralığına aittir.
2. F*(x) azalmayan bir fonksiyondur.
3. En küçük değişken ise, x'de F*(x) = 0 < x1; x k en büyük değişken ise, x > x k için F*(x) = 1 olur.
Şunlar. F*(x) F(x) tahminine hizmet eder.
Örnek bir varyasyon serisi ile verilmişse, ampirik fonksiyon şu şekildedir:
Ampirik fonksiyonun grafiğine birikimli denir.
Örnek:
Verilen örnek dağılımı üzerine ampirik bir fonksiyon çizin.
Çözüm:
Örnek boyutu n = 12 + 18 +30 = 60. En küçük seçenek 2'dir, yani. x'te <
2. Olay X<6,
(x 1
= 2) наблюдалось 12 раз, т.е. F*(x)=12/60=0.2 2'de <
x <
6. Olay X<10, (x 1 =2, x 2 = 6) наблюдалось 12 + 18 = 30 раз, т.е.F*(x)=30/60=0,5
при 6 <
x <
10. Çünkü x=10 en büyük seçenektir, o zaman F*(x) = 1 x>10'da. İstenen ampirik fonksiyon şu şekildedir:
kümülatif:
Kümülat, grafik olarak sunulan bilgileri anlamayı mümkün kılar, örneğin şu soruları yanıtlamak için: “Özniteliğin değerinin 6'dan küçük veya 6'dan küçük olmadığı gözlemlerin sayısını belirleyin. F*(6) = 0.2 » O halde gözlenen özelliğin değerinin 6'dan küçük olduğu gözlem sayısı 0,2* n \u003d 0.2 * 60 \u003d 12. Gözlenen özelliğin değerinin 6'dan az olmadığı gözlem sayısı (1-0.2) * n \u003d 0.8 * 60 \u003d 48.
Bir aralık varyasyon serisi verilirse, ampirik dağılım fonksiyonunu derlemek için, aralıkların orta noktaları bulunur ve bunlardan nokta varyasyon serisine benzer şekilde ampirik dağılım fonksiyonu elde edilir.
6. Çokgen ve histogram
Netlik için, istatistiksel dağılımın çeşitli grafikleri oluşturulmuştur: polinom ve histogramlar
Frekans poligonu bu, segmentleri ( x 1 ;n 1 ), ( x 2 ;n 2 ),…, ( x k ; n k ) noktalarını birleştiren kesik bir çizgidir, seçenekler nerede, bunlara karşılık gelen frekanslardır.
Göreceli frekansların çokgeni - bu, segmentleri ( x 1 ;w 1 ), (x 2 ;w 2 ),…, ( x k ;w k ) noktalarını birleştiren kesik bir çizgidir, burada x i seçeneklerdir, w i bunlara karşılık gelen göreli frekanslardır.
Örnek:
Verilen örnek dağılımı üzerinde göreli frekans polinomunu çizin:
Çözüm:
Sürekli bir özellik durumunda, özelliğin gözlenen tüm değerlerini içeren aralığın, h uzunluğundaki birkaç kısmi aralığa bölündüğü ve her bir kısmi aralık için n i bulunan bir histogram oluşturulması tavsiye edilir. - i-inci aralığa düşen değişken frekansların toplamı. (Örneğin, bir kişinin boyunu veya kilosunu ölçerken sürekli bir işaretle uğraşıyoruz).
Frekans histogramı- bu, tabanları h uzunluğundaki kısmi aralıklar olan ve yükseklikleri orana (frekans yoğunluğu) eşit olan dikdörtgenlerden oluşan basamaklı bir şekildir.
Meydan i-inci kısmi dikdörtgen, i-inci aralığın varyantının frekanslarının toplamına eşittir, yani. frekans histogramı alanı, tüm frekansların toplamına eşittir, yani. örnek boyut.
Örnek:
Elektrik şebekesindeki gerilimdeki (volt cinsinden) değişimin sonuçları verilmiştir. Voltaj değerleri aşağıdaki gibi ise bir varyasyon serisi oluşturun, bir poligon ve bir frekans histogramı oluşturun: 227, 215, 230, 232, 223, 220, 228, 222, 221, 226, 226, 215, 218, 220, 216, 220, 225, 212 , 217, 220.
Çözüm:
Bir dizi varyasyon oluşturalım. n = 20, x min =212, x max =232'ye sahibiz.
Aralık sayısını hesaplamak için Sturgess formülünü kullanalım.
Aralık varyasyonel frekans serisi şu şekildedir:
|
|
Frekans Yoğunluğu |
|
212-21 6 |
0,75 |
|
|
21 6-22 0 |
0,75 |
|
|
220-224 |
1,75 |
|
|
224-228 |
||
|
228-232 |
0,75 |
Şimdi bir frekans histogramı oluşturalım:
Önce aralıkların orta noktalarını bularak bir frekans çokgeni oluşturalım:
Göreceli frekansların histogramı Tabanları h uzunluğundaki kısmi aralıklar olan ve yükseklikleri w oranına eşit olan dikdörtgenlerden oluşan basamaklı bir şekil olarak adlandırın. i/h (bağıl frekans yoğunluğu).
Meydan i-inci kısmi dikdörtgen, i-inci aralığa düşen varyantın göreli frekansına eşittir. Şunlar. göreli frekansların histogramının alanı, tüm göreli frekansların toplamına eşittir, yani. birim.
7. Varyasyon serisinin sayısal özellikleri
Genel ve örnek popülasyonların temel özelliklerini göz önünde bulundurun.
Genel ikincil genel popülasyonun özelliğinin değerlerinin aritmetik ortalaması olarak adlandırılır.
Farklı değerler için x 1 , x 2 , x 3 , …, x n . N hacminin genel popülasyonunun işareti:
Nitelik değerlerinin karşılık gelen frekansları varsa N 1 +N 2 +…+N k =N , o zaman
örnek ortalamaörnek popülasyonun özelliğinin değerlerinin aritmetik ortalaması olarak adlandırılır.
Nitelik değerlerinin karşılık gelen frekansları varsa n 1 +n 2 +…+n k = n, o zaman
Örnek:
Örnek için örnek ortalamasını hesaplayın: x 1 = 51.12; x 2 \u003d 51.07; x 3 \u003d 52.95; x 4 \u003d 52.93; x 5 \u003d 51,1; x 6 \u003d 52,98; x 7 \u003d 52.29; x 8 \u003d 51.23; x 9 \u003d 51.07; x10 = 51.04.
Çözüm:
Genel varyans genel popülasyonun karakteristik X değerlerinin genel ortalamadan sapmalarının karelerinin aritmetik ortalaması olarak adlandırılır.
Farklı değerler için x 1 , x 2 , x 3 , …, x N, N hacminin popülasyonunun işaretinin elimizde:
Nitelik değerlerinin karşılık gelen frekansları varsa N 1 +N 2 +…+N k =N , o zaman
Genel standart sapma (standart) genel varyansın karekökü denir
Örnek varyansözelliğin gözlenen değerlerinin ortalama değerden sapmalarının karelerinin aritmetik ortalaması olarak adlandırılır.
Farklı değerler için x 1 , x 2 , x 3 , ..., x n hacminin örnek popülasyonunun işaretinin n elimizde:
Nitelik değerlerinin karşılık gelen frekansları varsa n 1 +n 2 +…+n k = n, o zaman
Örnek standart sapma (standart)örnek varyansının karekökü denir.
Örnek:
Örnekleme seti dağıtım tablosu tarafından verilmektedir. Örnek varyansı bulun.
Çözüm:
teorem: Varyans, özellik değerlerinin karelerinin ortalaması ile toplam ortalamanın karesi arasındaki farka eşittir.
Örnek:
Bu dağılımın varyansını bulun.
Çözüm:
8. Dağıtım parametrelerinin istatistiksel tahminleri
Genel popülasyonun bir örneklem tarafından incelenmesine izin verin. Bu durumda, tahmini olarak hizmet eden bilinmeyen Q parametresinin yalnızca yaklaşık bir değerini elde etmek mümkündür. Tahminlerin bir örnekten diğerine değişebileceği açıktır.
İstatistiksel değerlendirmeQ* teorik dağılımın bilinmeyen parametresine, örneğin gözlenen değerlerine bağlı olan f fonksiyonu denir. Bir örnekten bilinmeyen parametrelerin istatistiksel olarak tahmin edilmesinin görevi, bu parametrelerin gerçek, bilinmeyen gerçek değerlerini, bu parametrelerin değerlerini en doğru yaklaşık değerleri verecek olan mevcut istatistiksel gözlem verilerinden böyle bir fonksiyon oluşturmaktır.
İstatistiksel tahminler, sağlanma şekline (sayı veya aralık) bağlı olarak nokta ve aralığa bölünür.
Nokta tahmini, istatistiksel tahmin olarak adlandırılır. Q *=f (x 1 , x 2 , ..., x n) parametresinin bir değeri tarafından belirlenen teorik dağılımın Q parametresi, buradax 1 , x 2 , ...,xn- belirli bir örneğin X nicel niteliğine ilişkin ampirik gözlemlerin sonuçları.
Farklı örneklerden elde edilen bu tür parametre tahminleri çoğu zaman birbirinden farklıdır. Mutlak fark /Q *-Q / olarak adlandırılır örnekleme hatası (tahmin).
İstatistiksel tahminlerin tahmin edilen parametreler hakkında güvenilir sonuçlar verebilmesi için bunların yansız, verimli ve tutarlı olması gerekmektedir.
Puan Tahmini Matematiksel beklentisi tahmin edilen parametreye eşit (eşit değil) olana denir. kaydırılmamış (kaydırılmış). M(Q *)=Q .
Fark M( Q *)-Q denir önyargı veya sistematik hata. Tarafsız tahminler için sistematik hata 0'dır.
verimli değerlendirme Belirli bir örneklem büyüklüğü n için mümkün olan en küçük varyansa sahip olan Q *: D min(n = const ). Etkin tahmin edici, diğer yansız ve tutarlı tahmin edicilere kıyasla en küçük yayılıma sahiptir.
Zenginböyle bir istatistik denir değerlendirme Q *, n içintahmin edilen parametreye olasılık eğilimi gösterir Q , yani örneklem büyüklüğünün artmasıyla n tahmin, parametrenin gerçek değerine olasılık olarak eğilim gösterir. Q.
Tutarlılık gereksinimi, büyük sayılar yasasıyla tutarlıdır: incelenen nesne hakkında ne kadar çok başlangıç bilgisi olursa, sonuç o kadar doğru olur. Örnek boyutu küçükse, parametrenin nokta tahmini ciddi hatalara yol açabilir.
Hiç Örnek hacimn) sıralı bir set olarak düşünülebilirx 1 , x 2 , ...,xn bağımsız, aynı şekilde dağılmış rastgele değişkenler.
Farklı hacimli numuneler için numune araçları n aynı popülasyondan farklı olacaktır. Yani örnek ortalaması rastgele bir değişken olarak kabul edilebilir, yani örnek ortalamasının dağılımı ve sayısal özellikleri hakkında konuşabiliriz.
Örnek ortalama, istatistiksel tahminlere dayatılan tüm gereksinimleri karşılar, yani. popülasyon ortalamasının tarafsız, verimli ve tutarlı bir tahminini verir.
Kanıtlanabilir ki. Bu nedenle, örnek varyansı, genel varyansın önyargılı bir tahminidir ve ona hafife alınmış bir değer verir. Yani küçük bir örneklem büyüklüğü ile sistematik bir hata verecektir. Tarafsız, tutarlı bir tahmin için miktarı almak yeterlidir. düzeltilmiş varyans olarak adlandırılır. yani
Pratikte, genel varyansı tahmin etmek için, düzeltilmiş varyans şu durumlarda kullanılır: n < 30. Diğer durumlarda ( n >30) sapma pek fark edilmez. Bu nedenle büyük değerler için n yanlılık hatası ihmal edilebilir.
Göreceli frekansın da kanıtlanabilir.n i / n, tarafsız ve tutarlı bir olasılık tahminidir P(X=x ben ). ampirik dağıtım fonksiyonu F*(x ) teorik dağılım fonksiyonunun tarafsız ve tutarlı bir tahminidir F(x)=P(X< x ).
Örnek:
Örnek tablodan ortalama ve varyansın yansız tahminlerini bulun.
| x ben |
|||
| ben |
Çözüm:
Örnek boyutu n=20.
Matematiksel beklentinin tarafsız tahmini, örnek ortalamadır.
Varyansın yansız tahminini hesaplamak için önce örnek varyansını buluruz:
Şimdi tarafsız tahmini bulalım:
9. Dağıtım parametrelerinin aralık tahminleri
Aralık, iki sayısal değer tarafından belirlenen istatistiksel bir tahmindir - incelenen aralığın uçları.
Sayı> 0, nerede | S - S*|< , aralık tahmininin doğruluğunu karakterize eder.
güveniliraranan Aralık , belirli bir olasılıklabilinmeyen parametre değerini kapsar Q . Tüm olası parametre değerleri kümesine güven aralığını tamamlama Q aranan kritik bölge. Kritik bölge, güven aralığının yalnızca bir tarafında yer alıyorsa, güven aralığı denir. tek taraflı: sol taraflı, kritik bölge yalnızca solda mevcutsa ve sağlak sağda olmadıkça. Aksi takdirde, güven aralığı denir iki taraflı.
Güvenilirlik veya güven düzeyi, Q tahminleri (Q kullanarak *) aşağıdaki eşitsizliğin gerçekleşme olasılığını adlandırın: | S - S*|< .
Çoğu zaman, güven olasılığı önceden belirlenir (0.95; 0.99; 0.999) ve buna bire yakın olması şartı getirilir.
olasılıkaranan hata olasılığı veya önem düzeyi.
izin | S - S*|< , sonra. Bunun anlamı, bir olasılıklaparametrenin gerçek değerinin olduğu iddia edilebilir. Q aralığa ait. Sapma ne kadar küçükse, daha doğru tahmin.
Güven aralığının sınırlarına (uçlarına) denir. güven sınırları veya kritik sınırlar.
Güven aralığı sınırlarının değerleri, parametrenin dağılım yasasına bağlıdır. Q*.
sapma değerigüven aralığının genişliğinin yarısı denir değerlendirme doğruluğu.
Güven aralıkları oluşturmaya yönelik yöntemler ilk olarak Amerikalı istatistikçi Y. Neumann tarafından geliştirilmiştir. Tahmin Doğruluğu, güven olasılığı ve örnek boyutu n birbirine bağlı. Bu nedenle, iki miktarın belirli değerlerini bilerek, her zaman üçüncüyü hesaplayabilirsiniz.
Standart sapma biliniyorsa, normal dağılımın matematiksel beklentisini tahmin etmek için güven aralığını bulma.
Normal dağılım yasasına tabi olarak genel popülasyondan bir örneklem yapalım. Genel standart sapmanın bilinmesine izin verin, ancak teorik dağılımın matematiksel beklentisi bilinmiyor a().
Aşağıdaki formül geçerlidir:
Şunlar. belirtilen sapma değerine görebilinmeyen genel ortalamanın hangi olasılıkla aralığa ait olduğunu bulmak mümkündür.. Ve tam tersi. Formülden, örneklem büyüklüğündeki bir artış ve güven olasılığının sabit bir değeri ile, değerin- azalır, yani tahminin doğruluğu artar. Güvenilirliğin artmasıyla (güven olasılığı), değer-artırır, yani tahminin doğruluğu azalır.
Örnek:
Testler sonucunda -25, 34, -20, 10, 21 değerleri elde edilmiştir. 2 standart sapma ile normal dağılım yasasına uydukları bilinmektedir. matematiksel beklenti a. Bunun için %90'lık bir güven aralığı çizin.
Çözüm:
Yansız tahmini bulalım
O zamanlar
a için güven aralığı şu şekildedir: 4 - 1.47< a< 4+ 1,47 или 2,53 < a < 5, 47
Standart sapma bilinmiyorsa, normal dağılımın matematiksel beklentisini tahmin etmek için güven aralığını bulma.
Genel nüfusun normal dağılım yasasına tabi olduğu bilinsin, burada a ve. Güvenilirlik ile Güven Aralığı Kapsamında Doğruluka parametresinin gerçek değeri, bu durumda, aşağıdaki formülle hesaplanır:
, n, örnek boyutudur, , - Öğrenci katsayısı (verilen değerlerden bulunmalıdır n ve "Öğrenci dağılımının kritik noktaları" tablosundan).
Örnek:
Testler sonucunda -35, -32, -26, -35, -30, -17 değerleri elde edilmiştir. Normal dağılım yasasına uydukları bilinmektedir. 0,9 güven düzeyi ile popülasyon ortalaması a için güven aralığını bulun.
Çözüm:
Yansız tahmini bulalım.
Bulalım.
O zamanlar
Güven aralığı formu alacak(-29.2 - 5.62; -29.2 + 5.62) veya (-34.82; -23.58).
Normal bir dağılımın varyansı ve standart sapması için güven aralığını bulma
Normal yasaya göre dağıtılan bazı genel değerler kümesinden rastgele bir hacim örneği alınsın.n < Örnek varyanslarının hesaplandığı 30: yanlıve düzeltildi s 2. Daha sonra belirli bir güvenilirliğe sahip aralık tahminlerini bulmak içingenel dağılım içinDgenel standart sapmaaşağıdaki formüller kullanılır.
veya,
değerler- kritik noktaların değer tablosunu kullanarak bulunPearson dağılımları.
Varyansın güven aralığı, eşitsizliğin tüm parçalarının karesi alınarak bu eşitsizliklerden bulunur.
Örnek:
15 cıvatanın kalitesi kontrol edildi. Üretimlerindeki hatanın normal dağılım yasasına ve örnek standart sapmaya tabi olduğunu varsayarsak5 mm'ye eşit, güvenilirlikle belirleyinbilinmeyen parametre için güven aralığı
Aralığın sınırlarını bir çift eşitsizlik olarak temsil ediyoruz:
Varyans için iki taraflı güven aralığının uçları, ilgili tablo kullanılarak belirli bir güven düzeyi ve örneklem boyutu için aritmetik işlemler yapılmadan belirlenebilir (Serbestlik ve güvenilirlik derecesi sayısına bağlı olarak varyans için güven aralığı sınırları ). Bunu yapmak için tablodan elde edilen aralığın uçları düzeltilmiş varyans s 2 ile çarpılır..
Örnek:
Önceki sorunu farklı bir şekilde çözelim.
Çözüm:
Düzeltilmiş varyansı bulalım:
"Serbestlik ve güvenilirlik derecelerinin sayısına bağlı olarak varyans için güven aralığı sınırları" tablosuna göre, varyans için güven aralığının sınırlarını şu anda buluyoruz.k=14 ve: alt limit 0.513 ve üst limit 2.354.
Elde edilen sınırları şu şekilde çarpın:s 2 ve kökü çıkarın (çünkü varyans için değil, standart sapma için bir güven aralığına ihtiyacımız var).
Örneklerden de anlaşılacağı gibi, güven aralığının değeri, oluşturulma yöntemine bağlıdır ve yakın fakat farklı sonuçlar verir.
Yeterince büyük boyutlu numuneler için (n>30) genel standart sapma için güven aralığının sınırları aşağıdaki formülle belirlenebilir: - tablo haline getirilmiş ve ilgili referans tablosunda verilen bazı numaralar.
1- q<1, то формула имеет вид:
Örnek:
Önceki sorunu üçüncü şekilde çözelim.
Çözüm:
Daha önce bulundus= 5,17. q(0.95; 15) = 0.46 - tabloya göre buluyoruz.
O zamanlar:
Araştırma genellikle bazı varsayımlarla başlar ve gerçeklerin dahil edilmesiyle doğrulama gerektirir. Bu varsayım - bir hipotez - belirli bir nesne kümesindeki fenomenlerin veya özelliklerin bağlantısıyla ilgili olarak formüle edilir.
Bu tür varsayımları gerçekler üzerinde test etmek için taşıyıcılarının karşılık gelen özelliklerini ölçmek gerekir. Ancak tüm ergenlerde saldırganlığı ölçmek imkansız olduğu gibi, tüm kadınlarda ve erkeklerde kaygıyı ölçmek imkansızdır. Bu nedenle, bir çalışma yürütürken, ilgili insan popülasyonlarının yalnızca nispeten küçük bir temsilci grubuyla sınırlıdırlar.
Nüfus- bu, bir araştırma hipotezinin formüle edildiği tüm nesneler kümesidir.
Örneğin tüm erkekler; veya tüm kadınlar; veya bir şehrin tüm sakinleri. Araştırmacının çalışmanın sonuçlarına dayanarak sonuç çıkaracağı genel popülasyonlar, örneğin belirli bir okulun tüm birinci sınıf öğrencileri gibi sayıca daha küçük ve daha mütevazı olabilir.
Bu nedenle, genel nüfus, sayıca sonsuz olmasa da, kural olarak, sürekli araştırma için erişilemeyen çok sayıda potansiyel denektir.
Örnek veya örnek popülasyon- bu, özelliklerini incelemek için genel popülasyondan özel olarak seçilen, sınırlı sayıda (psikolojide - denekler, katılımcılar) bir grup nesnedir. Buna göre, genel popülasyonun özelliklerinin bir örnek üzerinde çalışmasına denir. seçici araştırma Hemen hemen tüm psikolojik çalışmalar seçicidir ve sonuçları genel popülasyon için geçerlidir.
Böylece, hipotez formüle edildikten ve karşılık gelen genel popülasyonlar belirlendikten sonra, araştırmacı örneği organize etme sorunuyla karşı karşıya kalır. Örnek, örnek çalışmanın sonuçlarının genelleştirilmesinin gerekçelendirileceği şekilde olmalıdır - genelleme, bunların genel popülasyona dağılımı. Çalışmanın sonuçlarının geçerliliği için ana kriterler— bunlar, örneğin temsil edilebilirliği ve (ampirik) sonuçların istatistiksel geçerliliğidir.
Örnek temsiliyet- başka bir deyişle, temsili, örneğin genel popülasyondaki değişkenlikleri açısından, incelenen fenomenleri oldukça tam olarak temsil etme yeteneğidir.
Tabii ki, yalnızca genel nüfus, incelenen olgunun tüm kapsamı ve değişkenlik nüansları ile tam bir resmini verebilir. Bu nedenle, temsiliyet her zaman örneklemin sınırlı olduğu ölçüde sınırlıdır. Araştırmanın bulgularının genelleştirilmesinin sınırlarının belirlenmesinde temel ölçüt ise örneklemin temsil edilebilirliğidir. Bununla birlikte, araştırmacı için yeterli temsili bir örneklem elde etmeyi mümkün kılan teknikler vardır (Bu teknikler "Deneysel Psikoloji" dersinde işlenir).
İlk ve ana teknik basit bir rastgele (rastgele) seçimdir. Nüfusun her bir üyesinin örneğe dahil olma şansının eşit olmasını sağlamayı içerir. Rastgele seçim, genel popülasyonun en çeşitli temsilcilerinin örneğine girme imkanı sağlar. Aynı zamanda, seçimdeki herhangi bir düzenliliğin görünümünü dışlamak için özel önlemler alınır. Ve bu, sonunda, örnekte, incelenen mülkün, hepsinde olmasa da, mümkün olan maksimum çeşitliliğinde temsil edileceğini ummamızı sağlar.
Temsil ediciliği sağlamanın ikinci yolu, tabakalı rastgele seçim veya genel popülasyonun özelliklerine göre seçimdir. İncelenen mülkün değişkenliğini etkileyebilecek niteliklerin (bu, cinsiyet, gelir düzeyi veya eğitim vb. olabilir) ön belirlemesini içerir. Daha sonra genel popülasyonda bu niteliklerde farklılık gösteren grupların (katmanların) sayısının yüzde oranı belirlenir ve örneklemde karşılık gelen grupların aynı yüzde oranı sağlanır. Ayrıca, örneklemin her bir alt grubunda denekler basit rastgele seçim ilkesine göre seçilir.
İstatistiksel geçerlilik, veya istatistiksel anlamlılık, çalışmanın sonuçları istatistiksel çıkarım yöntemleri kullanılarak belirlenir.
Çalışmanın sonuçlarından elde edilen kesin sonuçlarla karar verirken hata yapmaya karşı sigortalı mıyız? Tabii ki değil. Ne de olsa kararlarımız, psikolojik bilgi düzeyimizin yanı sıra örneklem popülasyonunun bir çalışmasının sonuçlarına dayanmaktadır. Hatalardan tamamen bağışık değiliz. İstatistikte, bu tür hataların 1000'den birinden fazla olmaması durumunda kabul edilebilir olarak kabul edilir (hata olasılığı α = 0.001 veya doğru sonucun güven olasılığının ilişkili değeri p = 0.999); 100 üzerinden bir durumda (hata olasılığı α = 0.01 veya doğru sonucun güven olasılığının ilişkili değeri p = 0.99) veya 100 üzerinden beş durumda (hata olasılığı α = 0.05 veya ilgili güven olasılığının ilişkili değeri) doğru çıktı p=0.95). Psikolojide karar vermenin alışılmış olduğu son iki düzeydedir.
Bazen istatistiksel anlamlılıktan bahsederken, "önem düzeyi" (α olarak gösterilir) kavramı kullanılır. p ve α'nın sayısal değerleri 1.000'e kadar birbirini tamamlar - tam bir olay dizisi: ya doğru sonuca vardık ya da bir hata yaptık. Bu seviyeler hesaplanmaz, belirlenir. Önem düzeyi, kesişimi bu olaydan rastgele olmayan olarak bahsetmemize izin verecek bir tür "kırmızı" çizgi olarak anlaşılabilir. Her yetkin bilimsel rapor veya yayında, çıkarılan sonuçlara, sonuçların yapıldığı p veya α değerlerinin bir göstergesi eşlik etmelidir.
İstatistiksel çıkarım yöntemleri "Matematiksel İstatistik" dersinde ayrıntılı olarak tartışılmaktadır. Şimdilik, yalnızca numaraya belirli gereksinimler yüklediklerini veya örnek boyut.
Ne yazık ki, gerekli örneklem büyüklüğünün ön tespiti konusunda kesin bir tavsiye bulunmamaktadır. Ayrıca, araştırmacı genellikle gerekli ve yeterli sayıdaki soruya çok geç bir cevap alır - ancak daha önce incelenen örneğin verilerini analiz ettikten sonra. Bununla birlikte, en genel öneriler formüle edilebilir:
1. Bir teşhis tekniği geliştirirken en büyük örneklem büyüklüğüne ihtiyaç vardır - 200 ila 1000-2500 kişi.
2. 2 numunenin karşılaştırılması gerekiyorsa toplam sayısı en az 50 kişi olmalıdır; karşılaştırılan örneklerin sayısı yaklaşık olarak aynı olmalıdır.
3. Herhangi bir özellik arasındaki ilişki araştırılıyorsa örneklem büyüklüğü en az 30-35 kişi olmalıdır.
4. Daha fazla değişkenlikİncelenen mülkün, örnek boyutu ne kadar büyükse o kadar büyük olmalıdır. Bu nedenle, örneğin cinsiyete, yaşa vb. göre örneğin homojenliği artırılarak değişkenlik azaltılabilir. Bu, elbette, sonuçların genelleştirilmesi olasılığını azaltır.
Bağımlı ve bağımsız örnekler. Tipik bir araştırma durumu, araştırmacının ilgisini çeken bir özelliğin daha fazla karşılaştırma amacıyla iki veya daha fazla örnek üzerinde çalışılmasıdır. Bu numuneler, organizasyon prosedürlerine bağlı olarak farklı oranlarda olabilir. Bağımsız örnekler Bir örneğin herhangi bir deneğinin seçilme olasılığının, başka bir örneğe ait herhangi bir deneğin seçimine bağlı olmaması gerçeğiyle karakterize edilir. Karşı, bağımlı örnekler Bir örneğin her bir öznesinin, başka bir örneklemden bir özne ile belirli bir kriter tarafından eşleşmesi ile karakterize edilir.
Genel durumda, bağımlı örnekler, karşılaştırılan örneklerde ikili bir denek seçimini ve bağımsız numuneleri - bağımsız bir denek seçimini içerir.
“Kısmen bağımlı” (veya “kısmen bağımsız”) örneklere izin verilmediğine dikkat edilmelidir: bu, temsil edilebilirliklerini öngörülemeyen bir şekilde ihlal eder.
Sonuç olarak, psikolojik araştırmanın iki paradigmasının ayırt edilebileceğine dikkat çekiyoruz.
Lafta R-metodolojisi belirli bir özelliğin (psikolojik) bir etkinin, faktörün veya başka bir özelliğin etkisi altındaki değişkenliğinin incelenmesini içerir. Örnek, bir dizi konu.
Başka bir yaklaşım Q-metodolojisi,çeşitli uyaranların (koşullar, durumlar vb.) etkisi altında konunun (tek) değişkenliğinin incelenmesini içerir. O zaman duruma karşılık gelir örnek bir uyaran kümesidir.