 ورود
ورودچکیده: روش نمونه گیری در آمار. نمونه (جمعیت نمونه)
تحقیقات آماری بسیار کار بر و پرهزینه است، بنابراین ایده جایگزینی مشاهده پیوسته با مشاهده انتخابی مطرح شد.
هدف اصلی مشاهده غیرمستمر بدست آوردن ویژگی های جامعه آماری مورد مطالعه برای قسمت مورد بررسی است.
مشاهده انتخابیروشی از تحقیقات آماری است که در آن شاخص های عمومی جامعه تنها برای یک بخش بر اساس مفاد انتخاب تصادفی تعیین می شود.
با روش نمونه گیری، تنها بخش معینی از جامعه مورد مطالعه مورد مطالعه قرار می گیرد و جامعه آماری مورد مطالعه، جامعه عمومی نامیده می شود.
جامعه نمونه یا به طور ساده یک نمونه را می توان بخشی از واحدهای انتخاب شده از جامعه عمومی نامید که مورد تحقیق آماری قرار می گیرد.
مقدار روش نمونه گیری: چه زمانی حداقل تعدادواحدهای مورد مطالعه، تحقیقات آماری در بازههای زمانی کوتاهتر و با کمترین هزینه و نیروی کار انجام میشود.
در یک جمعیت عمومی، نسبت واحدهایی که دارای ویژگی مورد مطالعه هستند، نسبت کلی نامیده می شود ر)و مقدار متوسط صفت متغیر مورد مطالعه، میانگین کلی است (نشان داده شده است ایکس).
در یک جامعه نمونه، نسبت مشخصه مورد مطالعه را نسبت نمونه یا بخشی (که با w نشان داده می شود) می گویند، مقدار متوسط در نمونه برابر است با میانگین نمونه
اگر در طول معاینه تمام قوانین آن سازمان علمی، سپس روش نمونه گیری نتایج نسبتاً دقیقی به دست می دهد و بنابراین استفاده از این روش برای بررسی داده های مشاهده مداوم توصیه می شود.
این روش در آمارهای دولتی و غیردستگاهی رواج یافته است، زیرا هنگام مطالعه حداقل واحدهای مورد مطالعه، امکان مطالعه کامل و دقیق را فراهم می کند.
جامعه آماری مورد مطالعه شامل واحدهایی با ویژگی های متفاوت است. ترکیب جامعه نمونه ممکن است با ترکیب جامعه متفاوت باشد؛ این اختلاف بین ویژگی های نمونه و جامعه خطای نمونه گیری را ایجاد می کند.
خطاهای ذاتی در مشاهده نمونه، اندازه اختلاف بین داده های مشاهده نمونه و کل جامعه را مشخص می کند. خطاهایی که در هنگام مشاهده نمونه ایجاد می شوند، خطاهای نمایندگی نامیده می شوند و به تصادفی و سیستماتیک تقسیم می شوند.
اگر جامعه نمونه به دلیل ماهیت ناقص مشاهدات، کل جامعه را به طور دقیق بازتولید نکند، به این خطاهای تصادفی گفته می شود و اندازه آنها با دقت کافی بر اساس قانون تعیین می شود. اعداد بزرگو نظریه احتمال
خطاهای سیستماتیک در نتیجه نقض اصل تصادفی بودن در انتخاب واحدهای جمعیتی برای مشاهده به وجود می آیند.
2. انواع و طرح های انتخاب
اندازه خطای نمونه گیری و روش های تعیین آن به نوع و طرح انتخاب بستگی دارد.
چهار نوع انتخاب جمعیت از واحدهای مشاهده وجود دارد:
1) تصادفی؛
2) مکانیکی؛
3) معمولی؛
4) سریال (تودرتو).
انتخاب تصادفی– متداول ترین روش انتخاب در یک نمونه تصادفی است که به آن روش قرعه کشی نیز می گویند که در آن برای هر واحد از جامعه آماری یک بلیط با شماره سریال تهیه می شود.
سپس تعداد واحدهای مورد نیاز جامعه آماری به صورت تصادفی انتخاب می شود. در این شرایط، هر یک از آنها احتمال یکسانی برای قرار گرفتن در نمونه را دارند، به عنوان مثال، قرعه کشی های برنده، زمانی که از تعداد کل بلیط های صادر شده، قسمت خاصی از اعدادی که برنده ها روی آنها اتفاق می افتد به طور تصادفی انتخاب می شود. در این صورت برای همه اعداد فرصت برابر برای درج نمونه در نظر گرفته شده است.
انتخاب مکانیکی- این روشی است که کل جامعه بر اساس یک معیار تصادفی به گروههایی با حجم همگن تقسیم میشود، سپس از هر گروه فقط یک واحد گرفته میشود، همه واحدهای جامعه آماری مورد مطالعه به ترتیب خاصی از قبل چیده شدهاند، اما بسته به حجم نمونه، تعداد واحدهای مورد نیاز به صورت مکانیکی در یک بازه زمانی مشخص انتخاب می شود.
انتخاب معمولی -این روشی است که در آن جامعه آماری مورد مطالعه بر اساس یک ویژگی ضروری و معمولی به گروههای کیفی همگن و از یک نوع تقسیم میشود، سپس از هر یک از این گروهها تعداد معینی واحد بهطور تصادفی متناسب با وزن مخصوص انتخاب میشود. از گروه در کل جمعیت.
انتخاب معمولی نتایج دقیق تری می دهد، زیرا شامل نمایندگان همه گروه های معمولی در نمونه است.
انتخاب سریال (خوشه ای).کل گروه ها (سری ها، لانه ها) که به صورت تصادفی یا مکانیکی انتخاب شده اند در معرض انتخاب هستند. برای هر گروه یا سری، مشاهده مداوم انجام می شود و نتایج به کل جمعیت منتقل می شود.
دقت نمونه به طرح نمونه گیری نیز بستگی دارد. نمونه برداری را می توان بر اساس طرح نمونه گیری مکرر یا غیر تکراری انجام داد.
انتخاب مجددهر واحد یا سری انتخاب شده به کل جامعه برگردانده می شود و می تواند مجدداً وارد نمونه شود. این به اصطلاح طرح توپ برگشتی است.
انتخاب غیر تکراریهر واحد بررسی شده حذف می شود و به جمعیت بازگردانده نمی شود، بنابراین دوباره بررسی نمی شود. این طرح را توپ برگشت ناپذیر می نامند.
نمونه گیری غیر تکراری نتایج دقیق تری به دست می دهد زیرا با حجم نمونه یکسان، مشاهده تعداد بیشتری از واحدهای جامعه مورد مطالعه را پوشش می دهد.
انتخاب ترکیبیممکن است یک یا چند مرحله را طی کند. اگر یکبار واحدهای انتخاب شده از جامعه مورد مطالعه قرار گیرند، یک نمونه تک مرحله ای نامیده می شود.
نمونه ای چند مرحله ای نامیده می شود که انتخاب جامعه در مراحل، مراحل متوالی صورت گیرد و هر مرحله، مرحله انتخاب واحد گزینش خاص خود را داشته باشد.
نمونه گیری چند مرحله ای - در تمام مراحل نمونه گیری واحد نمونه گیری یکسان حفظ می شود، اما چندین مرحله، مراحل بررسی نمونه گیری انجام می شود که در وسعت برنامه نظرسنجی و حجم نمونه متفاوت است.
ویژگی های پارامترهای جمعیت عمومی و نمونه با نمادهای زیر نشان داده می شود:
ن- حجم جمعیت عمومی؛
n- اندازهی نمونه؛
ایکس- میانگین عمومی؛
ایکس- میانگین نمونه؛
آر- سهم عمومی؛
w –سهم نمونه;
2- پراکندگی عمومی (واریانس مشخصه در جمعیت عمومی).
2 - واریانس نمونه با همان مشخصه.
؟- میانگین انحراف معیاردر جمعیت عمومی؛
- انحراف معیار در نمونه.
3. خطاهای نمونه گیری
هر واحد در یک مشاهده نمونه باید فرصتی برابر با دیگران برای انتخاب داشته باشد - این اساس یک نمونه تصادفی مناسب است.
نمونه گیری تصادفی مناسب انتخاب واحدها از کل جمعیت با قرعه کشی یا سایر روش های مشابه است.
اصل تصادفی بودن این است که گنجاندن یا حذف یک مورد از یک نمونه نمی تواند تحت تأثیر هیچ عامل دیگری غیر از شانس باشد.
اشتراک نمونهنسبت تعداد واحدهای جامعه نمونه به تعداد واحدهای جامعه عمومی است:
انتخاب تصادفی مناسب در شکل خالص آن در میان سایر انواع انتخاب اصلی است؛ اصول اساسی مشاهده آماری انتخابی را در بر می گیرد و اجرا می کند.
دو نوع اصلی از شاخص های عمومی که در روش نمونه گیری استفاده می شوند عبارتند از میانگین مقدار یک مشخصه کمی و مقدار نسبی یک مشخصه جایگزین.
کسر نمونه (w) یا خاصیت، با نسبت تعداد واحدهای دارای ویژگی مورد مطالعه تعیین می شود. متربه تعداد کل واحدهای جامعه نمونه (n):
برای مشخص کردن قابلیت اطمینان شاخصهای نمونه، بین میانگین و حداکثر خطای نمونهگیری تمایز گذاشته میشود.
خطای نمونه گیری که خطای نمایندگی نیز نامیده می شود، تفاوت بین نمونه مربوطه و ویژگی های کلی است:
?x =|x – x|;
?w =|x – p|.
فقط مشاهدات نمونه مشمول خطای نمونه گیری هستند.
میانگین نمونه و نسبت نمونهمتغیرهای تصادفی هستند که می گیرند معانی مختلفبسته به واحدهای جامعه آماری مورد مطالعه که در نمونه گنجانده شده است. بر این اساس، خطاهای نمونه گیری نیز متغیرهای تصادفی هستند و می توانند مقادیر متفاوتی نیز به خود بگیرند. بنابراین، میانگین را تعیین کنید خطاهای احتمالی- میانگین خطای نمونه گیری
میانگین خطای نمونه گیری بر اساس حجم نمونه تعیین می شود: هر چه تعداد آنها بزرگتر باشد، سایر موارد برابر باشند، میانگین خطای نمونه برداری کوچکتر است. با پوشش تعداد فزاینده ای از واحدهای جمعیت عمومی با یک نظرسنجی نمونه، کل جمعیت عمومی را بیشتر و دقیق تر توصیف می کنیم.
میانگین خطای نمونه گیری به درجه تنوع مشخصه مورد مطالعه بستگی دارد؛ به نوبه خود، درجه تنوع با پراکندگی مشخص می شود؟ 2 یا w(l - w)- برای علامت جایگزین هر چه تنوع و پراکندگی صفت کوچکتر باشد، میانگین خطای نمونه کوچکتر است و بالعکس.
در صورت نمونه گیری تصادفی مکرر، میانگین خطاها به صورت نظری با استفاده از فرمول های زیر محاسبه می شود:
1) برای یک مشخصه کمی متوسط:
جایی که؟ 2- مقدار متوسط پراکندگی یک مشخصه کمی.
2) برای یک سهم (ویژگی جایگزین):
بنابراین واریانس یک صفت در جمعیت چیست؟ 2 دقیقاً مشخص نیست، در عمل آنها از مقدار پراکندگی S 2 محاسبه شده برای جامعه نمونه بر اساس قانون اعداد بزرگ استفاده می کنند، که طبق آن جامعه نمونه، با حجم نمونه به اندازه کافی بزرگ، کاملاً دقیق بازتولید می کند. ویژگی های جمعیت عمومی
فرمول میانگین خطای نمونه گیری برای نمونه گیری مجدد تصادفی به شرح زیر است. برای اندازه متوسطمشخصه کمی: واریانس عمومی از طریق واریانس انتخابی با رابطه زیر بیان می شود:
که در آن S 2 مقدار پراکندگی است.
نمونه برداری مکانیکی- این انتخاب واحدها در یک جمعیت نمونه از جمعیت عمومی است که بر اساس یک معیار خنثی به گروه های مساوی تقسیم می شود. به گونه ای انجام می شود که از هر گروه فقط یک واحد برای نمونه انتخاب می شود.
در نمونهگیری مکانیکی، واحدهای جامعه آماری مورد مطالعه ابتدا به ترتیب معینی مرتب میشوند و پس از آن تعداد معینی از واحدها به صورت مکانیکی در یک بازه زمانی مشخص انتخاب میشوند. در این حالت، اندازه فاصله در جامعه برابر با مقدار معکوس نسبت نمونه است.
وقتی به اندازه کافی جمعیت زیادانتخاب مکانیکی از نظر دقت نتایج نزدیک به خودتصادفی است بنابراین برای تعیین میانگین خطای نمونه گیری مکانیکی از فرمول های نمونه گیری غیرتکراری خود تصادفی استفاده می شود.
برای انتخاب واحدها از یک جمعیت ناهمگن، از نمونه به اصطلاح معمولی استفاده می شود؛ زمانی استفاده می شود که تمام واحدهای جمعیت عمومی را بتوان با توجه به ویژگی هایی که شاخص های مورد مطالعه به آن بستگی دارد، به چندین گروه از نظر کیفی همگن و مشابه تقسیم کرد.
سپس، از هر گروه معمولی، انتخاب فردی واحدها در جامعه نمونه با استفاده از یک نمونه کاملا تصادفی یا مکانیکی انجام می شود.
معمولاً هنگام مطالعه جمعیت های آماری پیچیده از نمونه گیری استفاده می شود.
نمونه گیری معمولی نتایج دقیق تری می دهد. تایپ کردن جمعیت عمومی، نمایندگی چنین نمونه ای را تضمین می کند، نمایش هر گروه گونه شناسی در آن، که امکان حذف تأثیر پراکندگی بین گروهی بر میانگین خطای نمونه گیری را فراهم می کند. بنابراین، هنگام تعیین میانگین خطای یک نمونه معمولی، میانگین واریانس های درون گروهی به عنوان شاخص تغییرات عمل می کند.
نمونهگیری سریالی شامل انتخاب تصادفی از یک جمعیت عمومی از گروههای مساوی است تا همه واحدهای این گروهها بدون استثنا مورد مشاهده قرار گیرند.
از آنجایی که در داخل گروه ها (سری ها) همه واحدها بدون استثنا مورد بررسی قرار می گیرند، میانگین خطای نمونه گیری (هنگام انتخاب سری های مساوی) فقط به پراکندگی بین گروهی (بین سری) بستگی دارد.
4. روش های انتشار نتایج نمونه به جمعیت عمومی
ویژگی های جامعه بر اساس نتایج نمونه، هدف نهایی مشاهده نمونه است.
روش نمونه گیری برای به دست آوردن ویژگی های جامعه با توجه به شاخص های نمونه خاص استفاده می شود. بسته به اهداف مطالعه، این کار با محاسبه مجدد مستقیم شاخص های نمونه برای جمعیت عمومی یا با محاسبه ضرایب تصحیح انجام می شود.
روش محاسبه مجدد مستقیم این است که با آن شاخص های سهم نمونه wیا متوسط ایکسبا در نظر گرفتن خطای نمونه گیری، برای جمعیت عمومی اعمال شود.
روش ضرایب تصحیح زمانی استفاده می شود که هدف روش نمونه گیری شفاف سازی نتایج حسابداری مستمر باشد. این روش برای شفاف سازی داده های سرشماری سالانه دام از جمعیت استفاده می شود.
در تئوری روش نمونهگیری، روشهای مختلف انتخاب و انواع نمونهگیری برای اطمینان از بازنمایی توسعه داده شده است. زیر روش انتخابروش انتخاب واحدها از جمعیت را درک کنید. دو روش انتخاب وجود دارد: تکراری و غیر تکراری. در تکرار کرددر نمونه گیری، هر واحد به طور تصادفی انتخاب شده، پس از بررسی، به جامعه عمومی بازگردانده می شود و با انتخاب بعدی، می توان مجدداً در نمونه قرار داد. این روش انتخاب بر اساس طرح "توپ برگشتی" است: احتمال قرار گرفتن در نمونه برای هر واحد از جامعه بدون توجه به تعداد واحدهای انتخاب شده تغییر نمی کند. در قابل تکراردر نمونه گیری، هر واحد انتخاب شده به صورت تصادفی پس از بررسی به جامعه عمومی بازگردانده نمی شود. این روش انتخاب بر اساس طرح «توپ برگشتنشده» است: با ادامه انتخاب، احتمال قرار گرفتن در نمونه برای هر واحد از جمعیت عمومی افزایش مییابد.
بسته به روش تشکیل جامعه نمونه، موارد اصلی زیر متمایز می شوند: انواع نمونه برداری:
در واقع تصادفی
مکانیکی؛
معمولی (طبقه بندی شده، منطقه بندی شده)؛
سریال (تودرتو)؛
ترکیب شده؛
چند مرحله ای؛
چند فازی؛
متقابل
نمونه گیری در واقع تصادفیبر اساس اصول علمی و قوانین انتخاب تصادفی شکل گرفته است. برای به دست آوردن یک نمونه واقعا تصادفی جمعیتبه طور دقیق به واحدهای نمونه تقسیم می شود و سپس تعداد کافی واحد به ترتیب تصادفی تکراری یا غیر تکراری انتخاب می شوند.
ترتیب تصادفی مانند قرعه کشی است. در عمل، اغلب هنگام استفاده از جداول ویژه اعداد تصادفی استفاده می شود. اگر مثلاً 40 واحد از جمعیتی شامل 1587 واحد انتخاب شود، 40 عدد چهار رقمی که کمتر از 1587 هستند از جدول انتخاب می شوند.
در صورتی که خود نمونه تصادفی به صورت یک نمونه مکرر سازماندهی شود، خطای استاندارد مطابق با فرمول (6.1) محاسبه می شود. با روش نمونه گیری غیر تکراری، فرمول محاسبه خطای استاندارد به صورت زیر خواهد بود:
جایی که 1 - n/ ن- نسبت واحدهایی در جامعه عمومی که در نمونه قرار نگرفتند. از آنجایی که این سهم همیشه است کمتر از یک، پس خطا در انتخاب غیر تکراری، با مساوی بودن سایر موارد، همیشه کمتر از انتخاب مکرر است. سازماندهی انتخاب غیر تکراری آسانتر از انتخاب تکراری است و بسیار بیشتر مورد استفاده قرار می گیرد. با این حال، مقدار خطای استاندارد در طول نمونه برداری غیر تکراری را می توان با استفاده از فرمول ساده تر (5.1) تعیین کرد. چنین جایگزینی در صورتی امکانپذیر است که نسبت واحدهای جمعیت عمومی که در نمونه گنجانده نشدهاند زیاد باشد و بنابراین مقدار آن نزدیک به واحد باشد.
تشکیل یک نمونه مطابق دقیق با قوانین انتخاب تصادفی عملاً بسیار دشوار و گاهی غیرممکن است ، زیرا هنگام استفاده از جداول اعداد تصادفی ، شماره گذاری تمام واحدهای جمعیت عمومی ضروری است. اغلب، جمعیت آنقدر زیاد است که انجام چنین کارهای مقدماتی بسیار دشوار و غیر عملی است، بنابراین در عمل از انواع دیگری از نمونه ها استفاده می شود که هر کدام کاملا تصادفی نیستند. با این حال، آنها به گونه ای سازماندهی شده اند که حداکثر تقریب را با شرایط انتخاب تصادفی تضمین کنند.
وقتی تمیز نمونه برداری مکانیکیکل جمعیت عمومی واحدها ابتدا باید در قالب فهرستی از واحدهای انتخابی ارائه شود که به ترتیبی خنثی با توجه به صفت مورد مطالعه، به عنوان مثال، بر اساس حروف الفبا جمع آوری شده است. سپس لیست واحدهای انتخابی به تعداد واحدهایی که باید انتخاب شوند به قسمتهای مساوی تقسیم می شود. بعدی از قبل قاعده تعیین شده، بدون ارتباط با تنوع مشخصه مورد مطالعه، از هر قسمت از لیست یک واحد انتخاب می شود. این نوع نمونه گیری ممکن است همیشه نمونه گیری تصادفی ارائه نکند و نمونه حاصل ممکن است بایاس باشد. این با این واقعیت توضیح داده می شود که اولاً، ترتیب واحدها در جمعیت عمومی ممکن است عنصری غیر تصادفی داشته باشد. ثانیاً، نمونه گیری از هر بخش از جامعه در صورتی که نقطه مرجع به درستی تعیین نشده باشد نیز می تواند منجر به خطای سوگیری شود. با این حال، در عمل سازماندهی یک نمونه مکانیکی ساده تر از یک نمونه تصادفی است و هنگام انجام بررسی های نمونه از این نوع نمونه گیری بیشتر استفاده می شود. خطای استاندارد در نمونه گیری مکانیکی با فرمول نمونه برداری تصادفی غیر تکراری واقعی (6.2) تعیین می شود.
نمونه معمولی (منطقه بندی شده، طبقه بندی شده).دو هدف دارد:
اطمینان از نمایش در نمونه گروه های معمولی مربوطه از جمعیت عمومی با توجه به ویژگی های مورد علاقه محقق.
افزایش دقت نتایج نظرسنجی نمونه
با یک نمونه معمولی، قبل از شروع تشکیل آن، جمعیت عمومی واحدها به گروه های معمولی تقسیم می شوند. در عین حال بسیار نکته مهماست انتخاب درستعلامت گروه بندی گروه های معمولی انتخاب شده ممکن است دارای تعداد واحدهای انتخابی یکسان یا متفاوتی باشند. در حالت اول، جامعه نمونه با سهم مساوی از انتخاب از هر گروه، در مورد دوم - با سهمی متناسب با سهم آن در جامعه عمومی تشکیل می شود. اگر نمونه ای با سهم مساوی از انتخاب تشکیل شود، اساساً معادل تعدادی نمونه کاملاً تصادفی از جمعیت های کوچکتر است که هر یک از آنها یک گروه معمولی هستند. انتخاب از هر گروه به صورت تصادفی (تکرار یا غیرتکرار) یا مکانیکی انجام می شود. با یک نمونه معمولی، هم با سهم مساوی و هم نابرابر انتخاب، می توان تأثیر تنوع بین گروهی مشخصه مورد مطالعه را بر دقت نتایج آن حذف کرد، زیرا نمایش اجباری هر یک از گروه های معمولی در جامعه نمونه تضمین می شود. آیا خطای استاندارد نمونه به مقدار واریانس کل بستگی دارد؟ 2, و بر روی مقدار میانگین واریانس های گروه؟ 2 . از آنجایی که میانگین واریانس های گروه همیشه کمتر از کل واریانس است، همه چیزهای دیگر برابر هستند، خطای استاندارد یک نمونه معمولی کمتر از خطای استاندارد خود یک نمونه تصادفی خواهد بود.
هنگام تعیین خطاهای استاندارد یک نمونه معمولی، از فرمول های زیر استفاده می شود:
هنگام تکرار روش انتخاب

با روش انتخاب غیر تکراری:

- میانگین واریانس گروه در جامعه نمونه.
نمونه گیری سریالی (خوشه ای).- این نوعی از تشکیل یک جامعه نمونه است که نه واحدهایی که باید بررسی شوند، بلکه گروههایی از واحدها (سری، لانه) به ترتیب تصادفی انتخاب میشوند. در سری انتخاب شده (نست)، تمامی واحدها مورد بررسی قرار می گیرند. سازماندهی و انجام نمونهبرداری سریالی نسبت به نمونهبرداری از واحدهای منفرد عملاً آسانتر است. با این حال، با این نوع نمونهگیری، اولاً نمایش هر یک از سریها تضمین نمیشود و ثانیاً تأثیر تغییرات بین سری مشخصه مورد مطالعه بر نتایج نظرسنجی حذف نمیشود. در صورتی که این تنوع قابل توجه باشد، منجر به افزایش خطای تصادفی بازنمایی خواهد شد. هنگام انتخاب نوع نمونه، محقق باید این شرایط را در نظر بگیرد. خطای استاندارد نمونه برداری سریال با فرمول های زیر تعیین می شود:
با روش انتخاب مکرر -

واریانس میان سری جامعه نمونه کجاست. r- تعداد سری های انتخابی؛
با روش انتخاب غیر تکراری -

جایی که آر- تعداد سری ها در جمعیت
در عمل بسته به هدف و اهداف نظرسنجی های نمونه و همچنین امکان سازماندهی و انجام آنها از روش ها و انواع خاصی از نمونه ها استفاده می شود. اغلب از ترکیبی از روش های انتخاب و انواع نمونه گیری استفاده می شود. چنین نمونه هایی نامیده می شوند ترکیب شده.ترکیب در آن امکان پذیر است ترکیبات مختلف: نمونه برداری مکانیکی و سریالی، معمولی و مکانیکی، سریالی و در واقع تصادفی و ... نمونه برداری ترکیبی برای اطمینان از بیشترین نمایندگی با کمترین هزینه نیروی کار و پول برای سازماندهی و انجام نظرسنجی استفاده می شود.
با یک نمونه ترکیبی، خطای استاندارد نمونه شامل خطاهای هر مرحله است و می تواند به عنوان جذر مجذور خطاهای نمونه های مربوطه تعیین شود. بنابراین، اگر در طول یک نمونه ترکیبی، از نمونه های مکانیکی و نمونه های معمولی به صورت ترکیبی استفاده شود، خطای استاندارد را می توان با فرمول تعیین کرد.

کجا؟1 و؟ 2 به ترتیب خطاهای استاندارد نمونه های مکانیکی و معمولی هستند.
خصوصیات عجیب و غریب استخراج چند مرحله ایاین واقعیت است که جامعه نمونه به تدریج و با توجه به مراحل انتخاب تشکیل می شود. در مرحله اول واحدهای مرحله اول با روش و نوع انتخاب از پیش تعیین شده انتخاب می شوند. در مرحله دوم از هر واحد مرحله اول که در نمونه گنجانده شده است، واحدهای مرحله دوم و ... انتخاب می شوند که تعداد مراحل می تواند بیش از دو باشد. در مرحله آخر جامعه نمونه ای تشکیل می شود که واحدهای آن مورد بررسی قرار می گیرند. بنابراین، به عنوان مثال، برای یک بررسی نمونه از بودجه خانوار، در مرحله اول، موضوعات سرزمینی کشور انتخاب می شوند، در مرحله دوم - مناطق در مناطق منتخب، در مرحله سوم - در هر کدام. شهرداریبنگاه ها یا سازمان ها انتخاب می شوند و در نهایت در مرحله چهارم خانواده ها از بین بنگاه های منتخب انتخاب می شوند.
بنابراین جامعه نمونه در آخرین مرحله تشکیل می شود. نمونهگیری چند مرحلهای نسبت به انواع دیگر انعطافپذیرتر است، اگرچه عموماً نتایج دقیقتری نسبت به نمونه تک مرحلهای با همان اندازه ایجاد میکند. با این حال، یک مزیت مهم دارد و آن این است که قاب نمونه برداری برای انتخاب چند مرحله ای باید در هر مرحله فقط برای آن دسته از واحدهایی ساخته شود که در نمونه گنجانده شده اند، و این بسیار مهم است، زیرا اغلب موارد آماده وجود ندارد. قاب نمونه گیری ساخته شده است.
خطای نمونه گیری استاندارد در نمونه گیری چند مرحله ای برای گروه هایی با اندازه های مختلف با فرمول تعیین می شود

کجا؟1، ?2، ?3 , ... – خطاهای استاندارد در مراحل مختلف;
n1، n2, n3 , .. . - تعداد نمونه ها در مراحل انتخاب مربوطه.
اگر گروه ها از نظر حجم نابرابر باشند، از نظر تئوری نمی توان از این فرمول استفاده کرد. اما اگر نسبت کل انتخاب در تمام مراحل ثابت باشد، در عمل محاسبه با استفاده از این فرمول منجر به تحریف مقدار خطا نمی شود.
ذات نمونه برداری چند فازیشامل این واقعیت است که بر اساس جمعیت نمونه اولیه تشکیل شده، یک نمونه فرعی تشکیل می شود، از این نمونه فرعی، نمونه فرعی بعدی و غیره تشکیل می شود. استفاده از نمونه برداری چند فازی در مواردی که:
برای مطالعه نشانه های مختلفحجم نمونه نابرابر مورد نیاز
تنوع ویژگی های مورد مطالعه یکسان نیست و دقت مورد نیاز متفاوت است.
اطلاعات با جزییات کمتری باید برای همه واحدها در چارچوب نمونه اولیه (فاز اول) جمع آوری شود و اطلاعات دقیق تری برای واحدها در هر فاز بعدی جمع آوری شود.
یکی از مزایای بدون شک نمونه برداری چند فازی این است که اطلاعات به دست آمده در فاز اول می تواند به عنوان اطلاعات اضافی در مراحل بعدی، اطلاعات در فاز دوم به عنوان اطلاعات اضافی در فازهای بعدی و غیره استفاده شود. این استفاده از اطلاعات افزایش می یابد. صحت نتایج حاصل از بررسی نمونه.
هنگام سازماندهی نمونه برداری چند فازی، می توانید از ترکیبی از روش ها و انواع مختلف انتخاب (نمونه برداری معمولی با نمونه برداری مکانیکی و غیره) استفاده کنید. انتخاب چند مرحله ای را می توان با انتخاب چند مرحله ای ترکیب کرد. در هر مرحله، نمونه برداری می تواند چند مرحله ای باشد.
خطای استاندارد در نمونه برداری چند فازی برای هر فاز به طور جداگانه مطابق با فرمول های روش انتخاب و نوع نمونه برداری که جامعه نمونه آن تشکیل شده است محاسبه می شود.
حفاری های متقابل- دو یا چند نمونه مستقل از یک جمعیت که به روش و نوع یکسان جمع آوری شده اند. در صورت نیاز به دستیابی به نتایج اولیه بررسی های نمونه در مدت زمان کوتاه، توصیه می شود به نمونه های متقابل متوسل شوید. نمونه گیری متقابل برای ارزیابی نتایج نظرسنجی موثر است. اگر نتایج در نمونه های مستقل یکسان باشد، این نشان دهنده پایایی داده های بررسی نمونه است. گاهی اوقات می توان از نمونه گیری متقابل برای آزمایش کار محققان مختلف با بررسی نمونه های مختلف از هر یک استفاده کرد.
خطای استاندارد برای نمونه های متقابل با همان فرمول نمونه متناسب معمولی (5.3) تعیین می شود. نمونه های متقابل، در مقایسه با انواع دیگر، نیازمند کار و هزینه بیشتری هستند، بنابراین محقق باید در هنگام طراحی نمونه پیمایش، این موضوع را در نظر بگیرد.
محدود کردن خطاها در به طرق مختلفانتخاب و انواع نمونه گیری با فرمول تعیین می شود؟ = t؟، کجا؟ خطای استاندارد مربوطه است.
تخمین فاصله ای احتمال رویداد. فرمول های محاسبه حجم نمونه با استفاده از روش نمونه گیری کاملا تصادفی.برای تعیین احتمالات رویدادهای مورد علاقه ما، از یک روش نمونه گیری استفاده می کنیم: ما انجام می دهیم nآزمایشهای مستقل، که در هر یک از آنها رویداد A ممکن است رخ دهد (یا رخ ندهد) (احتمال آروقوع رویداد A در هر آزمایش ثابت است). سپس فراوانی نسبی p* وقوع رویدادها آدر یک سری از nآزمون ها به عنوان یک تخمین نقطه ای برای احتمال در نظر گرفته می شود پوقوع یک رویداد آدر یک محاکمه جداگانه در این حالت مقدار p* فراخوانی می شود سهم نمونه وقوع رویداد آ، و p - سهام عمومی .
با توجه به نتیجه قضیه حد مرکزی (قضیه مویور-لاپلاس)، فراوانی نسبی یک رویداد با حجم نمونه بزرگ را می توان به طور معمول با پارامترهای M(p*)=p و توزیع شده در نظر گرفت.
بنابراین، برای n> 30، یک فاصله اطمینان برای سهم عمومی را می توان با استفاده از فرمول های زیر ساخت:

جایی که u cr از جداول تابع لاپلاس، با در نظر گرفتن احتمال اطمینان داده شده γ پیدا می شود: 2Ф(u cr)=γ.
با حجم نمونه کوچک n≤30، حداکثر خطای ε از جدول توزیع Student تعیین می شود: ![]() که در آن tcr =t(k؛ α) و تعداد درجات آزادی k=n-1 احتمال α=1-γ (منطقه دو طرفه).
که در آن tcr =t(k؛ α) و تعداد درجات آزادی k=n-1 احتمال α=1-γ (منطقه دو طرفه).
فرمول ها در صورتی معتبر هستند که انتخاب به صورت تصادفی و مکرر انجام شده باشد (جمعیت عمومی بی نهایت است)، در غیر این صورت لازم است برای عدم تکرار انتخاب (جدول) تعدیل انجام شود.
میانگین خطای نمونه گیری برای سهم عمومی
| جمعیت | بي نهايت | حجم نهایی ن |
| نوع انتخاب | تکرار شد | بی تکرار |
| میانگین خطای نمونه گیری |
فرمول های محاسبه حجم نمونه با استفاده از روش نمونه گیری کاملا تصادفی
| روش انتخاب | فرمول های تعیین حجم نمونه | ||
| برای متوسط | برای اشتراک گذاری | ||
| تکرار شد | |||
| بی تکرار | |||
مشکلات عمومی اشتراک گذاری
در پاسخ به این سوال که "آیا فاصله اطمینان مقدار p0 داده شده را پوشش می دهد؟" - می توان با بررسی فرضیه آماری H 0:p=p 0 پاسخ داد. فرض بر این است که آزمایش ها بر اساس طرح آزمون برنولی (مستقل، احتمال پوقوع یک رویداد آثابت است). نمونه حجمی nتعیین فراوانی نسبی p * وقوع رویداد A: که در آن متر- تعداد وقوع رویداد آدر یک سری از nتست ها برای آزمون فرضیه H 0، از آماری استفاده می شود که با حجم نمونه به اندازه کافی بزرگ، دارای توزیع نرمال استاندارد هستند (جدول 1).جدول 1 - فرضیه های مربوط به سهم کلی
فرضیه | H 0:p=p 0 | H 0:p 1 = p 2 |
| مفروضات | مدار تست برنولی | مدار تست برنولی |
| برآورد نمونه | 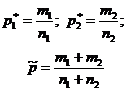 |
|
| آمار ک |  |  |
| توزیع آمار ک | نرمال استاندارد N(0,1) |
مثال شماره 1. با استفاده از نمونه گیری تصادفی تکراری، مدیریت شرکت یک نظرسنجی نمونه از 900 کارمند خود انجام داد. در میان پاسخ دهندگان 270 زن بودند. یک فاصله اطمینان با احتمال 0.95 ایجاد کنید که نسبت واقعی زنان در کل تیم شرکت را پوشش دهد.
راه حل. با توجه به شرایط، نسبت نمونه زنان (فراوانی نسبی زنان در بین همه پاسخ دهندگان) است. از آنجایی که انتخاب تکرار می شود و حجم نمونه بزرگ است (900=n)، حداکثر خطای نمونه گیری با فرمول تعیین می شود. ![]()
مقدار u cr از جدول تابع لاپلاس از رابطه 2Ф(u cr) = γ، یعنی. ![]() تابع لاپلاس (پیوست 1) مقدار 0.475 را در u cr = 1.96 می گیرد. بنابراین، خطای حاشیه ای
تابع لاپلاس (پیوست 1) مقدار 0.475 را در u cr = 1.96 می گیرد. بنابراین، خطای حاشیه ای ![]() و فاصله اطمینان مورد نظر
و فاصله اطمینان مورد نظر
(p - ε، p + ε) = (0.3 - 0.18؛ 0.3 + 0.18) = (0.12؛ 0.48)
بنابراین، با احتمال 0.95، می توانیم تضمین کنیم که نسبت زنان در کل تیم شرکت در محدوده 0.12 تا 0.48 باشد.
مثال شماره 2. اگر پارکینگ بیش از 80% پر باشد، صاحب پارکینگ روز را "خوش شانس" می داند. در طول سال 40 مورد بازرسی از پارکینگ انجام شد که از این تعداد 24 مورد "موفقیت آمیز" بود. با احتمال 0.98، یک فاصله اطمینان برای تخمین نسبت واقعی روزهای "خوش شانس" در طول سال پیدا کنید.
راه حل. نسبت نمونه روزهای "خوش شانس" است
با استفاده از جدول تابع لاپلاس، مقدار u cr را برای یک داده مشخص مییابیم
احتمال اطمینان
Ф(2.23) = 0.49، ucr = 2.33.
با در نظر گرفتن غیر تکراری بودن انتخاب (یعنی دو بررسی در یک روز انجام نشد)، خطای محدود کننده را خواهیم یافت: ![]()
که در آن n = 40، N = 365 (روز). از اینجا ![]()
و فاصله اطمینان برای سهم عمومی: (p – ε, p + ε) = (0.6 - 0.17؛ 0.6 + 0.17) = (0.43؛ 0.77)
با احتمال 0.98، می توان انتظار داشت که نسبت روزهای "خوش شانس" در طول سال در محدوده 0.43 تا 0.77 باشد.
مثال شماره 3. پس از بررسی 2500 محصول در دسته، آنها دریافتند که 400 محصول از بالاترین درجه برخوردار بودند، اما n-m نبود. چند محصول باید بررسی شود تا با اطمینان 95 درصد نسبت بالاترین درجه با دقت 0.01 تعیین شود؟
ما به دنبال راه حلی با استفاده از فرمول تعیین حجم نمونه برای انتخاب مجدد هستیم.
Ф(t) = γ/2 = 0.95/2 = 0.475 و این مقدار مطابق جدول لاپلاس با t=1.96 مطابقت دارد.
نسبت نمونه w = 0.16; خطای نمونه ε = 0.01
مثال شماره 4. دسته ای از محصولات در صورتی پذیرفته می شوند که احتمال مطابقت محصول با استاندارد حداقل 0.97 باشد. از بین 200 محصول دسته آزمایش شده به طور تصادفی انتخاب شده، 193 محصول دارای استاندارد بودند. آیا امکان پذیرش دسته در سطح معنی داری 02/0= α وجود دارد؟
راه حل. اجازه دهید فرضیه های اصلی و جایگزین را فرموله کنیم.
H 0:p=p 0 =0.97 - سهم عمومی ناشناخته پبرابر با مقدار مشخص شده p 0 = 0.97. در رابطه با شرایط - احتمال اینکه بخشی از دسته بازرسی شده با استاندارد مطابقت داشته باشد برابر با 0.97 است. آن ها دسته ای از محصولات قابل قبول است.
H 1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
ارزش آماری مشاهده شده ک(جدول) محاسبه برای مقادیر داده شده p 0 = 0.97، n = 200، m = 193

مقدار بحرانی را از جدول تابع لاپلاس از برابری پیدا می کنیم
![]()
با توجه به شرایط، α = 0.02، از این رو F(Kcr) = 0.48 و Kcr = 2.05. منطقه بحرانی سمت چپ است، یعنی. بازه (-∞;-K kp)= (-∞;-2.05) است. مقدار مشاهده شده K obs = -0.415 به منطقه بحرانی تعلق ندارد، بنابراین، در این سطح از اهمیت، دلیلی برای رد فرضیه اصلی وجود ندارد. شما می توانید یک دسته از محصولات را بپذیرید.
مثال شماره 5. دو کارخانه یک نوع قطعات را تولید می کنند. برای ارزیابی کیفیت آنها از محصولات این کارخانه ها نمونه برداری شد و نتایج زیر بدست آمد. از بین 200 محصول انتخابی کارخانه اول، 20 محصول معیوب و از بین 300 محصول کارخانه دوم، 15 محصول معیوب بودند.
در سطح معنی داری 025/0 متوجه شوید که آیا تفاوت معنی داری در کیفیت قطعات تولید شده توسط این کارخانه ها وجود دارد یا خیر.
با توجه به شرط، α = 0.025، از این رو F(Kcr) = 0.4875 و Kcr = 2.24. با یک جایگزین دو طرفه، محدوده مقادیر قابل قبول به شکل (-2.24;2.24) است. مقدار مشاهده شده K obs = 2.15 در این بازه قرار می گیرد، یعنی. در این سطح از اهمیت، دلیلی برای رد فرضیه اصلی وجود ندارد. کارخانه ها محصولاتی با همان کیفیت تولید می کنند.
طرح:
1. مسائل آمار ریاضی.
2. انواع نمونه.
3. روش های انتخاب
4. توزیع آماری نمونه.
5. تابع توزیع تجربی
6. چند ضلعی و هیستوگرام.
7. ویژگی های عددی سری تغییرات.
8. برآوردهای آماری پارامترهای توزیع.
9. تخمین فاصله ای پارامترهای توزیع.
1. مسائل و روش های آمار ریاضی
آمار ریاضی شاخهای از ریاضیات است که به روشهای جمعآوری، تجزیه و تحلیل و پردازش نتایج دادههای مشاهدهای آماری برای اهداف علمی و عملی اختصاص دارد.
اجازه دهید مطالعه مجموعه ای از اشیاء همگن با توجه به برخی ویژگی های کمی یا کیفی که این اشیاء را مشخص می کند ضروری باشد. به عنوان مثال، اگر دسته ای از قطعات وجود داشته باشد، استاندارد قطعه می تواند به عنوان یک علامت کیفی و اندازه کنترل شده قطعه می تواند به عنوان یک علامت کمی عمل کند.
گاهی اوقات یک مطالعه کامل انجام می شود، یعنی. هر شی برای مشخصه مورد نیاز بررسی می شود. در عمل، نظرسنجی کامل به ندرت مورد استفاده قرار می گیرد. به عنوان مثال، اگر یک جمعیت دارای تعداد بسیار زیادی از اشیاء باشد، انجام یک نظرسنجی جامع از نظر فیزیکی غیرممکن است. اگر بررسی یک شی با تخریب آن همراه باشد یا به هزینه های مادی زیادی نیاز داشته باشد، انجام یک بررسی کامل منطقی نیست. در چنین مواردی، تعداد محدودی از اشیا به طور تصادفی از کل جامعه (جمعیت نمونه) انتخاب شده و مورد مطالعه قرار می گیرند.
وظیفه اصلی آمار ریاضی مطالعه کل جمعیت با استفاده از داده های نمونه است، بسته به هدف، یعنی. مطالعه خواص احتمالی یک جمعیت: قانون توزیع، ویژگی های عددی و غیره. برای اتخاذ تصمیمات مدیریتی در شرایط عدم اطمینان.
2. انواع نمونه
جمعیت مجموعه اجسامی است که نمونه از آنها ساخته شده است.
جامعه نمونه (نمونه) مجموعه ای از اشیا به صورت تصادفی انتخاب شده است.
حجم جمعیت تعداد اشیاء این مجموعه است. اندازه جمعیت با نشان داده می شود N، انتخابی - n.
مثال:
اگر از 1000 قسمت، 100 قسمت برای بررسی انتخاب شود، حجم جمعیت عمومی استن = 1000 و حجم نمونه n = 100.
دو راه برای انتخاب یک نمونه وجود دارد: پس از انتخاب و مشاهده یک شی، ممکن است به جمعیت بازگردانده شود یا نباشد. که نمونه ها به دو دسته تکراری و غیر تکراری تقسیم می شوند.
تکرارتماس گرفت نمونه، که در آن شی انتخاب شده (قبل از انتخاب مورد بعدی) به جمعیت بازگردانده می شود.
بی تکرارتماس گرفت نمونه، که در آن شی انتخاب شده به جمعیت بازگردانده نمی شود.
در عمل معمولاً از نمونه گیری تصادفی تکراری استفاده می شود.
برای اینکه بتوان با اطمینان کافی در مورد ویژگی جامعه مورد نظر بر اساس داده های نمونه قضاوت کرد، لازم است که اشیاء نمونه به درستی آن را نشان دهند. نمونه باید به درستی نسبت های جامعه را نشان دهد. نمونه باید باشد نماینده (نماینده).
با توجه به قانون اعداد بزرگ، می توان استدلال کرد که نمونه در صورتی که به صورت تصادفی انجام شود نماینده خواهد بود.
اگر اندازه جامعه به اندازه کافی بزرگ باشد و نمونه فقط بخش کوچکی از این جامعه را تشکیل دهد، در این صورت تمایز بین نمونه های تکراری و غیر تکراری پاک می شود. در حالت محدود، هنگامی که یک جمعیت نامحدود در نظر گرفته می شود و نمونه دارای اندازه محدود است، این تفاوت از بین می رود.
مثال:
مجله آمریکایی Literary Review با استفاده از روش های آماری، پیش بینی های مربوط به نتیجه انتخابات ریاست جمهوری آینده ایالات متحده در سال 1936 را مطالعه کرد. مدعیان این پست F.D. روزولت و A. M. Landon. دایرکتوری های تلفن به عنوان منبعی برای جمعیت عمومی آمریکایی های مورد مطالعه در نظر گرفته شد. از این تعداد 4 میلیون آدرس به صورت تصادفی انتخاب شد که سردبیران مجله با ارسال کارت پستال از آنها خواستند نگرش خود را نسبت به نامزدهای ریاست جمهوری بیان کنند. پس از پردازش نتایج نظرسنجی، مجله پیشبینی جامعهشناختی منتشر کرد مبنی بر اینکه لندون با اختلاف زیادی در انتخابات آینده پیروز خواهد شد. و... اشتباه کردم: روزولت پیروز شد.
این مثال را می توان نمونه ای از نمونه های غیرنماینده در نظر گرفت. واقعیت این است که در ایالات متحده در نیمه اول قرن بیستم، تنها بخش ثروتمندی از جمعیت که از نظرات لاندون حمایت می کردند، تلفن داشتند.
3. روش های انتخاب
در عمل از روش های مختلف انتخاب استفاده می شود که می توان آنها را به 2 نوع تقسیم کرد:
1. انتخاب نیازی به تقسیم جمعیت به بخش های (الف) ندارد. تصادفی ساده و بدون تکرار; ب) تکرار تصادفی ساده).
2. انتخاب، که در آن جمعیت به قسمت هایی تقسیم می شود. (آ) انتخاب معمولی; ب) انتخاب مکانیکی; V) سریال انتخاب).
تصادفی ساده آنها به این می گویند انتخاب، که در آن اشیا یکی یکی از کل جمعیت (به طور تصادفی) استخراج می شوند.
معمولتماس گرفت انتخاب، که در آن اشیاء نه از کل جمعیت، بلکه از هر بخش "معمولی" آن انتخاب می شوند. به عنوان مثال، اگر یک قطعه بر روی چندین ماشین تولید شود، انتخاب نه از کل مجموعه قطعات تولید شده توسط همه ماشین ها، بلکه از محصولات هر دستگاه به طور جداگانه انجام می شود. این انتخاب زمانی استفاده میشود که ویژگی مورد بررسی در بخشهای مختلف «معمولی» جمعیت عمومی بهطور محسوسی متفاوت باشد.
مکانیکیتماس گرفت انتخابکه در آن، جمعیت عمومی بهعنوان «مکانیکی» به تعداد اشیایی که باید در نمونه گنجانده شوند، به گروههایی تقسیم میشوند و از هر گروه یک شی انتخاب میشود. به عنوان مثال، اگر شما نیاز به انتخاب 20٪ از قطعات تولید شده توسط یک ماشین دارید، هر 5 قسمت انتخاب می شود. در صورت نیاز به انتخاب 5٪ از قطعات - هر 20 و غیره. گاهی اوقات چنین انتخابی ممکن است نماینده نمونه را تضمین نکند (اگر هر بیستمین غلتک آسیاب شده انتخاب شود و کاتر بلافاصله پس از انتخاب جایگزین شود، آنگاه تمام غلتک هایی که با برش های بلانت چرخانده شده اند انتخاب می شوند).
سریالتماس گرفت انتخاب، که در آن اشیاء از جمعیت عمومی نه یک بار، بلکه به صورت "سری" انتخاب می شوند که تحت یک بررسی مداوم قرار می گیرند. به عنوان مثال، اگر محصولات توسط گروه بزرگی از ماشینهای اتوماتیک تولید میشوند، محصولات تنها چند ماشین مورد بررسی جامع قرار میگیرند.
در عمل اغلب از انتخاب ترکیبی استفاده می شود که در آن روش های فوق با هم ترکیب می شوند.
4. توزیع آماری نمونه
بگذارید یک نمونه از جامعه عمومی استخراج شود و مقدار x 1 باشد–یک بار مشاهده شده، x 2 -n 2 بار،... x k - n k بار. n= n 1 +n 2 +...+n k – حجم نمونه. مقادیر مشاهده شدهنامیده می شوند گزینه ها، و ترتیب گزینه ها به ترتیب صعودی نوشته شده است سری تغییرات. تعداد مشاهداتنامیده می شوند فرکانس ها (فرکانس های مطلق)و ارتباط آنها با حجم نمونه- فرکانس های نسبییا احتمالات آماری
اگر تعداد متغیرها زیاد باشد یا نمونه از یک جمعیت پیوسته گرفته شود، سری تغییرات نه از مقادیر نقطهای منفرد، بلکه از فواصل مقادیر در جامعه جمعآوری میشود. چنین سری تغییراتی نامیده می شود فاصلهطول فواصل باید برابر باشد.
توزیع نمونه آماری فهرستی از گزینه ها و فرکانس های مربوطه یا فرکانس های نسبی آنها نامیده می شود.
توزیع آماری همچنین می تواند به عنوان دنباله ای از بازه ها و فرکانس های مربوط به آنها مشخص شود (مجموع فرکانس هایی که در این بازه مقادیر قرار می گیرند)
یک سری تغییرات نقطه ای از فرکانس ها را می توان با یک جدول نشان داد:
| x i |
x 1 |
x 2 |
… |
x k |
| n من |
n 1 |
n 2 |
… |
n k |
به طور مشابه، می توان یک سری تغییرات نقطه ای از فرکانس های نسبی را تصور کرد.
علاوه بر این:
مثال:
تعداد حروف در یک متن خاص X برابر با 1000 بود. اولین حرفی که با آن مواجه شدیم حرف "i"، دومی حرف "i"، سومی حرف "a"، چهارمی "الف" بود. یو». سپس حروف "o"، "e"، "u"، "e"، "s" آمدند.
بیایید مکان هایی را که آنها در الفبا اشغال می کنند را بنویسیم که به ترتیب داریم: 33، 10، 1، 32، 16، 6، 21، 31، 29.
پس از مرتب کردن این اعداد به ترتیب صعودی، سری تغییرات را بدست می آوریم: 1، 6، 10، 16، 21، 29، 31، 32، 33.
فراوانی ظاهر حروف در متن: "a" - 75، "e" - 87، "i" - 75، "o" - 110، "u" - 25، "s" - 8، "e" - 3 ، "یو" "- 7، "من" - 22.
بیایید یک سری تغییرات نقطه ای از فرکانس ها ایجاد کنیم:
مثال:
توزیع فرکانس نمونه برداری حجم مشخص n = 20.
یک سری تغییرات نقطه ای از فرکانس های نسبی بسازید.
| x i |
2 |
6 |
12 |
| n من |
3 |
10 |
7 |
راه حل:
بیایید فرکانس های نسبی را پیدا کنیم:
| x i |
2 |
6 |
12 |
| w i |
0,15 |
0,5 |
0,35 |
هنگام ساخت یک توزیع بازه ای، قوانینی برای انتخاب تعداد بازه ها یا اندازه هر بازه وجود دارد. معیار در اینجا نسبت بهینه است: با افزایش تعداد فواصل، نمایندگی بهبود می یابد، اما حجم داده ها و زمان پردازش آن افزایش می یابد. تفاوت x max - x min بین بزرگترین و کوچکترین مقادیر گزینه فراخوانی می شود محدودهنمونه ها.
برای شمارش تعداد فواصلک معمولاً از فرمول تجربی Sturges استفاده می شود (به معنای گرد کردن به نزدیکترین عدد صحیح صحیح): k = 1 + 3.322 log n.
بر این اساس، اندازه هر بازهساعت با استفاده از فرمول قابل محاسبه است:
5. تابع توزیع تجربی
بیایید چند نمونه از جمعیت عمومی را در نظر بگیریم. اجازه دهید توزیع فراوانی آماری مشخصه کمی X مشخص باشد.- تعداد مشاهداتی که در آنها یک مقدار مشخصه کمتر از x مشاهده شده است. n - تعداد کل مشاهدات (اندازه نمونه). فراوانی نسبی رویداد X<х равна nx/n. اگر x تغییر کند، فرکانس نسبی نیز تغییر می کند، یعنی. فراوانی نسبیn x /n- تابع x وجود دارد. زیرا به صورت تجربی یافت می شود، سپس تجربی نامیده می شود.
تابع توزیع تجربی (تابع توزیع نمونه) تابع را فراخوانی کنید، که برای هر x فرکانس نسبی رویداد X را تعیین می کند<х.
کجا تعداد گزینه ها کمتر از x است،
n - حجم نمونه
برخلاف تابع توزیع تجربی یک نمونه، تابع توزیع F(x) جامعه نامیده می شود تابع توزیع نظری.
تفاوت بین توابع توزیع تجربی و نظری در این است که تابع نظری F (x) احتمال رخداد X را تعیین می کند.
که توصیه می شود از تابع توزیع تجربی نمونه برای تقریب تابع توزیع نظری (انتگرال) جمعیت عمومی استفاده شود.
F*(x)تمام خواص را دارد F(x).
1. ارزش ها F*(x)متعلق به بازه
2. F*(x) یک تابع غیر کاهشی است.
3. اگر کوچکترین گزینه است، F*(x) = 0، برای x < x 1 ; اگر x k بزرگترین گزینه است، F*(x) = 1، برای x > x k.
آن ها F*(x)برای تخمین F(x) خدمت می کند.
اگر نمونه با یک سری تغییرات داده شود، تابع تجربی به شکل زیر است:
نمودار یک تابع تجربی را انباشته می نامند.
مثال:
یک تابع تجربی از توزیع نمونه داده شده را رسم کنید.
راه حل:
اندازه نمونه n = 12 + 18 + 30 = 60. کوچکترین گزینه 2 است، i.e. در x <
2. رویداد X<6,
(x 1
= 2) наблюдалось 12 раз, т.е. F*(x)=12/60=0.2در 2 <
ایکس <
6. رویداد X<10, (x 1 =2, x 2 = 6) наблюдалось 12 + 18 = 30 раз, т.е.F*(x)=30/60=0,5
при 6 <
ایکس <
10. زیرا پس x=10 بزرگترین گزینه است F*(x) = 1در x>10. تابع تجربی مورد نظر به شکل زیر است:
تجمع می کند:
انباشته کردن امکان درک اطلاعات ارائه شده به صورت گرافیکی را فراهم می کند، به عنوان مثال، به سؤالات پاسخ دهید: «تعداد مشاهداتی را که در آن مقدار مشخصه کمتر از 6 یا کمتر از 6 بود، تعیین کنید. F*(6) =0.2 سپس تعداد مشاهداتی که در آنها مقدار مشخصه مشاهده شده کمتر از 6 بوده است 0.2* است. n = 0.2 * 60 = 12. تعداد مشاهداتی که در آنها مقدار مشخصه مشاهده شده حداقل 6 بوده است برابر با (1-0.2)* n = 0.8 * 60 = 48.
اگر یک سری تغییرات بازه ای داده شود، برای کامپایل یک تابع توزیع تجربی، نقاط میانی بازه ها پیدا می شود و از آنها تابع توزیع تجربی مشابه یک سری تغییرات نقطه ای به دست می آید.
6. چند ضلعی و هیستوگرام
برای وضوح، نمودارهای توزیع آماری مختلفی ساخته شده است: چند جمله ای و هیستوگرام
محدوده فرکانس -این یک خط شکسته است که بخشهای آن نقاط ( x 1 ; n 1 )، ( x 2 ; n 2 ),…, ( x k , n k ) را به هم متصل میکند، جایی که گزینهها و فرکانسهای مربوطه هستند.
چند ضلعی فرکانس نسبی -این یک خط شکسته است که بخش های آن نقاط ( x 1 ; w 1 ), ( x 2 , w 2 ),…, ( x k , w k ) را به هم متصل می کند که در آن x i گزینه ها هستند، w i فرکانس های نسبی مربوط به آنها
مثال:
یک چند جمله ای از فرکانس های نسبی از توزیع نمونه داده شده بسازید:
راه حل:
در مورد یک مشخصه پیوسته، توصیه می شود یک هیستوگرام ساخته شود، که برای آن بازه ای که تمام مقادیر مشاهده شده مشخصه در آن وجود دارد به چندین بازه جزئی به طول h تقسیم می شود و برای هر بازه جزئی n i یافت می شود - مجموع فرکانس های متغیرهایی که در بازه i قرار می گیرند. (به عنوان مثال، هنگام اندازه گیری قد یا وزن یک فرد، با یک ویژگی پیوسته سروکار داریم).
هیستوگرام فرکانس -این یک شکل پلکانی متشکل از مستطیل هایی است که پایه های آن فواصل جزئی به طول h و ارتفاعات برابر با نسبت (چگالی فرکانس) است.
مربع مستطیل جزئی iم برابر است با مجموع فرکانس های نوع بازه i، یعنی. مساحت هیستوگرام فرکانس برابر است با مجموع همه فرکانس ها، یعنی. اندازهی نمونه.
مثال:
نتایج تغییرات ولتاژ (بر حسب ولت) در شبکه الکتریکی آورده شده است. یک سری تغییرات بسازید، یک چند ضلعی و یک هیستوگرام فرکانس بسازید اگر مقادیر ولتاژ به شرح زیر باشد: 227، 215، 230، 232، 223، 220، 228، 222، 221، 226، 226، 215، 218، 216، 220، 225، 212، 217، 220.
راه حل:
بیایید یک سری تغییرات ایجاد کنیم. ما n = 20، x min = 212، x max = 232 داریم.
بیایید از فرمول استرجس برای محاسبه تعداد بازه ها استفاده کنیم.
سری تغییرات بازه ای فرکانس ها به شکل زیر است:
|
|
چگالی فرکانس |
|
212-21 6 |
0,75 |
|
|
21 6-22 0 |
0,75 |
|
|
220-224 |
1,75 |
|
|
224-228 |
||
|
228-232 |
0,75 |
بیایید یک هیستوگرام فرکانس بسازیم:
بیایید با پیدا کردن نقاط میانی فواصل، یک چندضلعی فرکانس بسازیم:
هیستوگرام فرکانس نسبیبه شکل پلکانی متشکل از مستطیل هایی گفته می شود که پایه های آن فواصل جزئی به طول h و ارتفاع آن برابر با نسبت w است. من/h (چگالی فرکانس نسبی).
مربع مستطیل جزئی i ام برابر است با بسامد نسبی متغیرهایی که در بازه i قرار می گیرند. آن ها مساحت هیستوگرام فرکانس های نسبی برابر است با مجموع همه فرکانس های نسبی، یعنی. واحد.
7. ویژگی های عددی سری تغییرات
بیایید ویژگی های اصلی جمعیت عمومی و نمونه را در نظر بگیریم.
متوسطه عمومیمیانگین حسابی مقادیر مشخصه جمعیت عمومی نامیده می شود.
برای مقادیر مختلف x 1، x 2، x 3، ...، x n. مشخصه جمعیت عمومی حجم N داریم:
اگر مقادیر مشخصه دارای فرکانس های متناظر N 1 +N 2 +…+N k =N باشند، پس
میانگین نمونهمیانگین حسابی مقادیر مشخصه جامعه نمونه نامیده می شود.
اگر مقادیر مشخصه دارای فرکانس های متناظر n 1 +n 2 +…+n k = n باشند،
مثال:
میانگین نمونه را برای نمونه محاسبه کنید: x 1 = 51.12; x 2 = 51.07؛ x 3 = 52.95; x 4 = 52.93؛ x 5 = 51.1؛ x 6 = 52.98؛ x 5 = 51.1. x 7 = 52.29; x 8 = 51.23; x 9 = 51.07; x 10 = 51.04.
راه حل:
واریانس عمومیمیانگین حسابی مجذور انحراف مقادیر مشخصه X جمعیت عمومی از میانگین کلی نامیده می شود.
برای مقادیر مختلف x 1 , x 2 , x 3 , ..., x N از مشخصه جمعیت عمومی حجم N داریم:
اگر مقادیر مشخصه دارای فرکانس های متناظر N 1 +N 2 +…+N k =N باشند، پس
انحراف استاندارد عمومی (استاندارد)جذر واریانس عمومی نامیده می شود
واریانس نمونهمیانگین حسابی مجذور انحراف مقادیر مشاهده شده یک مشخصه از مقدار میانگین نامیده می شود.
برای مقادیر مختلف x 1 , x 2 , x 3 , ..., x n از ویژگی جمعیت نمونه حجم n داریم:
اگر مقادیر مشخصه دارای فرکانس های متناظر n 1 +n 2 +…+n k = n باشند،
نمونه انحراف استاندارد (استاندارد)جذر واریانس نمونه نامیده می شود.
مثال:
جامعه نمونه توسط جدول توزیع مشخص می شود. واریانس نمونه را پیدا کنید.
راه حل:
قضیه: واریانس برابر است با تفاوت بین میانگین مربعات مقادیر مشخصه و مربع میانگین کلی.
مثال:
واریانس این توزیع را پیدا کنید.
راه حل:
8. برآوردهای آماری پارامترهای توزیع
اجازه دهید جامعه عمومی با استفاده از یک نمونه خاص مورد مطالعه قرار گیرد. در این مورد، می توان تنها یک مقدار تقریبی از پارامتر مجهول Q را به دست آورد که به عنوان تخمین آن عمل می کند. بدیهی است که برآوردها ممکن است از یک نمونه به نمونه دیگر متفاوت باشد.
ارزیابی آماریس*پارامتر مجهول توزیع نظری بسته به مقادیر نمونه مشاهده شده تابع f نامیده می شود. وظیفه تخمین آماری پارامترهای ناشناخته از یک نمونه، ساخت تابعی از داده های مشاهدات آماری موجود است که دقیق ترین مقادیر تقریبی واقعی، ناشناخته برای محقق، این پارامترها را ارائه دهد.
برآوردهای آماری بسته به روش ارائه آنها (تعداد یا فاصله) به نقطه و فاصله تقسیم می شوند.
یک نقطه یک برآورد آماری استپارامتر Q توزیع نظری با یک مقدار از پارامتر Q *=f (x 1, x 2, ..., x n) تعیین می شود.x 1، x 2، ...، x n- نتایج مشاهدات تجربی روی مشخصه کمی X یک نمونه خاص.
چنین برآوردهای پارامتری به دست آمده از نمونه های مختلف اغلب با یکدیگر متفاوت هستند. تفاوت مطلق /Q *-Q / نامیده می شود خطای نمونه برداری (تخمین).
برای اینکه تخمین های آماری نتایج قابل اعتمادی را در مورد پارامترهای تخمین زده تولید کنند، باید بی طرفانه، کارآمد و سازگار باشند.
تخمین نقطه ای، که انتظار ریاضی آن برابر (نه برابر) با پارامتر تخمین زده شده است نامیده می شود جابجا نشده (آواره). M(Q *)=Q.
تفاوت M( Q *)-Q نامیده می شود سوگیری یا خطای سیستماتیک. برای تخمین های بی طرفانه، تعصب 0 است.
تاثير گذار ارزیابی Q *، که برای اندازه نمونه معین n دارای کوچکترین واریانس ممکن است: D min(n=const). برآوردگر مؤثر کمترین واریانس را در مقایسه با سایر برآوردگرهای بی طرف و ثابت دارد.
ثروتمنداین را آماری بنامیم ارزیابی Q *، که برای nبه احتمال زیاد به پارامتر برآورد شده تمایل داردس ، یعنی با افزایش حجم نمونه n تخمین به احتمال زیاد به مقدار واقعی پارامتر تمایل داردس
الزام سازگاری با قانون اعداد بزرگ سازگار است: هرچه اطلاعات اولیه در مورد شی مورد مطالعه بیشتر باشد، نتیجه دقیق تر است. اگر حجم نمونه کوچک باشد، تخمین نقطه ای پارامتر می تواند منجر به خطاهای جدی شود.
عاشقشم نمونه (حجمن)را می توان به عنوان یک مجموعه سفارش داده شده در نظر گرفتx 1، x 2، ...، x nمتغیرهای تصادفی مستقل با توزیع یکسان.
معنی نمونه برای اندازه های مختلف نمونه n از یک جمعیت متفاوت خواهد بود. یعنی میانگین نمونه را می توان به عنوان یک متغیر تصادفی در نظر گرفت، یعنی می توان در مورد توزیع میانگین نمونه و ویژگی های عددی آن صحبت کرد.
میانگین نمونه تمام الزامات تحمیل شده بر برآوردهای آماری را برآورده می کند، یعنی. یک تخمین بی طرفانه، کارآمد و ثابت از میانگین کلی ارائه می دهد.
می توان ثابت کرد که. بنابراین، واریانس نمونه یک برآورد مغرضانه از واریانس جامعه است که آن را دست کم می گیرد. یعنی با حجم نمونه کوچک یک خطای سیستماتیک ایجاد می کند. برای یک تخمین بی طرفانه و ثابت، کافی است مقدار را در نظر بگیریدکه به آن واریانس تصحیح شده می گویند. به این معنا که
در عمل، برای تخمین واریانس کلی، از واریانس تصحیح شده استفاده می شود n < 30. در موارد دیگر ( n>30) انحراف از به سختی قابل توجه است بنابراین، برای مقادیر بزرگ n خطای افست را می توان نادیده گرفت.
همچنین می توان ثابت کرد که فرکانس نسبیn i / n یک برآورد احتمال بی طرفانه و ثابت است P (X =x i ). تابع توزیع تجربی F*(x ) یک تخمین بی طرفانه و ثابت از تابع توزیع نظری است F(x)=P(X< x ).
مثال:
برآوردهای بی طرفانه از مقدار مورد انتظار و واریانس را از جدول نمونه بیابید.
| x i |
|||
| n من |
راه حل:
حجم نمونه n=20.
یک برآورد بی طرفانه از انتظارات ریاضی میانگین نمونه است.
برای محاسبه برآورد واریانس بی طرفانه، ابتدا واریانس نمونه را پیدا می کنیم:
حالا بیایید تخمین بی طرفانه را پیدا کنیم:
9. تخمین فاصله ای پارامترهای توزیع
فاصله یک برآورد آماری است که توسط دو مقدار عددی تعیین می شود - انتهای بازه مورد مطالعه.
عدد> 0، که برای آن | س - س *|< ، دقت برآورد فاصله را مشخص می کند.
مورد اعتمادتماس گرفت فاصله ، که با یک احتمال معینمقدار پارامتر ناشناخته را پوشش می دهدس . تکمیل یک فاصله اطمینان به مجموعه تمام مقادیر ممکن یک پارامترس تماس گرفت منطقه بحرانی. اگر ناحیه بحرانی فقط در یک طرف فاصله اطمینان قرار گیرد، فاصله اطمینان نامیده می شود یک طرفه: سمت چپ، اگر منطقه بحرانی فقط در سمت چپ وجود داشته باشد، و راست دستاگر فقط در سمت راست در غیر این صورت فاصله اطمینان نامیده می شود دو طرفه.
قابلیت اطمینان یا سطح اطمینان، Q را تخمین می زند (با استفاده از Q *) احتمالی است که با آن نابرابری زیر برآورده می شود: |س - س *|< .
بیشتر اوقات، احتمال اطمینان از قبل تنظیم می شود (0.95؛ 0.99؛ 0.999) و این شرط بر آن تحمیل می شود که نزدیک به یک باشد.
احتمالتماس گرفت احتمال خطا یا سطح اهمیت
اجازه دهید | س - س *|< ، سپس. این بدان معنی است که با احتمالمی توان استدلال کرد که مقدار واقعی پارامترس متعلق به فاصله است. هر چه انحراف کمتر باشد، تخمین دقیق تر است.
مرزهای (انتهای) فاصله اطمینان نامیده می شوند محدودیت های اطمینان یا محدودیت های بحرانی.
مقادیر حدود فاصله اطمینان به قانون توزیع پارامتر بستگی داردس*.
مقدار انحرافبرابر با نصف عرض فاصله اطمینان نامیده می شود دقت ارزیابی
روشهای ساخت فواصل اطمینان اولین بار توسط آماردان آمریکایی یو. نیومن توسعه یافت. دقت برآورد، احتمال اطمینان و حجم نمونه n به یکدیگر متصل می شوند. بنابراین، با دانستن مقادیر خاص دو کمیت، همیشه می توانید مقدار سوم را محاسبه کنید.
یافتن فاصله اطمینان برای تخمین انتظار ریاضی از توزیع نرمال در صورتی که انحراف معیار مشخص باشد.
اجازه دهید نمونه ای از یک جمعیت عمومی مشمول قانون توزیع نرمال گرفته شود. اجازه دهید انحراف معیار کلی مشخص شود، اما انتظار ریاضی از توزیع نظری ناشناخته استآ ().
فرمول زیر صحیح است:
آن ها با توجه به مقدار انحراف داده شدهمی توان یافت که با چه احتمالی میانگین کلی مجهول متعلق به بازه است. و بالعکس. از فرمول مشخص می شود که با افزایش حجم نمونه و مقدار ثابتی از احتمال اطمینان، مقدار- کاهش می یابد، یعنی دقت ارزیابی افزایش می یابد. با افزایش قابلیت اطمینان (احتمال اطمینان)، ارزش-افزایش می یابد، یعنی. دقت ارزیابی کاهش می یابد.
مثال:
در نتیجه آزمایشات، مقادیر زیر به دست آمد -25، 34، -20، 10، 21. مشخص است که آنها از قانون توزیع نرمال با انحراف استاندارد 2 پیروی می کنند. تخمین a* را برای آن بیابید. انتظارات ریاضی الف. یک فاصله اطمینان 90% برای آن بسازید.
راه حل:
بیایید یک برآورد بی طرفانه پیدا کنیم
سپس
فاصله اطمینان برای a است: 4 - 1.47< آ< 4+ 1,47 или 2,53 < a < 5, 47
یافتن فاصله اطمینان برای تخمین انتظار ریاضی از توزیع نرمال در صورتی که انحراف معیار ناشناخته باشد.
بگذارید بدانیم که جمعیت عمومی تابع قانون توزیع نرمال است که در آن a و. دقت پوشش فاصله اطمینان با قابلیت اطمینانمقدار واقعی پارامتر a، در این مورد، با فرمول محاسبه می شود:
, که در آن n حجم نمونه است، , - ضریب دانش آموز (باید از مقادیر داده شده پیدا شود n و از جدول "نقاط بحرانی توزیع دانش آموز").
مثال:
در نتیجه آزمایش ها مقادیر زیر به دست آمد -35-، -32، -26، -35، -30، -17. مشخص است که آنها از قانون توزیع نرمال پیروی می کنند. فاصله اطمینان برای انتظار ریاضی a از جامعه را با احتمال اطمینان 0.9 بیابید.
راه حل:
بیایید یک برآورد بی طرفانه پیدا کنیم.
پیدا خواهیم کرد.
سپس
فاصله اطمینان شکل خواهد گرفت(29.2 - 5.62؛ -29.2 + 5.62) یا (34.82-؛ 23.58 -).
یافتن فاصله اطمینان برای واریانس و انحراف معیار یک توزیع نرمال
اجازه دهید یک نمونه تصادفی از حجم از یک جمعیت کلی از مقادیر توزیع شده طبق قانون عادی گرفته شودn < 30، که واریانس نمونه برای آن محاسبه می شود: بایاسو s 2 را تصحیح کرد. سپس، برای یافتن تخمین های بازه ای با پایایی معینبرای واریانس کلیDانحراف استاندارد عمومیاز فرمول های زیر استفاده می شود.
یا,
ارزش های- با استفاده از جدول مقادیر نقطه بحرانی پیدا شده استتوزیع های پیرسون
فاصله اطمینان برای واریانس از این نابرابری ها با مجذور کردن تمام اضلاع نابرابری به دست می آید.
مثال:
کیفیت 15 پیچ بررسی شد. با فرض اینکه خطا در ساخت آنها تابع قانون توزیع نرمال و انحراف استاندارد نمونه باشد.برابر با 5 میلی متر، به طور قابل اعتماد تعیین کنیدفاصله اطمینان برای یک پارامتر ناشناخته
ما مرزهای بازه را به شکل یک نابرابری مضاعف نشان می دهیم:
انتهای فاصله اطمینان دو طرفه برای واریانس را می توان بدون انجام عملیات حسابی برای سطح معینی از اطمینان و حجم نمونه با استفاده از جدول مناسب تعیین کرد (حدود فاصله اطمینان برای واریانس بسته به تعداد درجات آزادی و قابلیت اطمینان) . برای انجام این کار، انتهای بازه به دست آمده از جدول در واریانس اصلاح شده s 2 ضرب می شود..
مثال:
بیایید مشکل قبلی را به روش دیگری حل کنیم.
راه حل:
بیایید واریانس اصلاح شده را پیدا کنیم:
با استفاده از جدول "حدود فاصله اطمینان برای پراکندگی بسته به تعداد درجات آزادی و قابلیت اطمینان"، ما مرزهای فاصله اطمینان برای پراکندگی را در خواهیم یافت.ک= 14 و: حد پایین 0.513 و حد بالایی 2.354.
اجازه دهید مرزهای حاصل را در ضرب کنیمs 2 و ریشه را استخراج کنید (از آنجایی که ما به یک فاصله اطمینان نه برای واریانس، بلکه برای انحراف استاندارد نیاز داریم).
همانطور که از مثال ها مشخص است، اندازه فاصله اطمینان به روش ساخت آن بستگی دارد و نتایج مشابه، اما نابرابر می دهد.
برای نمونه هایی با اندازه کافی بزرگ (n>30) مرزهای فاصله اطمینان برای انحراف استاندارد عمومی را می توان با فرمول تعیین کرد: - عدد معینی که جدول بندی شده و در جدول مرجع مربوطه آورده شده است.
اگر 1- q<1, то формула имеет вид:
مثال:
بیایید مشکل قبلی را به روش سوم حل کنیم.
راه حل:
قبلا پیدا شده استس= 5,17. q(0.95؛ 15) = 0.46 - از جدول پیدا شده است.
سپس:
پژوهش معمولاً با فرضیاتی آغاز می شود که نیاز به تأیید با استفاده از حقایق دارد. این فرض - یک فرضیه - در رابطه با ارتباط پدیده ها یا ویژگی ها در مجموعه خاصی از اشیاء فرموله می شود.
برای آزمایش چنین مفروضاتی در برابر واقعیت ها، لازم است ویژگی های مربوط به حاملان آنها اندازه گیری شود. اما اندازه گیری اضطراب در همه زنان و مردان غیرممکن است، همانطور که اندازه گیری پرخاشگری در همه نوجوانان غیرممکن است. بنابراین، هنگام انجام تحقیق، تنها به گروه نسبتاً کوچکی از نمایندگان جمعیت های مربوطه افراد محدود می شود.
جمعیت- این کل مجموعه ای از اشیاء است که یک فرضیه تحقیق در رابطه با آنها فرموله می شود.
به عنوان مثال، همه مردان; یا همه زنان؛ یا همه ساکنان یک شهر. جمعیتهای عمومی در رابطه با آنها که محقق قرار است بر اساس نتایج مطالعه نتیجهگیری کند، ممکن است از نظر تعداد کمتر باشند، مثلاً همه دانشآموزان کلاس اولی یک مدرسه معین.
بنابراین، جمعیت عمومی، اگرچه از نظر تعداد نامتناهی نیست، اما، به عنوان یک قاعده، برای تحقیقات مستمر، مجموعه ای از موضوعات بالقوه غیرقابل دسترس است.
نمونه یا جامعه نمونه- این گروهی از اشیاء محدود به تعداد (در روانشناسی - افراد، پاسخ دهندگان) است که به طور خاص از جمعیت عمومی برای مطالعه ویژگی های آن انتخاب شده است. بر این اساس، مطالعه ویژگی های جمعیت عمومی با استفاده از نمونه نامیده می شود مطالعه نمونه گیری تقریباً تمام مطالعات روانشناختی انتخابی هستند و نتیجهگیریهای آنها به جمعیتهای عمومی گسترش مییابد.
بنابراین، پس از تدوین یک فرضیه و شناسایی جمعیت های مربوطه، محقق با مشکل سازماندهی نمونه مواجه می شود. نمونه باید به گونه ای باشد که تعمیم نتایج مطالعه نمونه توجیه شود - تعمیم، گسترش آنها به جامعه عمومی. معیارهای اصلی اعتبار نتایج تحقیق— اینها نماینده نمونه و پایایی آماری نتایج (تجربی) هستند.
نمایندگی نمونه- به عبارت دیگر، بازنمایی آن توانایی نمونه برای بازنمایی کاملاً کامل پدیده های مورد مطالعه - از نقطه نظر تنوع آنها در جمعیت عمومی است.
البته، تنها جمعیت عمومی می توانند تصویر کاملی از پدیده مورد مطالعه، با تمام دامنه و تفاوت های ظریف آن ارائه دهند. بنابراین، بازنمایی همیشه به حدی محدود می شود که نمونه محدود باشد. و این معرف بودن نمونه است که ملاک اصلی در تعیین مرزهای تعمیم یافته های تحقیق است. با این حال، تکنیک هایی وجود دارد که امکان به دست آوردن نمونه ای از نمونه کافی برای محقق را فراهم می کند (این تکنیک ها در دوره "روانشناسی تجربی" مورد مطالعه قرار می گیرند).
اولین و تکنیک اصلی انتخاب تصادفی ساده (تصادفی) است. این شامل اطمینان از چنین شرایطی است که هر یک از اعضای جامعه شانس یکسانی با دیگران برای گنجاندن در نمونه داشته باشند. انتخاب تصادفی تضمین میکند که میتوان تعداد زیادی از نمایندگان جمعیت عمومی را در نمونه گنجاند. در این صورت تدابیر ویژه ای برای جلوگیری از پیدایش هر گونه الگو در حین انتخاب اتخاذ می شود. و این به ما امکان می دهد امیدوار باشیم که در نهایت، در نمونه، اموال مورد مطالعه، اگر نه در همه، در حداکثر تنوع ممکن، نشان داده شود.
راه دوم برای اطمینان از نمایندگی، نمونه گیری تصادفی طبقه ای یا انتخاب بر اساس ویژگی های جمعیت عمومی است. این شامل تعیین اولیه آن دسته از کیفیت هایی است که می تواند بر تغییرپذیری اموال مورد مطالعه تأثیر بگذارد (این می تواند جنسیت، سطح درآمد یا تحصیلات و غیره باشد). سپس نسبت درصدی تعداد گروهها (اقشار) که در این کیفیتها متفاوت هستند در جمعیت عمومی تعیین میشود و نسبت درصدی یکسان از گروههای مربوطه در نمونه تضمین میشود. سپس، آزمودنی ها در هر زیرگروه از نمونه بر اساس اصل انتخاب تصادفی ساده انتخاب می شوند.
اهمیت آماری،یا اهمیت آماری، نتایج یک مطالعه با استفاده از روش های استنتاج آماری تعیین می شود.
آیا هنگام تصمیم گیری، هنگام نتیجه گیری معین از نتایج تحقیق، از اشتباه کردن بیمه شده ایم؟ البته که نه. به هر حال، تصمیمات ما بر اساس نتایج مطالعه جامعه نمونه و همچنین بر اساس سطح دانش روانشناختی ما است. ما کاملاً از اشتباه مصون نیستیم. در آمار، چنین خطاهایی در صورتی قابل قبول تلقی می شوند که بیشتر از یک مورد از 1000 مورد رخ ندهند (احتمال خطا = 0.001 یا احتمال اطمینان مرتبط نتیجه گیری صحیح p = 0.999). در یک مورد از 100 (احتمال خطا = 0.01 یا احتمال اطمینان مرتبط نتیجه گیری صحیح p = 0.99) یا در پنج مورد از 100 (احتمال خطا = 0.05 α یا احتمال اطمینان مرتبط خروجی نتیجه گیری صحیح p=0.95). در دو سطح آخر است که در روانشناسی تصمیم گیری می شود.
گاهی اوقات، زمانی که در مورد معنیداری آماری صحبت میکنند، از مفهوم "سطح معنیداری" (که با α مشخص میشود) استفاده میکنند. مقادیر عددی p و α تا 1000 یکدیگر را تکمیل می کنند - مجموعه کاملی از رویدادها: یا نتیجه گیری درستی انجام دادیم یا اشتباه کردیم. این سطوح محاسبه نمی شود، داده می شود. سطح اهمیت را می توان به عنوان نوعی خط "قرمز" درک کرد که تقاطع آن به ما امکان می دهد از این رویداد به عنوان غیر تصادفی صحبت کنیم. در هر گزارش یا انتشار علمی خوب، نتایج به دست آمده باید با نشانه ای از مقادیر p یا α که در آن نتیجه گیری انجام شده است، همراه باشد.
روش های استنتاج آماری در درس آمار ریاضی به تفصیل مورد بحث قرار گرفته است. اکنون فقط توجه می کنیم که آنها الزامات خاصی برای تعداد یا اندازهی نمونه.
متأسفانه، هیچ دستورالعمل دقیقی برای از پیش تعیین حجم نمونه مورد نیاز وجود ندارد. علاوه بر این، محقق معمولاً پاسخ سؤال در مورد تعداد لازم و کافی را خیلی دیر دریافت می کند - تنها پس از تجزیه و تحلیل داده های یک نمونه از قبل بررسی شده. با این حال، کلی ترین توصیه ها را می توان فرموله کرد:
1. بیشترین حجم نمونه هنگام توسعه یک روش تشخیصی مورد نیاز است - از 200 تا 1000-2500 نفر.
2. در صورت نیاز به مقایسه 2 نمونه، تعداد کل آنها باید حداقل 50 نفر باشد. تعداد نمونه های مورد مقایسه باید تقریباً یکسان باشد.
3. اگر رابطه بین هر یک از خواص در حال مطالعه است، حجم نمونه باید حداقل 30-35 نفر باشد.
4. بیشتر تغییرپذیریاموال مورد مطالعه، اندازه نمونه باید بزرگتر باشد. بنابراین، تنوع را می توان با افزایش همگنی نمونه کاهش داد، مثلاً بر اساس جنسیت، سن و غیره.
نمونه های وابسته و مستقلیک موقعیت تحقیق رایج زمانی است که یک ویژگی مورد علاقه یک محقق بر روی دو یا چند نمونه به منظور مقایسه بیشتر مطالعه می شود. این نمونه ها بسته به روش سازماندهی آنها می توانند در نسبت های متفاوتی باشند. نمونه های مستقل با این واقعیت مشخص می شوند که احتمال انتخاب هر موضوعی در یک نمونه به انتخاب هیچ یک از موضوعات در نمونه دیگر بستگی ندارد. در برابر، نمونه های وابستهبا این واقعیت مشخص می شود که هر موضوع از یک نمونه با توجه به معیار خاصی با موضوعی از نمونه دیگر مطابقت داده می شود.
به طور کلی، نمونههای وابسته شامل انتخاب دوتایی آزمودنیها در نمونههای مقایسه شده است، و نمونههای مستقل دلالت بر انتخاب مستقل افراد دارند.
لازم به ذکر است که موارد نمونه های "جزئی وابسته" (یا "تا حدی مستقل") غیرقابل قبول است: این به طور غیرقابل پیش بینی نماینده آنها را نقض می کند.
در خاتمه متذکر می شویم که دو پارادایم تحقیق روانشناختی قابل تفکیک است.
باصطلاح روش شناسی Rشامل مطالعه تغییرپذیری یک ویژگی خاص (روانی) تحت تأثیر یک تأثیر خاص، عامل یا ویژگی دیگر است. نمونه مجموعه ای از موضوعات است.
رویکرد دیگر روش شناسی کیو،شامل مطالعه تغییرپذیری یک موضوع (فرد) تحت تأثیر محرک های مختلف (شرایط، موقعیت ها و غیره) است. مطابق با وضعیتی است که نمونه مجموعه ای از محرک ها است.