 入り口
入り口標準偏差はどのように計算されますか? 標準偏差を計算するにはどうすればよいですか? モードの大きさを計算してみましょう
仮説の統計的検定において、確率変数間の線形関係を測定する場合。
平均 標準偏差:
標準偏差(確率変数の標準偏差の推定値 床、周囲の壁、天井、 バツ分散の不偏推定に基づく数学的期待値と比較して):
分散はどこにあるのか。 - 床、周囲の壁、天井、 私選択範囲の 番目の要素。 - サンプルサイズ; - サンプルの算術平均:
どちらの推定値にも偏りがあることに注意してください。 一般的なケースでは、不偏な推定値を構築することは不可能です。 ただし、不偏分散推定値に基づく推定値は一貫しています。
スリーシグマの法則
スリーシグマの法則() - 正規分布確率変数のほぼすべての値は区間内にあります。 より厳密には、99.7% 以上の信頼度で、正規分布確率変数の値は指定された区間内にあります (値が真であり、サンプル処理の結果として取得されたものではない場合)。
真の値が不明な場合は、床、周囲の壁、天井を使用する必要があります。 s。 したがって、スリーシグマの法則は、床、周囲の壁、天井の 3 つのルールに変換され、 s .
標準偏差値の解釈
標準偏差の値が大きいと、提示されたセット内の値の広がりが大きいことを示します。 平均サイズ群衆。 小さい値したがって、セット内の値が平均値を中心にグループ化されていることを示します。
たとえば、(0, 0, 14, 14)、(0, 6, 8, 14)、および (6, 6, 8, 8) の 3 つの数値セットがあります。 3 つのセットすべての平均値は 7、標準偏差はそれぞれ 7、5、1 です。最後のセットは、セット内の値が平均値を中心にグループ化されているため、標準偏差が小さくなります。 最初のセットが最も多くの 非常に重要標準偏差 - セット内の値が平均値から大きく乖離しています。
一般に、標準偏差は不確実性の尺度であると考えることができます。 たとえば、物理学では、標準偏差は、ある量の一連の連続測定の誤差を決定するために使用されます。 この値は、理論によって予測された値と比較して、研究中の現象の妥当性を判断するために非常に重要です。測定値の平均値が理論によって予測された値と大きく異なる場合(標準偏差が大きい場合)、取得した値またはそれらを取得する方法を再確認する必要があります。
実用
実際には、標準偏差を使用して、セット内の値が平均値とどの程度異なるかを判断できます。
気候
1 日の平均最高気温が同じ 2 つの都市があり、1 つは海岸沿いにあり、もう 1 つは内陸にあるとします。 海岸沿いに位置する都市は、内陸に位置する都市よりも日中の最高気温がさまざまに異なり、低いことが知られています。 したがって、沿岸都市の日最高気温の標準偏差は、平均値が同じであるにもかかわらず、2 番目の都市よりも小さくなります。これは、実際には、次の確率が存在することを意味します。 最高温度一年の特定の日ごとの空気は平均値からより大きく異なり、大陸の内側に位置する都市ほど高くなります。
スポーツ
いくつかのサッカー チームが、得点数や失点数、得点チャンスなどのパラメータに基づいて評価されていると仮定します。このグループ内で最も優れたチームがより良い値を持つ可能性が最も高くなります。さらに多くのパラメータについて。 提示された各パラメーターのチームの標準偏差が小さいほど、チームの結果の予測可能性が高くなります。そのようなチームはバランスが取れています。 一方、次のチームは、 すごい価値標準偏差により結果の予測が困難になりますが、これは、たとえば防御が強いが攻撃が弱いなどの不均衡によって説明されます。
チームパラメータの標準偏差を使用すると、2 つのチーム間の試合の結果をある程度予測し、強みや強さを評価することができます。 弱い面命令、したがって選択された闘争方法。
テクニカル分析
こちらも参照
文学
| この記事は削除が提案されています。
理由の説明と対応する議論は、このページにあります。 Wikipedia: 削除予定/2012 年 12 月 17 日。 |
* ボロビコフ、V.統計。 コンピューター上のデータ分析の技術: 専門家向け / V. ボロビコフ。 - サンクトペテルブルク。 : ピーター、2003. - 688 p. - ISBN 5-272-00078-1.
| 統計指標 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 説明的な 統計 |
|
||||||||||
| 統計的 出力と 検査 仮説 |
| ||||||||||
標準偏差は、企業の世界における統計用語の 1 つで、会話やプレゼンテーションでそれをうまくやり遂げた人には信頼性を与えますが、それが何なのかは知らないが恥ずかしくて話せない人にとっては漠然とした混乱を残します。聞く。 実際、ほとんどのマネージャーは標準偏差の概念を理解していません。もしあなたがそのような人なら、嘘をついて生きるのをやめるべき時が来ました。 今日の記事では、この過小評価されている統計的尺度が、扱っているデータをより深く理解するのにどのように役立つかを説明します。
標準偏差は何を測定するのでしょうか?
あなたが 2 つの店舗のオーナーであると想像してください。 損失を避けるためには、株式残高を明確に管理することが重要です。 どのマネージャーがより適切に在庫を管理しているかを調べるために、過去 6 週間の在庫を分析することにしました。 両店舗の週平均在庫コストはほぼ同じで、従来型の約 32 ユニットに相当します。 一見したところ、平均ランオフは両マネージャーのパフォーマンスが同様であることを示しています。

しかし、2 番目の店舗の活動を詳しく見てみると、平均値は正しいものの、在庫の変動が非常に大きい (10 ドルから 58 ドルまで) ことがわかるでしょう。 したがって、平均によってデータが常に正しく評価されるわけではないと結論付けることができます。 ここが救いです 標準偏差.
標準偏差は、値が の平均に対してどのように分布しているかを示します。 つまり、週ごとに流出量の広がりがどれだけ大きいかがわかります。
この例では、Excel の STDEV 関数を使用して、平均値とともに標準偏差を計算しました。

最初のマネージャーの場合、標準偏差は 2 でした。これは、サンプル内の各値が平均して平均から 2 ずれていることを示しています。 良いですか? 別の角度から質問を見てみましょう。標準偏差 0 は、サンプル内の各値が平均 (この場合は 32.2) に等しいことを示します。 したがって、標準偏差 2 は 0 と大差なく、ほとんどの値が平均値に近いことを示します。 標準偏差が 0 に近づくほど、平均の信頼性が高くなります。 さらに、標準偏差が 0 に近い場合は、データの変動がほとんどないことを示します。 つまり、標準偏差 2 のランオフ値は、最初のマネージャーの信じられないほどの一貫性を示しています。
2 店舗目の場合、標準偏差は 18.9 でした。 つまり、流出コストは平均して週ごとに平均値から 18.9 ずれます。 クレイジーな広がり! 標準偏差が 0 から離れるほど、平均の精度は低くなります。 私たちの場合、18.9 という数字は、平均値 (1 週間あたり 32.8 米ドル) が単純に信頼できないことを示しています。 また、毎週の流出量が大きく変動することもわかります。
これが標準偏差の概念です。 他の重要な統計測定値 (最頻値、中央値など) についての洞察は得られませんが、実際、標準偏差はほとんどの統計計算で重要な役割を果たします。 標準偏差の原理を理解すると、多くのビジネス プロセスが明らかになります。
標準偏差を計算するにはどうすればよいですか?
これで、標準偏差の数値が何を意味するかがわかりました。 どのように計算されるのか見てみましょう。
10 から 70 までのデータセットを 10 刻みで見てみましょう。ご覧のとおり、セル H2 (オレンジ色) で STANDARDEV 関数を使用して、それらの標準偏差値がすでに計算されています。

以下は、Excel が 21.6 に到達するまでに実行する手順です。
理解を深めるために、すべての計算が視覚化されていることに注意してください。 実際、Excel では計算は瞬時に行われ、すべての手順は舞台裏で行われます。
まず、Excel は標本の平均値を求めます。 この場合、平均は 40 であることが判明し、次のステップで各サンプル値から減算されます。 得られた各差は二乗されて合計されます。 合計は 2800 になり、サンプル要素の数から 1 を引いた値で割る必要があります。要素が 7 つあるため、2800 を 6 で割る必要があることがわかります。結果から次のことがわかります。 平方根, この数値が標準偏差になります。

視覚化を使用して標準偏差を計算する原理がよくわからない人のために、この値を求める数学的解釈を示します。

Excelで標準偏差を計算する関数
Excel にはいくつかの種類の標準偏差の式があります。 =STDEV と入力するだけで確認できます。

関数 STDEV.V と STDEV.G (リストの 1 番目と 2 番目の関数) は、関数 STDEV と STDEV (リストの 5 番目と 6 番目の関数) をそれぞれ複製していることに注意してください。これらは、より多くの関数との互換性のために残されています。 以前のバージョンエクセル。
一般に、.B 関数と .G 関数の末尾の違いは、サンプルまたはサンプルの標準偏差を計算する原理を示します。 人口。 これら 2 つの配列の違いについては、前の配列ですでに説明しました。
STANDARDEV 関数と STANDDREV 関数 (リストの 3 番目と 4 番目の関数) の特別な特徴は、配列の標準偏差を計算するときに、論理値とテキスト値が考慮されることです。 Text と true boolean 値は 1、false boolean 値は 0 です。これら 2 つの関数が必要になる状況は想像できないので、無視してよいと思います。
統計分析の主なツールの 1 つは標準偏差の計算です。 この指標を使用すると、サンプルまたは母集団の標準偏差を推定できます。 Excelで標準偏差の計算式を使用する方法を学びましょう。
それが何であるかをすぐに定義しましょう 標準偏差そしてその式がどのようなものであるか。 この値は平均の平方根です 算術数字系列のすべての値とその算術平均の差の二乗。 この指標には同じ名前、標準偏差があります。 どちらの名前も完全に同等です。
ただし、当然のことながら、Excel ではプログラムがすべてを行うため、ユーザーがこれを計算する必要はありません。 Excelで標準偏差を計算する方法を学びましょう。
Excelでの計算
2 つの特別な関数を使用して Excel で指定された値を計算できます STDEV.V(サンプル母集団に基づく) および STDEV.G(一般人口に基づく)。 それらの動作原理はまったく同じですが、以下で説明する 3 つの方法で呼び出すことができます。
方法 1: 関数ウィザード


方法 2: [数式] タブ


方法 3: 数式を手動で入力する
引数ウィンドウをまったく呼び出す必要がない方法もあります。 これを行うには、数式を手動で入力する必要があります。


ご覧のとおり、Excel で標準偏差を計算するメカニズムは非常に簡単です。 ユーザーは、母集団からの数値を入力するか、その数値を含むセルへの参照を入力するだけで済みます。 すべての計算はプログラム自体によって実行されます。 計算された指標が何であるか、また計算結果が実際にどのように適用できるかを理解することははるかに困難です。 しかし、これを理解することは、ソフトウェアの操作方法を学ぶことよりも、統計の分野にすでに関係しています。
標準偏差は、記述統計によるばらつきの古典的な指標です。
標準偏差、標準偏差、標準偏差、サンプル標準偏差 (英語標準偏差、STD、STDev) - 分散を示す非常に一般的な指標です。 記述統計。 しかし理由は テクニカル分析は統計に似ており、このインジケーターは分析対象商品の価格の時間の経過に伴う分散の程度を検出するためにテクニカル分析で使用できます(また使用する必要があります)。 ギリシャ記号シグマ「σ」で表されます。
標準偏差の使用を許可してくれた Karl Gauss と Pearson に感謝します。
使用する テクニカル分析の標準偏差、これを回します 「分散指数」「V 「ボラティリティ指標」」という意味を維持しながら、用語を変更します。
標準偏差とは何ですか
ただし、中間の補助計算のほかに、 標準偏差は独立した計算では十分に許容されますテクニカル分析への応用も可能です。 私たちの雑誌の積極的な読者であるゴボウは次のように述べています。 国内ディーリングセンターの標準指標に標準偏差が含まれていない理由がいまだにわかりません«.
本当に、 標準偏差は、古典的かつ「純粋な」方法で機器の変動性を測定できます。。 しかし、残念ながら、この指標は証券分析ではあまり一般的ではありません。
標準偏差の適用
標準偏差を手動で計算するのはあまり面白くありません、しかし経験には役立ちます。 標準偏差を表現できる式 STD=√[(∑(x-x ) 2)/n] は、サンプルの要素と平均の差の二乗和の根をサンプル内の要素の数で割ったもののように聞こえます。
サンプル内の要素の数が 30 を超える場合、根の下の分数の分母は値 n-1 になります。 それ以外の場合は、n が使用されます。
一歩ずつ 標準偏差の計算:
- データサンプルの算術平均を計算します
- この平均を各サンプル要素から減算します。
- 結果として生じる差をすべて二乗します
- 結果として得られるすべての平方を合計します
- 結果の量をサンプル内の要素の数で割ります (n>30 の場合は n-1 で割ります)。
- 結果の商の平方根を計算します ( 分散)
$X$。 まず、次の定義を思い出してください。
定義 1
人口-- ランダムに選択された特定のタイプのオブジェクトのセット。ランダム変数の特定の値を取得するために観察が実行され、特定のタイプの 1 つの確率変数を研究するときに一定の条件下で実行されます。
定義 2
一般的な差異-- 母集団バリアントの値の平均値からの偏差の二乗の算術平均。
オプション $x_1,\ x_2,\dots ,x_k$ の値がそれぞれ、頻度 $n_1,\ n_2,\dots ,n_k$ を持つものとします。 次に、一般分散は次の式を使用して計算されます。
特殊な場合を考えてみましょう。 すべてのオプション $x_1,\ x_2,\dots ,x_k$ を異なるものにします。 この場合、$n_1,\ n_2,\dots ,n_k=1$ となります。 この場合、一般分散は次の式を使用して計算されることがわかります。
この概念は、一般標準偏差の概念にも関連付けられています。
定義 3
一般的な標準偏差
\[(\sigma )_g=\sqrt(D_g)\]
サンプルの分散
確率変数 $X$ に関するサンプル母集団を与えてみましょう。 まず、次の定義を思い出してください。
定義 4
サンプル母集団 -- 一般集団から選択されたオブジェクトの一部。
定義5
サンプルの分散- 平均 算術値サンプリングオプション。
オプション $x_1,\ x_2,\dots ,x_k$ の値がそれぞれ、頻度 $n_1,\ n_2,\dots ,n_k$ を持つものとします。 次に、標本分散は次の式を使用して計算されます。
特殊な場合を考えてみましょう。 すべてのオプション $x_1,\ x_2,\dots ,x_k$ を異なるものにします。 この場合、$n_1,\ n_2,\dots ,n_k=1$ となります。 この場合、標本分散は次の式を使用して計算されることがわかります。
この概念に関連するのは、標本標準偏差の概念です。
定義6
サンプル標準偏差-- 一般分散の平方根:
\[(\sigma )_в=\sqrt(D_в)\]
修正された差異
修正分散 $S^2$ を求めるには、サンプル分散に分数 $\frac(n)(n-1)$ を掛ける必要があります。
この概念は、次の式で求められる補正標準偏差の概念にも関連付けられています。
バリアントの値が離散的ではなく、区間を表す場合、一般分散または標本分散を計算する式では、$x_i$ の値が区間の中央の値とみなされます。 $x_i.$ が属するもの。
分散と標準偏差を求める問題の例
例1
サンプル母集団は次の分布表によって定義されます。
写真1。
それについて、標本分散、標本標準偏差、修正分散、修正標準偏差を求めてみましょう。
この問題を解決するには、まず計算表を作成します。
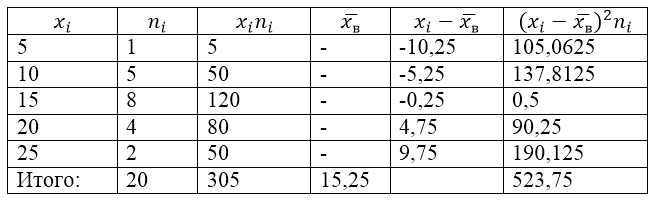
図2。
表内の値 $\overline(x_в)$ (サンプル平均) は、次の式で求められます。
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)\]
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)=\frac(305)(20)=15.25\]
次の式を使用して標本分散を求めてみましょう。
サンプル標準偏差:
\[(\sigma )_в=\sqrt(D_в)\約 5.12\]
修正された差異:
\[(S^2=\frac(n)(n-1)D)_в=\frac(20)(19)\cdot 26.1875\約 27.57\]
標準偏差を修正しました。