 Eingang
EingangDie Standardabweichung wird ausgedrückt. Anwenden der Standardabweichung. Notiz. Warum genau quadrierte Differenzen?
Es ist erwähnenswert, dass diese Varianzberechnung einen Nachteil hat – sie erweist sich als voreingenommen, d. h. seine mathematische Erwartung ist nicht gleich wahre Bedeutung Abweichungen. Lesen Sie mehr darüber. Dabei ist nicht alles so schlimm. Mit zunehmender Stichprobengröße nähert es sich immer noch seinem theoretischen Analogon an, d. h. ist asymptotisch erwartungsfrei. Daher bei der Arbeit mit große Größen Proben können Sie die obige Formel verwenden.
Es ist sinnvoll, die Sprache der Zeichen in die Sprache der Wörter zu übersetzen. Es stellt sich heraus, dass die Varianz das durchschnittliche Quadrat der Abweichungen ist. Das heißt, zuerst wird der Durchschnittswert berechnet, dann wird die Differenz zwischen jedem Original- und Durchschnittswert gebildet, quadriert, addiert und dann durch die Anzahl der Werte in der Grundgesamtheit dividiert. Die Differenz zwischen einem Einzelwert und dem Durchschnitt gibt das Maß der Abweichung wieder. Quadriert, so dass alle Abweichungen ausschließlich werden positive Zahlen und bei der Zusammenfassung eine gegenseitige Zerstörung positiver und negativer Abweichungen zu vermeiden. Dann berechnen wir anhand der quadrierten Abweichungen einfach das arithmetische Mittel. Durchschnitt – Quadrat – Abweichungen. Die Abweichungen werden quadriert und der Durchschnitt berechnet. Die Lösung liegt in nur drei Worten.
In reiner Form wie dem arithmetischen Mittel oder dem Index wird die Dispersion jedoch nicht verwendet. Es handelt sich vielmehr um einen Hilfs- und Zwischenindikator, der für andere Arten statistischer Analysen erforderlich ist. Es gibt nicht einmal eine normale Maßeinheit. Der Formel nach zu urteilen, ist dies das Quadrat der Maßeinheit der Originaldaten. Ohne eine Flasche kommt man, wie man so schön sagt, nicht raus.
(Modul 111)
Um die Varianz wieder in die Realität umzusetzen, also für alltäglichere Zwecke zu nutzen, wird daraus die Quadratwurzel gezogen. Es stellt sich das sogenannte heraus Standardabweichung(RMS). Es gibt Namen „Standardabweichung“ oder „Sigma“ (vom Namen des griechischen Buchstabens). Die Standardabweichungsformel lautet:
![]()
Um diesen Indikator für die Stichprobe zu erhalten, verwenden Sie die Formel:

Wie bei der Varianz gibt es eine etwas andere Berechnungsmöglichkeit. Aber wenn die Stichprobe wächst, verschwindet der Unterschied.
Die Standardabweichung charakterisiert natürlich auch das Maß der Datenstreuung, kann aber nun (im Gegensatz zur Streuung) mit den Originaldaten verglichen werden, da diese die gleichen Maßeinheiten haben (dies geht aus der Berechnungsformel hervor). Dieser Indikator in seiner reinen Form ist jedoch nicht sehr aussagekräftig, da er zu viele Zwischenberechnungen enthält, die verwirrend sind (Abweichung, Quadrat, Summe, Durchschnitt, Wurzel). Es ist jedoch bereits möglich, direkt mit der Standardabweichung zu arbeiten, da die Eigenschaften dieses Indikators gut untersucht und bekannt sind. Da gibt es zum Beispiel dieses Drei-Sigma-Regel, was besagt, dass die Daten 997 von 1000 Werten innerhalb von ±3 Sigma des arithmetischen Mittels aufweisen. Auch die Standardabweichung als Maß für die Unsicherheit spielt bei vielen statistischen Berechnungen eine Rolle. Mit seiner Hilfe wird der Genauigkeitsgrad verschiedener Schätzungen und Prognosen ermittelt. Wenn die Variation sehr groß ist, ist auch die Standardabweichung groß und daher wird die Prognose ungenau sein, was sich beispielsweise in sehr breiten Konfidenzintervallen ausdrückt.
Der Variationskoeffizient
Die Standardabweichung gibt eine absolute Schätzung des Streuungsmaßes an. Daher ist es erforderlich, zu verstehen, wie groß die Streuung im Verhältnis zu den Werten selbst (d. h. unabhängig von ihrer Skala) ist relativer Indikator. Dieser Indikator heißt Variationskoeffizient und wird nach folgender Formel berechnet:
Der Variationskoeffizient wird als Prozentsatz gemessen (bei Multiplikation mit 100 %). Mit diesem Indikator können Sie eine Vielzahl von Phänomenen vergleichen, unabhängig von deren Ausmaß und Maßeinheiten. Dieser Fakt und macht den Variationskoeffizienten so beliebt.
In der Statistik wird angenommen, dass die Population als homogen gilt, wenn der Wert des Variationskoeffizienten weniger als 33 % beträgt; wenn er mehr als 33 % beträgt, ist sie heterogen. Es fällt mir schwer, hier etwas zu kommentieren. Ich weiß nicht, wer das definiert hat und warum, aber es gilt als Axiom.
Ich habe das Gefühl, dass ich von der trockenen Theorie mitgerissen werde und etwas Visuelles und Figuratives einbringen muss. Andererseits beschreiben alle Variationsindikatoren ungefähr dasselbe, nur werden sie unterschiedlich berechnet. Daher ist es schwierig, eine Vielzahl von Beispielen anzuführen. Nur die Werte von Indikatoren können unterschiedlich sein, nicht jedoch ihr Wesen. Vergleichen wir also, wie sich die Werte verschiedener Variationsindikatoren für denselben Datensatz unterscheiden. Nehmen wir das Beispiel der Berechnung der durchschnittlichen linearen Abweichung (von ). Hier sind die Quelldaten:

Und ein Zeitplan, der Sie daran erinnert.

Anhand dieser Daten berechnen wir verschiedene Variationsindikatoren.
Der Durchschnittswert ist der übliche arithmetische Durchschnitt.
Der Variationsbereich ist die Differenz zwischen Maximum und Minimum:
Die durchschnittliche lineare Abweichung wird nach folgender Formel berechnet:
Fassen wir die Berechnung in einer Tabelle zusammen.

Wie zu sehen ist, ergeben sich der lineare Durchschnitt und die Standardabweichung gleiche Bedeutung Grad der Datenvariation. Die Varianz ist Sigma-Quadrat, daher ist sie immer relativ eine große Anzahl, was eigentlich gar nichts bedeutet. Die Variationsbreite ist die Differenz zwischen Extremwerten und kann Bände sprechen.
Fassen wir einige Ergebnisse zusammen.
Die Variation eines Indikators spiegelt die Variabilität eines Prozesses oder Phänomens wider. Sein Grad kann anhand mehrerer Indikatoren gemessen werden.
1. Variationsbereich – die Differenz zwischen Maximum und Minimum. Spiegelt den Bereich möglicher Werte wider.
2. Durchschnittliche lineare Abweichung – spiegelt den Durchschnitt der absoluten (Modulo-)Abweichungen aller Werte der analysierten Grundgesamtheit von ihrem Durchschnittswert wider.
3. Streuung – das durchschnittliche Quadrat der Abweichungen.
4. Die Standardabweichung ist die Wurzel der Streuung (das mittlere Quadrat der Abweichungen).
5. Der Variationskoeffizient ist der universellste Indikator und spiegelt den Grad der Streuung von Werten wider, unabhängig von deren Maßstab und Maßeinheiten. Der Variationskoeffizient wird in Prozent gemessen und kann zum Vergleich der Variation verschiedener Prozesse und Phänomene verwendet werden.
Somit gibt es in der statistischen Analyse ein System von Indikatoren, die die Homogenität von Phänomenen und die Stabilität von Prozessen widerspiegeln. Variationsindikatoren haben oft keine eigenständige Bedeutung und werden für die weitere Datenanalyse (Berechnung von Konfidenzintervallen) verwendet
Material aus Wikipedia – der freien Enzyklopädie
Standardabweichung(Synonyme: Standardabweichung, Standardabweichung, quadratische Abweichung; verwandte Begriffe: Standardabweichung, Standardaufstrich) – in der Wahrscheinlichkeitstheorie und Statistik der häufigste Indikator für die Streuung der Werte einer Zufallsvariablen relativ zu ihrer mathematischen Erwartung. Bei begrenzten Arrays von Stichprobenwerten wird anstelle des mathematischen Erwartungswerts das arithmetische Mittel der Stichprobenmenge verwendet.
Grundinformation
Die Standardabweichung wird in Einheiten der Zufallsvariablen selbst gemessen und bei der Berechnung des Standardfehlers des arithmetischen Mittels, bei der Konstruktion von Konfidenzintervallen, bei der statistischen Prüfung von Hypothesen und bei der Messung der linearen Beziehung zwischen Zufallsvariablen verwendet. Definiert als Quadratwurzel der Varianz einer Zufallsvariablen.
Standardabweichung:
Standardabweichung(Schätzung der Standardabweichung einer Zufallsvariablen X relativ zu seiner mathematischen Erwartung basierend auf einer unvoreingenommenen Schätzung seiner Varianz) :
Drei-Sigma-Regel
Drei-Sigma-Regel () – fast alle Werte einer normalverteilten Zufallsvariablen liegen im Intervall . Genauer gesagt: Mit einer Wahrscheinlichkeit von ungefähr 0,9973 liegt der Wert einer normalverteilten Zufallsvariablen im angegebenen Intervall (vorausgesetzt, der Wert wahr und nicht als Ergebnis der Probenverarbeitung erhalten).
Wenn der wahre Wert unbekannt ist, sollten Sie es nicht verwenden , A S. Somit wird die Drei-Sigma-Regel in die Drei-Regel umgewandelt S .
Interpretation des Standardabweichungswerts
Ein größerer Wert der Standardabweichung zeigt eine größere Streuung der Werte im dargestellten Satz mit durchschnittliche Größe Massen; ein kleinerer Wert zeigt dementsprechend an, dass die Werte in der Menge um den Durchschnittswert gruppiert sind.
Wir haben zum Beispiel drei Zahlenmengen: (0, 0, 14, 14), (0, 6, 8, 14) und (6, 6, 8, 8). Alle drei Sätze haben Mittelwerte von 7 und Standardabweichungen von 7, 5 und 1. Der letzte Satz weist eine kleine Standardabweichung auf, da die Werte im Satz um den Mittelwert gruppiert sind; Der erste Satz hat die meisten sehr wichtig Standardabweichung – Werte innerhalb der Menge weichen stark vom Durchschnittswert ab.
Im Allgemeinen kann die Standardabweichung als Maß für die Unsicherheit betrachtet werden. Beispielsweise wird in der Physik die Standardabweichung verwendet, um den Fehler einer Reihe aufeinanderfolgender Messungen einer bestimmten Größe zu bestimmen. Dieser Wert ist sehr wichtig, um die Plausibilität des untersuchten Phänomens im Vergleich zum von der Theorie vorhergesagten Wert zu bestimmen: Wenn der Durchschnittswert der Messungen stark von den von der Theorie vorhergesagten Werten abweicht (große Standardabweichung), dann sollten die erhaltenen Werte bzw. die Methode zu deren Ermittlung noch einmal überprüft werden.
Praktischer Nutzen
In der Praxis können Sie anhand der Standardabweichung abschätzen, um wie viel Werte aus einer Menge vom Durchschnittswert abweichen können.
Wirtschaft und Finanzen
Standardabweichung der Portfoliorendite mit Portfoliorisiko identifiziert.
Klima
Angenommen, es gibt zwei Städte mit der gleichen durchschnittlichen Tageshöchsttemperatur, aber eine liegt an der Küste und die andere in der Ebene. Es ist bekannt, dass Städte an der Küste viele unterschiedliche maximale Tagestemperaturen aufweisen, die niedriger sind als Städte im Landesinneren. Daher wird die Standardabweichung der maximalen Tagestemperaturen für eine Küstenstadt geringer sein als für eine zweite Stadt, obwohl ihr Durchschnittswert gleich ist, was in der Praxis bedeutet, dass die Wahrscheinlichkeit, dass Maximale Temperatur Luft an jedem einzelnen Tag des Jahres wird stärker vom Durchschnittswert abweichen, der für eine Stadt innerhalb des Kontinents höher ist.
Sport
Nehmen wir an, dass es mehrere Fußballmannschaften gibt, die nach bestimmten Parametern bewertet werden, zum Beispiel nach der Anzahl der erzielten und kassierten Tore, den Torchancen usw. Es ist am wahrscheinlichsten, dass die beste Mannschaft in dieser Gruppe bessere Werte hat auf weitere Parameter. Je kleiner die Standardabweichung des Teams für jeden der dargestellten Parameter ist, desto vorhersehbarer ist das Ergebnis des Teams; solche Teams sind ausgeglichen. Andererseits ist das Team mit großer Wert Die Standardabweichung macht es schwierig, das Ergebnis vorherzusagen, was wiederum durch ein Ungleichgewicht erklärt wird, beispielsweise eine starke Verteidigung, aber einen schwachen Angriff.
Die Verwendung der Standardabweichung der Teamparameter ermöglicht es, bis zu einem gewissen Grad das Ergebnis eines Spiels zwischen zwei Teams vorherzusagen, die Stärken zu bewerten und schwache Seiten Befehle und damit die gewählten Kampfmethoden.
siehe auch
Schreiben Sie eine Rezension zum Artikel „Root Mean Square Deviation“
Literatur
- Borowikow V. STATISTIKEN. Die Kunst der Datenanalyse am Computer: Für Profis / V. Borovikov. - St. Petersburg. : Peter, 2003. - 688 S. - ISBN 5-272-00078-1..
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Ein Auszug zur Charakterisierung der Standardabweichung
Und er öffnete schnell die Tür und trat mit entschlossenen Schritten auf den Balkon hinaus. Das Gespräch verstummte plötzlich, Hüte und Mützen wurden abgenommen und alle Blicke richteten sich auf den Grafen, der herausgekommen war.- Hallo Leute! - sagte der Graf schnell und laut. - Danke fürs Kommen. Ich möchte mich jetzt zu Ihnen äußern, aber zuerst müssen wir uns um den Bösewicht kümmern. Wir müssen den Bösewicht bestrafen, der Moskau getötet hat. Warte auf mich! „Und der Graf kehrte ebenso schnell in seine Gemächer zurück und schlug die Tür fest zu.
Ein freudiges Murmeln ging durch die Menge. „Das bedeutet, dass er alle Schurken kontrollieren wird! Und du sagst Französisch ... er wird dir die ganze Distanz geben!“ - sagten die Leute, als würden sie sich gegenseitig ihren mangelnden Glauben vorwerfen.
Ein paar Minuten später kam ein Offizier eilig aus der Vordertür, befahl etwas, und die Dragoner standen auf. Die Menge vom Balkon bewegte sich eifrig zur Veranda. Mit wütenden, schnellen Schritten ging Rostopchin auf die Veranda und sah sich hastig um, als suche er nach jemandem.
- Wo ist er? - sagte der Graf, und im selben Moment, als er das sagte, sah er um die Ecke des Hauses zwei Dragoner herauskommen junger Mann mit langem, dünnem Hals, mit halbrasiertem und überwuchertem Kopf. Dieser junge Mann trug einen einstmals eleganten, mit blauem Stoff überzogenen, schäbigen Fuchsschaffellmantel und schmutzige Gefangenen-Haremshosen, die in ungereinigte, abgenutzte dünne Stiefel gestopft waren. Fesseln hingen schwer an seinen dünnen, schwachen Beinen und machten es dem jungen Mann schwer, unentschlossen zu gehen.
- A! - sagte Rastopchin, wandte seinen Blick hastig von dem jungen Mann im Fuchs-Lammfellmantel ab und zeigte auf die unterste Stufe der Veranda. - Stell es hier ab! - Der junge Mann trat mit klirrenden Fesseln schwerfällig auf die angezeigte Stufe, hielt mit dem Finger den Kragen seines Schaffellmantels fest und drehte ihn zweimal langer Hals und faltete seufzend seine dünnen, müßigen Hände mit einer unterwürfigen Geste vor seinem Bauch.
Es herrschte mehrere Sekunden lang Stille, während der junge Mann sich auf der Stufe aufstellte. Nur in den hinteren Reihen der Menschen, die sich an einen Ort drängten, war Stöhnen, Stöhnen, Zittern und das Stampfen sich bewegender Füße zu hören.
Rastopchin, der darauf wartete, dass er an der angegebenen Stelle anhielt, runzelte die Stirn und rieb sich mit der Hand das Gesicht.
- Jungs! - sagte Rastopchin mit metallisch klingender Stimme, - dieser Mann, Wereschtschagin, ist derselbe Schurke, an dem Moskau zugrunde ging.
Ein junger Mann in einem Fuchs-Lammfellmantel stand in unterwürfiger Haltung da, verschränkte die Hände vor dem Bauch und beugte sich leicht vor. Sein abgemagerter, hoffnungsloser Gesichtsausdruck, entstellt durch seinen rasierten Kopf, war niedergeschlagen. Bei den ersten Worten des Grafen hob er langsam den Kopf und blickte auf den Grafen herab, als wolle er ihm etwas sagen oder ihm zumindest in die Augen sehen. Aber Rastopchin sah ihn nicht an. Am langen, dünnen Hals des jungen Mannes wurde die Ader hinter dem Ohr wie ein Seil angespannt und blau, und plötzlich wurde sein Gesicht rot.
Alle Augen waren auf ihn gerichtet. Er schaute auf die Menge, und als wäre er durch den Ausdruck, den er auf den Gesichtern der Menschen las, ermutigt worden, lächelte er traurig und schüchtern und stellte, wieder den Kopf senkend, seine Füße auf die Stufe.
„Er hat seinen Zaren und sein Vaterland verraten, er hat sich Bonaparte ausgeliefert, er hat als einziger von allen Russen den Namen des Russen entehrt, und Moskau geht an ihm zugrunde“, sagte Rastopchin mit gleichmäßiger, scharfer Stimme; aber plötzlich blickte er schnell auf Wereschtschagin herab, der weiterhin in derselben unterwürfigen Haltung dastand. Als hätte ihn dieser Blick explodieren lassen, hätte er, die Hand hebend, fast geschrien und sich an die Menschen gewandt: „Behandeln Sie ihn mit Ihrem Urteil!“ Ich gebe es dir!
Die Menschen schwiegen und drängten sich nur immer enger aneinander. Sich gegenseitig festzuhalten, diese ansteckende Verstopfung einzuatmen, nicht die Kraft zu haben, sich zu bewegen und auf etwas Unbekanntes, Unverständliches und Schreckliches zu warten, wurde unerträglich. Die Menschen, die in den ersten Reihen standen und alles sahen und hörten, was vor ihnen geschah, alle mit ängstlich weit aufgerissenen Augen und offenen Mündern, hielten mit aller Kraft den Druck der Hinter ihnen auf dem Rücken zurück.
- Schlag ihn! Lass den Verräter sterben und blamiere nicht den Namen des Russen! - schrie Rastopchin. - Rubin! Ich bestelle! - Als die Menge keine Worte, sondern die wütenden Töne von Rastopchins Stimme hörte, stöhnte sie und bewegte sich vorwärts, blieb aber wieder stehen.
„Graf!...“, sagte Wereschtschagins schüchterne und zugleich theatralische Stimme inmitten der erneuten kurzen Stille. „Graf, ein Gott ist über uns ...“ sagte Wereschtschagin und hob den Kopf, und wieder füllte sich die dicke Ader an seinem dünnen Hals mit Blut, und die Farbe erschien schnell und lief aus seinem Gesicht. Er beendete nicht, was er sagen wollte.
- Hacken Sie ihn! Ich bestelle!.. - schrie Rastopchin und wurde plötzlich blass, genau wie Wereschtschagin.
- Säbel raus! - rief der Offizier den Dragonern zu und zog selbst seinen Säbel.
Eine weitere, noch stärkere Welle fegte durch die Menschen, und als diese Welle die ersten Reihen erreichte, bewegte sie die ersten Reihen taumelnd und brachte sie bis zu den Stufen der Veranda. Ein großer Kerl mit versteinertem Gesichtsausdruck und erhobener Hand stand neben Wereschtschagin.
- Rubin! - Fast flüsterte ein Offizier den Dragonern zu, und einer der Soldaten schlug plötzlich mit vor Wut verzerrtem Gesicht Wereschtschagin mit einem stumpfen Breitschwert auf den Kopf.
"A!" - Wereschtschagin schrie kurz und überrascht auf, sah sich ängstlich um und als würde er nicht verstehen, warum ihm das angetan wurde. Das gleiche Stöhnen der Überraschung und des Entsetzens ging durch die Menge.
"Oh mein Gott!" – Jemandes trauriger Ausruf war zu hören.
Doch nach dem Ausruf der Überraschung, der Wereschtschagin entfuhr, schrie er erbärmlich vor Schmerz auf, und dieser Schrei zerstörte ihn. Das hat sich in die Länge gezogen Höchster Abschluss Die Barriere menschlicher Gefühle, die die Menge noch immer festhielt, durchbrach augenblicklich. Das Verbrechen war begonnen, es galt, es zu Ende zu bringen. Das klägliche Stöhnen des Vorwurfs wurde von dem drohenden und wütenden Gebrüll der Menge übertönt. Wie die letzte siebte Welle, die Schiffe zerschmetterte, erhob sich diese letzte unaufhaltsame Welle aus den hinteren Reihen, erreichte die vorderen, warf sie nieder und verschluckte alles. Der zuschlagende Dragoner wollte seinen Schlag wiederholen. Wereschtschagin stürzte mit einem Schreckensschrei, der sich mit den Händen schützte, auf das Volk zu. Der große Kerl, mit dem er zusammenstieß, packte Wereschtschagins dünnen Hals mit seinen Händen, und mit einem wilden Schrei fielen er und er vor die Füße der brüllenden Menschenmenge.
Einige schlugen und zerrissen Wereschtschagin, andere waren groß und klein. Und die Schreie der niedergeschlagenen Menschen und derjenigen, die versuchten, den großen Kerl zu retten, erregten nur die Wut der Menge. Lange Zeit konnten die Dragoner den blutüberströmten, halb zu Tode geprügelten Fabrikarbeiter nicht befreien. Und trotz aller fieberhaften Eile, mit der die Menge versuchte, das einmal begonnene Werk zu vollenden, konnten die Leute, die Wereschtschagin schlugen, erwürgten und rissen, ihn lange Zeit nicht töten; aber die Menge bedrängte sie von allen Seiten, mit ihnen in der Mitte, wie eine Masse, schwankte von einer Seite zur anderen und gab ihnen keine Gelegenheit, ihn entweder zu erledigen oder zu werfen.
Standardabweichung
Am meisten perfekte Charakteristik Variation ist die mittlere quadratische Abweichung, die als Standard (oder Standardabweichung) bezeichnet wird. Standardabweichung() ist gleich der Quadratwurzel der durchschnittlichen quadratischen Abweichung einzelner Werte des Attributs vom arithmetischen Mittel:
Die Standardabweichung ist einfach:


Auf gruppierte Daten wird eine gewichtete Standardabweichung angewendet:

Unter Normalverteilungsbedingungen ergibt sich folgendes Verhältnis zwischen mittlerer quadratischer und mittlerer linearer Abweichung: ~ 1,25.
Die Standardabweichung ist das wichtigste absolute Maß für die Variation und wird bei der Bestimmung der Ordinatenwerte einer Normalverteilungskurve, bei Berechnungen im Zusammenhang mit der Organisation der Probenbeobachtung und der Feststellung der Genauigkeit von Probenmerkmalen sowie bei der Beurteilung der verwendet Grenzen der Variation eines Merkmals in einer homogenen Population.
18. Varianz, ihre Typen, Standardabweichung.
Varianz einer Zufallsvariablen- ein Maß für die Streuung einer bestimmten Zufallsvariablen, d. h. ihre Abweichung von der mathematischen Erwartung. In der Statistik wird häufig die Notation oder verwendet. Quadratwurzel aus der Varianz wird üblicherweise aufgerufen Standardabweichung, Standardabweichung oder Standardaufstrich.
Gesamtvarianz (σ 2) misst die Variation eines Merkmals in seiner Gesamtheit unter dem Einfluss aller Faktoren, die diese Variation verursacht haben. Gleichzeitig ist es dank der Gruppierungsmethode möglich, die Variation aufgrund des Gruppierungsmerkmals und die Variation, die unter dem Einfluss nicht berücksichtigter Faktoren entsteht, zu identifizieren und zu messen.
Intergruppenvarianz (σ 2 m.gr) charakterisiert systematische Variation, d.h. Unterschiede im Wert des untersuchten Merkmals, die unter dem Einfluss des Merkmals entstehen – dem Faktor, der die Grundlage der Gruppe bildet.
Standardabweichung(Synonyme: Standardabweichung, Standardabweichung, quadratische Abweichung; verwandte Begriffe: Standardabweichung, Standardaufstrich) – in der Wahrscheinlichkeitstheorie und Statistik der häufigste Indikator für die Streuung der Werte einer Zufallsvariablen relativ zu ihrer mathematischen Erwartung. Bei begrenzten Arrays von Stichprobenwerten wird anstelle des mathematischen Erwartungswerts das arithmetische Mittel der Stichprobenmenge verwendet.
Die Standardabweichung wird in Maßeinheiten der Zufallsvariablen selbst gemessen und bei der Berechnung des Standardfehlers des arithmetischen Mittels, bei der Konstruktion von Konfidenzintervallen, bei der statistischen Prüfung von Hypothesen und bei der Messung der linearen Beziehung zwischen Zufallsvariablen verwendet. Definiert als Quadratwurzel der Varianz einer Zufallsvariablen.
Standardabweichung:

Standardabweichung(Schätzung der Standardabweichung einer Zufallsvariablen X relativ zu seiner mathematischen Erwartung basierend auf einer unvoreingenommenen Schätzung seiner Varianz):

wo ist die Streuung; - ich tes Element der Auswahl; - Stichprobengröße; - Arithmetisches Mittel der Stichprobe:
![]()
Es ist zu beachten, dass beide Schätzungen verzerrt sind. Im Allgemeinen ist es unmöglich, eine unvoreingenommene Schätzung zu erstellen. In diesem Fall ist die auf der unverzerrten Varianzschätzung basierende Schätzung konsistent.
19. Wesen, Umfang und Verfahren zur Bestimmung von Modus und Median.
Zusätzlich zu Leistungsdurchschnitten in der Statistik für die relativen Merkmale des Wertes eines variierenden Merkmals und Interne Struktur Verteilungsreihen verwenden strukturelle Mittel, die hauptsächlich durch dargestellt werden Mode und Median.
Mode- Dies ist die häufigste Variante der Serie. Mode wird beispielsweise bei der Bestimmung der Größe von Kleidungsstücken und Schuhen verwendet, die bei den Kunden am stärksten nachgefragt werden. Der Modus für eine diskrete Reihe ist die Variante mit der höchsten Frequenz. Bei der Berechnung des Modus für eine Intervallvariationsreihe ist es äußerst wichtig, zuerst das Modalintervall (nach maximaler Häufigkeit) und dann den Wert des Modalwerts des Attributs mithilfe der Formel zu bestimmen:

§ - Bedeutung von Mode
§ - untere Grenze des Modalintervalls
§ - Intervallwert
§ - modale Intervallfrequenz
§ - Häufigkeit des Intervalls vor dem Modal
§ - Häufigkeit des Intervalls nach dem Modal
Median - Dieser Wert des Attributs ĸᴏᴛᴏᴩᴏᴇ liegt der Rangreihe zugrunde und teilt diese Reihe in zwei gleich große Teile.
Um den Median zu bestimmen in einer diskreten Reihe Wenn Frequenzen verfügbar sind, berechnen Sie zunächst die Halbsumme der Häufigkeiten und bestimmen Sie dann, welcher Wert der Variante darauf fällt. (Wenn die sortierte Serie enthält ungerade Zahl Merkmale, dann wird der Medianwert nach folgender Formel berechnet:
M e = (n (Anzahl der Features insgesamt) + 1)/2,
Bei einer geraden Anzahl von Merkmalen entspricht der Median dem Durchschnitt der beiden Merkmale in der Mitte der Zeile.
Bei der Berechnung des Medians für Intervallvariationsreihen Bestimmen Sie zunächst das Medianintervall, in dem der Median liegt, und bestimmen Sie dann den Wert des Medians mithilfe der Formel:

§ – der erforderliche Median
§ – untere Grenze des Intervalls, das den Median enthält
§ - Intervallwert
§ – Summe der Häufigkeiten oder Anzahl der Reihenglieder
§ – die Summe der akkumulierten Häufigkeiten der Intervalle vor dem Median
§ - Häufigkeit des Medianintervalls
Beispiel. Finden Sie den Modus und den Median.
Lösung: In diesem Beispiel liegt das Modalintervall in der Altersgruppe von 25–30 Jahren, da dieses Intervall die höchste Häufigkeit aufweist (1054).
Berechnen wir die Größe des Modus:
Das bedeutet, dass das Modalalter der Studierenden 27 Jahre beträgt.
Berechnen wir den Median. Das mittlere Intervall liegt in der Altersgruppe von 25–30 Jahren, da es innerhalb dieses Intervalls eine Option gibt, die die Bevölkerung in zwei gleiche Teile teilt (Σf i /2 = 3462/2 = 1731). Als nächstes setzen wir die notwendigen numerischen Daten in die Formel ein und erhalten den Medianwert:

Das bedeutet, dass die Hälfte der Studierenden unter 27,4 Jahre alt ist, die andere Hälfte über 27,4 Jahre.
Zusätzlich zu Modus und Median werden Indikatoren wie Quartile verwendet, die die Rangreihe in 4 gleiche Teile unterteilen, Dezile – 10 Teile und Perzentile – in 100 Teile.
20. Das Konzept der Probenbeobachtung und sein Umfang.
Selektive Beobachtung gilt beim Einsatz einer kontinuierlichen Überwachung physikalisch unmöglich aufgrund einer großen Datenmenge bzw wirtschaftlich nicht machbar. Physische Unmöglichkeit tritt beispielsweise bei der Untersuchung von Passagierströmen, Marktpreisen und Familienbudgets auf. Wirtschaftliche Unzweckmäßigkeit entsteht bei der Beurteilung der Qualität von Gütern im Zusammenhang mit deren Zerstörung, z. B. Verkostung, Festigkeitsprüfung von Ziegeln usw.
Die für die Beobachtung ausgewählten statistischen Einheiten sind Stichprobenpopulation oder Probe, und ihr gesamtes Array - Durchschnittsbevölkerung(GS). Dabei Anzahl der Einheiten in der Stichprobe bezeichnen N, und im gesamten GS - N. Attitüde n/N normalerweise aufgerufen relative Größe oder Beispielfreigabe.
Die Qualität der Ergebnisse der Probenbeobachtung hängt davon ab Repräsentativität der Stichprobe, also wie repräsentativ es im GS ist. Um die Repräsentativität der Stichprobe sicherzustellen, ist die Einhaltung äußerst wichtig Prinzip der zufälligen Auswahl von Einheiten, die davon ausgeht, dass die Aufnahme einer HS-Einheit in die Probe durch keinen anderen Faktor als den Zufall beeinflusst werden kann.
Existiert 4 Möglichkeiten der Zufallsauswahl zum Probieren:
- Eigentlich zufällig Auswahl oder „Lotto-Methode“, wenn statistische Werte zugewiesen werden Seriennummer, auf bestimmte Gegenstände (z. B. Fässer) gelegt, die dann in einem Behälter (z. B. in einer Tüte) gemischt und zufällig ausgewählt werden. In der Praxis wird diese Methode mit einem Zufallszahlengenerator oder mathematischen Zufallszahlentabellen durchgeführt.
- Mechanisch Auswahl, nach der jeweils ( N/n)-te Menge Bevölkerung. Wenn es beispielsweise 100.000 Werte enthält und Sie 1.000 auswählen müssen, werden alle 100.000 / 1000 = 100. Wert in die Stichprobe einbezogen. Wenn sie darüber hinaus nicht in einer Rangfolge stehen, wird der erste zufällig aus den ersten hundert ausgewählt, und die Nummern der anderen werden um einhundert höher sein. Wenn die erste Einheit beispielsweise Nr. 19 war, sollte die nächste Nr. 119, dann Nr. 219, dann Nr. 319 usw. sein. Bei einer Rangfolge der Bevölkerungseinheiten wird zuerst Nr. 50 ausgewählt, dann Nr. 150, dann Nr. 250 und so weiter.
- Es erfolgt eine Auswahl von Werten aus einem heterogenen Datenarray geschichtet(geschichtete) Methode, bei der die Bevölkerung zunächst in homogene Gruppen aufgeteilt wird, auf die eine zufällige oder mechanische Auswahl angewendet wird.
- Spezieller Weg Probenahme ist seriell Auswahl, bei der sie nicht einzelne Werte zufällig oder mechanisch auswählen, sondern deren Reihen (Sequenzen von einer Zahl zu einer bestimmten Zahl in Folge), innerhalb derer eine kontinuierliche Beobachtung durchgeführt wird.
Die Qualität der Stichprobenbeobachtungen hängt auch davon ab Beispielstyp: wiederholt oder unwiederholbar. Bei Neuauswahl In die Stichprobe einbezogene statistische Werte oder deren Reihen werden nach der Verwendung an die Allgemeinbevölkerung zurückgegeben und haben die Möglichkeit, in eine neue Stichprobe aufgenommen zu werden. Darüber hinaus haben alle Werte in der Gesamtbevölkerung die gleiche Wahrscheinlichkeit, in die Stichprobe aufgenommen zu werden. Wiederhollose Auswahl bedeutet, dass die in die Stichprobe einbezogenen statistischen Werte oder deren Reihen nach der Verwendung nicht in die Allgemeinbevölkerung zurückkehren und daher für deren verbleibende Werte die Wahrscheinlichkeit steigt, in die nächste Stichprobe aufgenommen zu werden.
Die nicht wiederholte Probenahme liefert genauere Ergebnisse und wird daher häufiger verwendet. Es gibt jedoch Situationen, in denen es nicht angewendet werden kann (Untersuchung von Passagierströmen, Verbrauchernachfrage usw.) und dann eine erneute Auswahl durchgeführt wird.
21. Maximaler Beobachtungs-Stichprobenfehler, durchschnittlicher Stichprobenfehler, Verfahren zu ihrer Berechnung.
Betrachten wir die oben aufgeführten Bildungsmethoden im Detail Stichprobenpopulation und die daraus resultierenden Fehler der Repräsentativität. Richtig zufällig Die Stichprobenziehung basiert auf der zufälligen Auswahl von Einheiten aus der Grundgesamtheit ohne systematische Elemente. Technisch gesehen erfolgt die eigentliche Zufallsauswahl durch Auslosung (z. B. Lotterien) oder anhand einer Zufallszahlentabelle.
Die richtige Zufallsauswahl „in ihrer reinen Form“ wird in der Praxis der selektiven Beobachtung selten verwendet, ist aber die erste unter anderen Arten der Auswahl; sie setzt die Grundprinzipien der selektiven Beobachtung um. Betrachten wir einige theoretische Fragen Probenahmeverfahren und Fehlerformeln für einfache Zufallsstichproben.
Stichprobenverzerrung- ϶ᴛᴏ die Differenz zwischen dem Wert des Parameters in der Allgemeinbevölkerung und seinem aus den Ergebnissen der Stichprobenbeobachtung berechneten Wert. Es ist wichtig zu beachten, dass für das durchschnittliche quantitative Merkmal der Stichprobenfehler bestimmt wird durch
Der Indikator wird üblicherweise als maximaler Stichprobenfehler bezeichnet. Der Stichprobenmittelwert ist eine Zufallsvariable, die annehmen kann unterschiedliche Bedeutungen basierend darauf, welche Einheiten in die Stichprobe einbezogen wurden. Daher sind Stichprobenfehler ebenfalls Zufallsvariablen und können unterschiedliche Werte annehmen. Bestimmen Sie daher den Durchschnitt von mögliche Fehler – durchschnittlicher Stichprobenfehler, was abhängt von:
· Stichprobengröße: Je größer die Zahl, desto kleiner der durchschnittliche Fehler;
· der Grad der Änderung des untersuchten Merkmals: Je kleiner die Variation des Merkmals und damit die Streuung, desto kleiner ist der durchschnittliche Stichprobenfehler.
Bei zufällige Neuauswahl der durchschnittliche Fehler wird berechnet. In der Praxis ist die allgemeine Varianz nicht genau bekannt, aber in der Wahrscheinlichkeitstheorie wurde dies nachgewiesen ![]() . Da der Wert für ausreichend großes n nahe bei 1 liegt, können wir davon ausgehen. Dann sollte der durchschnittliche Stichprobenfehler berechnet werden: . Aber in Fällen einer kleinen Stichprobe (mit n<30) коэффициент крайне важно учитывать, и среднюю ошибку малой выборки рассчитывать по формуле
. Da der Wert für ausreichend großes n nahe bei 1 liegt, können wir davon ausgehen. Dann sollte der durchschnittliche Stichprobenfehler berechnet werden: . Aber in Fällen einer kleinen Stichprobe (mit n<30) коэффициент крайне важно учитывать, и среднюю ошибку малой выборки рассчитывать по формуле  .
.
Bei zufällige, sich nicht wiederholende Stichprobe Die angegebenen Formeln werden um den Wert angepasst. Dann beträgt der durchschnittliche nicht wiederkehrende Stichprobenfehler:  Und
Und  . Weil ist immer kleiner als , dann ist der Multiplikator () immer kleiner als 1. Das bedeutet, dass der durchschnittliche Fehler bei wiederholter Auswahl immer kleiner ist als bei wiederholter Auswahl. Mechanische Probenahme wird verwendet, wenn die allgemeine Bevölkerung in irgendeiner Weise geordnet ist (z. B. Wählerlisten in alphabetischer Reihenfolge, Telefonnummern, Haus- und Wohnungsnummern). Die Auswahl der Einheiten erfolgt in einem bestimmten Intervall, das dem Kehrwert des Stichprobenprozentsatzes entspricht. Bei einer 2 %-Stichprobe werden also alle 50 Einheiten = 1/0,02 ausgewählt, bei einer 5 %-Stichprobe werden alle 1/0,05 = 20 Einheiten der Gesamtbevölkerung ausgewählt.
. Weil ist immer kleiner als , dann ist der Multiplikator () immer kleiner als 1. Das bedeutet, dass der durchschnittliche Fehler bei wiederholter Auswahl immer kleiner ist als bei wiederholter Auswahl. Mechanische Probenahme wird verwendet, wenn die allgemeine Bevölkerung in irgendeiner Weise geordnet ist (z. B. Wählerlisten in alphabetischer Reihenfolge, Telefonnummern, Haus- und Wohnungsnummern). Die Auswahl der Einheiten erfolgt in einem bestimmten Intervall, das dem Kehrwert des Stichprobenprozentsatzes entspricht. Bei einer 2 %-Stichprobe werden also alle 50 Einheiten = 1/0,02 ausgewählt, bei einer 5 %-Stichprobe werden alle 1/0,05 = 20 Einheiten der Gesamtbevölkerung ausgewählt.
Der Bezugspunkt wird auf unterschiedliche Weise ausgewählt: zufällig, aus der Mitte des Intervalls, mit Änderung des Bezugspunkts. Es geht vor allem darum, systematische Fehler zu vermeiden. Wenn beispielsweise bei einer Stichprobe von 5 % die erste Einheit die 13. ist, sind die nächsten 33, 53, 73 usw.
Hinsichtlich der Genauigkeit kommt die mechanische Auswahl der tatsächlichen Zufallsauswahl nahe. Aus diesem Grund werden zur Bestimmung des durchschnittlichen Fehlers der mechanischen Probenahme geeignete Zufallsauswahlformeln verwendet.
Bei typische Auswahl Die befragte Bevölkerung wird vorab in homogene, ähnliche Gruppen eingeteilt. Bei der Befragung von Unternehmen sind dies beispielsweise Branchen, Teilsektoren, bei der Untersuchung der Bevölkerung sind dies Regionen, soziale oder Altersgruppen. Anschließend erfolgt mechanisch oder rein zufällig eine unabhängige Auswahl aus jeder Gruppe.
Typische Probenahmen liefern genauere Ergebnisse als andere Methoden. Durch die Typisierung der Allgemeinbevölkerung wird sichergestellt, dass jede typologische Gruppe in der Stichprobe vertreten ist, wodurch der Einfluss der Intergruppenvarianz auf den durchschnittlichen Stichprobenfehler eliminiert werden kann. Daher ist es bei der Ermittlung des Fehlers einer typischen Stichprobe gemäß der Varianzadditionsregel () äußerst wichtig, nur den Durchschnitt der Gruppenvarianzen zu berücksichtigen. Dann der durchschnittliche Stichprobenfehler: bei wiederholter Stichprobe, bei nicht wiederholter Stichprobe  , Wo
, Wo  – der Durchschnitt der gruppeninternen Varianzen in der Stichprobe.
– der Durchschnitt der gruppeninternen Varianzen in der Stichprobe.
Serielle (oder verschachtelte) Auswahl Wird verwendet, wenn die Grundgesamtheit vor Beginn der Stichprobenerhebung in Reihen oder Gruppen unterteilt wird. Diese Serien umfassen Verpackungen von Fertigprodukten, Studentengruppen und Brigaden. Die zu untersuchenden Serien werden mechanisch oder rein zufällig ausgewählt und innerhalb der Serie wird eine kontinuierliche Prüfung der Einheiten durchgeführt. Aus diesem Grund hängt der durchschnittliche Stichprobenfehler nur von der Intergruppenvarianz (zwischen Reihen) ab, die mit der Formel berechnet wird:  wobei r die Anzahl der ausgewählten Serien ist; – Durchschnitt der i-ten Serie. Der durchschnittliche Fehler der seriellen Probenahme wird berechnet: bei wiederholter Probenahme, bei nicht wiederholter Probenahme
wobei r die Anzahl der ausgewählten Serien ist; – Durchschnitt der i-ten Serie. Der durchschnittliche Fehler der seriellen Probenahme wird berechnet: bei wiederholter Probenahme, bei nicht wiederholter Probenahme  , wobei R die Gesamtzahl der Serien ist. Kombiniert Auswahl ist eine Kombination der betrachteten Auswahlmethoden.
, wobei R die Gesamtzahl der Serien ist. Kombiniert Auswahl ist eine Kombination der betrachteten Auswahlmethoden.
Der durchschnittliche Stichprobenfehler für jede Stichprobenmethode hängt hauptsächlich von der absoluten Größe der Stichprobe und in geringerem Maße vom Prozentsatz der Stichprobe ab. Nehmen wir an, dass im ersten Fall 225 Beobachtungen aus einer Population von 4.500 Einheiten und im zweiten Fall aus einer Population von 225.000 Einheiten gemacht werden. Die Varianzen betragen in beiden Fällen 25. Im ersten Fall beträgt der Stichprobenfehler bei einer Auswahl von 5 %:  Im zweiten Fall beträgt die Auswahl bei 0,1 %:
Im zweiten Fall beträgt die Auswahl bei 0,1 %:
 Wenn der Stichprobenprozentsatz jedoch um das Fünfzigfache reduziert wurde, erhöhte sich der Stichprobenfehler leicht, da sich die Stichprobengröße nicht änderte. Nehmen wir an, dass die Stichprobengröße auf 625 Beobachtungen erhöht wird. In diesem Fall beträgt der Stichprobenfehler:
Wenn der Stichprobenprozentsatz jedoch um das Fünfzigfache reduziert wurde, erhöhte sich der Stichprobenfehler leicht, da sich die Stichprobengröße nicht änderte. Nehmen wir an, dass die Stichprobengröße auf 625 Beobachtungen erhöht wird. In diesem Fall beträgt der Stichprobenfehler:  Eine Vergrößerung der Stichprobe um das 2,8-fache bei gleicher Grundgesamtheit verringert die Größe des Stichprobenfehlers um mehr als das 1,6-fache.
Eine Vergrößerung der Stichprobe um das 2,8-fache bei gleicher Grundgesamtheit verringert die Größe des Stichprobenfehlers um mehr als das 1,6-fache.
22.Methoden und Methoden zur Bildung einer Stichprobenpopulation.
In der Statistik kommen unterschiedliche Methoden zur Bildung von Stichprobenpopulationen zum Einsatz, die sich nach den Zielen der Untersuchung richten und von den Besonderheiten des Untersuchungsgegenstandes abhängen.
Die Hauptvoraussetzung für die Durchführung einer Stichprobenerhebung besteht darin, das Auftreten systematischer Fehler aufgrund einer Verletzung des Grundsatzes der Chancengleichheit für jede in die Stichprobe einzubeziehende Einheit der Gesamtbevölkerung zu verhindern. Die Vermeidung systematischer Fehler wird durch den Einsatz wissenschaftlich fundierter Methoden zur Bildung einer Stichprobenpopulation erreicht.
Es gibt die folgenden Methoden zur Auswahl von Einheiten aus der Gesamtbevölkerung: 1) Einzelauswahl – einzelne Einheiten werden für die Stichprobe ausgewählt; 2) Gruppenauswahl – die Stichprobe umfasst qualitativ homogene Gruppen oder Reihen von untersuchten Einheiten; 3) Die kombinierte Auswahl ist eine Kombination aus Einzel- und Gruppenauswahl. Auswahlmethoden werden durch die Regeln zur Bildung einer Stichprobenpopulation bestimmt.
Die Probe sollte sein:
- eigentlich zufällig besteht darin, dass die Stichprobenpopulation durch zufällige (unbeabsichtigte) Auswahl einzelner Einheiten aus der Gesamtbevölkerung gebildet wird. In diesem Fall wird die Anzahl der in der Stichprobenpopulation ausgewählten Einheiten normalerweise auf der Grundlage des akzeptierten Stichprobenanteils bestimmt. Der Stichprobenanteil ist das Verhältnis der Anzahl der Einheiten in der Stichprobenpopulation n zur Anzahl der Einheiten in der Gesamtbevölkerung N, ᴛ.ᴇ.
- mechanisch besteht darin, dass die Auswahl der Einheiten in der Stichprobenpopulation aus der Gesamtbevölkerung erfolgt, aufgeteilt in gleiche Intervalle (Gruppen). In diesem Fall entspricht die Größe des Intervalls in der Grundgesamtheit dem Kehrwert des Stichprobenanteils. Bei einer Stichprobe von 2 % wird also jede 50. Einheit ausgewählt (1:0,02), bei einer Stichprobe von 5 % jede 20. Einheit (1:0,05) usw. Allerdings wird die Gesamtbevölkerung entsprechend dem akzeptierten Selektionsverhältnis gleichsam mechanisch in gleiche Gruppen eingeteilt. Aus jeder Gruppe wird nur eine Einheit für die Stichprobe ausgewählt.
- typisch – bei dem die Gesamtbevölkerung zunächst in homogene typische Gruppen eingeteilt wird. Anschließend wird aus jeder typischen Gruppe eine rein zufällige oder mechanische Stichprobe verwendet, um einzelne Einheiten für die Stichprobenpopulation auszuwählen. Ein wichtiges Merkmal einer typischen Stichprobe besteht darin, dass sie im Vergleich zu anderen Methoden zur Auswahl von Einheiten in der Stichprobenpopulation genauere Ergebnisse liefert.
- seriell- bei dem die Gesamtbevölkerung in gleich große Gruppen eingeteilt wird - Reihen. Reihen werden in die Stichprobenpopulation ausgewählt. Innerhalb der Serie erfolgt eine kontinuierliche Beobachtung der in der Serie enthaltenen Einheiten;
- kombiniert- Die Probenahme sollte zweistufig erfolgen. Dabei wird die Bevölkerung zunächst in Gruppen eingeteilt. Als nächstes werden Gruppen ausgewählt und innerhalb dieser werden einzelne Einheiten ausgewählt.
In der Statistik werden folgende Methoden zur Auswahl von Einheiten in einer Stichprobenpopulation unterschieden:
- einstufig Probenahme – jede ausgewählte Einheit wird sofort einer Untersuchung nach einem bestimmten Kriterium unterzogen (richtige Zufalls- und Reihenstichprobe);
- mehrstufig Stichprobenziehung – eine Auswahl wird aus der allgemeinen Grundgesamtheit einzelner Gruppen getroffen, und einzelne Einheiten werden aus den Gruppen ausgewählt (typische Stichprobenziehung mit einer mechanischen Methode zur Auswahl von Einheiten in die Stichprobenpopulation).
Darüber hinaus gibt es:
- Neuauswahl- nach dem Schema des zurückgegebenen Balls. In diesem Fall wird jede in die Stichprobe einbezogene Einheit oder Serie an die allgemeine Grundgesamtheit zurückgegeben und hat daher die Chance, erneut in die Stichprobe aufgenommen zu werden.
- Auswahl wiederholen- nach dem nicht zurückgegebenen Ballschema. Es liefert genauere Ergebnisse bei gleicher Stichprobengröße.
23. Bestimmung der äußerst wichtigen Stichprobengröße (unter Verwendung der Student-T-Tabelle).
Eines der wissenschaftlichen Prinzipien der Stichprobentheorie besteht darin, sicherzustellen, dass eine ausreichende Anzahl von Einheiten ausgewählt wird. Theoretisch wird die außerordentliche Bedeutung der Einhaltung dieses Prinzips in den Beweisen von Grenzwertsätzen in der Wahrscheinlichkeitstheorie dargestellt, die es ermöglichen, festzulegen, welches Volumen an Einheiten aus der Grundgesamtheit ausgewählt werden sollte, damit es ausreichend ist und die Repräsentativität der Stichprobe gewährleistet.
Eine Verringerung des Standardstichprobenfehlers und damit eine Erhöhung der Genauigkeit der Schätzung ist immer mit einer Vergrößerung der Stichprobengröße verbunden; daher muss bereits in der Phase der Organisation einer Stichprobenbeobachtung entschieden werden, wie groß die Stichprobe sein soll der Stichprobenpopulation sollte sein, um die erforderliche Genauigkeit der Beobachtungsergebnisse sicherzustellen. Die Berechnung des äußerst wichtigen Probenvolumens erfolgt anhand von Formeln, die aus den Formeln für die maximalen Probenahmefehler (A) abgeleitet sind, die einer bestimmten Art und Methode der Auswahl entsprechen. Für eine zufällig wiederholte Stichprobengröße (n) gilt also:

Der Kern dieser Formel besteht darin, dass bei zufällig wiederholten Stichproben extrem wichtiger Zahlen die Stichprobengröße direkt proportional zum Quadrat des Konfidenzkoeffizienten ist (t2) und Varianz der Variationscharakteristik (?2) und ist umgekehrt proportional zum Quadrat des maximalen Stichprobenfehlers (?2). Insbesondere sollte bei einer Erhöhung des maximalen Fehlers um den Faktor zwei die erforderliche Stichprobengröße um den Faktor vier reduziert werden. Von den drei Parametern werden zwei (t und?) vom Forscher festgelegt. Gleichzeitig orientiert sich der Forscher am Ziel
und die Probleme einer Stichprobenerhebung müssen die Frage lösen: In welcher quantitativen Kombination ist es besser, diese Parameter einzubeziehen, um die optimale Option sicherzustellen? In einem Fall ist er möglicherweise mit der Zuverlässigkeit der erhaltenen Ergebnisse (t) zufriedener als mit dem Genauigkeitsmaß (?), in einem anderen Fall – umgekehrt. Schwieriger ist es, die Frage nach dem Wert des maximalen Stichprobenfehlers zu lösen, da der Forscher in der Phase der Planung der Stichprobenbeobachtung nicht über diesen Indikator verfügt; daher ist es in der Praxis üblich, den Wert des maximalen Stichprobenfehlers festzulegen , normalerweise innerhalb von 10 % des erwarteten Durchschnittsniveaus des Attributs. Die Ermittlung des geschätzten Durchschnitts kann auf unterschiedliche Weise erfolgen: unter Verwendung von Daten aus ähnlichen früheren Erhebungen oder unter Verwendung von Daten aus dem Stichprobenrahmen und Durchführung einer kleinen Pilotstichprobe.
Beim Entwurf einer Stichprobenbeobachtung ist es am schwierigsten, den dritten Parameter in Formel (5.2) festzulegen – die Varianz der Stichprobenpopulation. In diesem Fall ist es äußerst wichtig, alle dem Forscher zur Verfügung stehenden Informationen zu nutzen, die er in früheren ähnlichen Umfragen und Pilotumfragen erhalten hat.
Die Frage der Bestimmung des äußerst wichtigen Stichprobenumfangs wird komplizierter, wenn bei der Stichprobenerhebung mehrere Merkmale von Stichprobeneinheiten untersucht werden. In diesem Fall sind die durchschnittlichen Werte der einzelnen Merkmale und ihre Variation in der Regel unterschiedlich, und in dieser Hinsicht ist die Entscheidung, welcher Varianz welcher Merkmale der Vorzug gegeben werden soll, nur unter Berücksichtigung des Zwecks und der Ziele möglich der Umfrage.
Bei der Gestaltung einer Stichprobenbeobachtung wird ein vorgegebener Wert des zulässigen Stichprobenfehlers entsprechend den Zielen einer bestimmten Studie und der Wahrscheinlichkeit von Schlussfolgerungen aus den Beobachtungsergebnissen angenommen.
Im Allgemeinen können wir mit der Formel für den maximalen Fehler des Stichprobenmittelwerts Folgendes bestimmen:
‣‣‣ das Ausmaß möglicher Abweichungen der Indikatoren der Gesamtbevölkerung von den Indikatoren der Stichprobenpopulation;
‣‣‣ die erforderliche Stichprobengröße zur Gewährleistung der erforderlichen Genauigkeit, bei der die Grenzen möglicher Fehler einen bestimmten festgelegten Wert nicht überschreiten;
‣‣‣ die Wahrscheinlichkeit, dass der Fehler in der Stichprobe eine bestimmte Grenze hat.
Studentenverteilung In der Wahrscheinlichkeitstheorie handelt es sich um eine Ein-Parameter-Familie absolut stetiger Verteilungen.
24. Dynamische Reihe (Intervall, Moment), abschließende dynamische Reihe.
Dynamics-Reihe- Dies sind die Werte statistischer Indikatoren, die in einer bestimmten chronologischen Reihenfolge dargestellt werden.
Jede Zeitreihe enthält zwei Komponenten:
1) Indikatoren für Zeiträume(Jahre, Quartale, Monate, Tage oder Daten);
2) Indikatoren, die das untersuchte Objekt charakterisieren für Zeiträume bzw. zu entsprechenden Terminen, die aufgerufen werden Serienebenen.
Reihenniveaus werden sowohl in absoluten als auch in durchschnittlichen oder relativen Werten ausgedrückt. Unter Berücksichtigung der Abhängigkeit von der Art der Indikatoren werden dynamische Reihen von Absolut-, Relativ- und Durchschnittswerten erstellt. Dynamische Reihen von Relativ- und Durchschnittswerten werden auf der Grundlage abgeleiteter Reihen von Absolutwerten erstellt. Es gibt Intervall- und Momentreihen der Dynamik.
Dynamische Intervallreihe enthält die Werte von Indikatoren für bestimmte Zeiträume. In einer Intervallreihe können Pegel aufsummiert werden, um das Volumen des Phänomens über einen längeren Zeitraum zu erhalten, die sogenannten akkumulierten Summen.
Dynamische Momentreihe spiegelt die Werte von Indikatoren zu einem bestimmten Zeitpunkt (Datum) wider. Bei Momentreihen ist der Forscher möglicherweise nur an der Differenz der Phänomene interessiert, die die Änderung des Niveaus der Reihe zwischen bestimmten Daten widerspiegelt, da die Summe der Niveaus hier keinen wirklichen Inhalt hat. Kumulierte Summen werden hier nicht berechnet.
Die wichtigste Voraussetzung für die korrekte Konstruktion von Zeitreihen ist Vergleichbarkeit von Serienniveaus verschiedenen Epochen angehören. Die Ebenen müssen in homogenen Mengen dargestellt werden und die Abdeckung verschiedener Teile des Phänomens muss gleichermaßen vollständig sein.
Um eine Verzerrung der realen Dynamik zu vermeiden, werden in der statistischen Forschung Vorrechnungen (Abschluss der Dynamikreihe) durchgeführt, die der statistischen Analyse der Zeitreihe vorausgehen. Unter Abschluss der Dynamikreihe Es ist allgemein anerkannt, die Kombination von zwei oder mehr Reihen zu einer Reihe zu verstehen, deren Niveaus nach unterschiedlichen Methoden berechnet werden oder nicht den territorialen Grenzen usw. entsprechen. Das Schließen der Dynamikreihe kann auch bedeuten, dass die absoluten Niveaus der Dynamikreihe auf eine gemeinsame Basis gebracht werden, was die Unvergleichbarkeit der Niveaus der Dynamikreihe neutralisiert.
25. Das Konzept der Vergleichbarkeit von Dynamikreihen, Koeffizienten, Wachstum und Wachstumsraten.
Dynamics-Reihe- Hierbei handelt es sich um eine Reihe statistischer Indikatoren, die die Entwicklung natürlicher und sozialer Phänomene im Laufe der Zeit charakterisieren. Die vom Staatlichen Statistikausschuss Russlands veröffentlichten statistischen Sammlungen enthalten eine große Anzahl dynamischer Reihen in tabellarischer Form. Dynamische Reihen ermöglichen es, Entwicklungsmuster der untersuchten Phänomene zu identifizieren.
Dynamics-Reihen enthalten zwei Arten von Indikatoren. Zeitindikatoren(Jahre, Quartale, Monate usw.) oder Zeitpunkte (am Jahresanfang, am Anfang jedes Monats usw.). Indikatoren auf Zeilenebene. Indikatoren für die Niveaus der Dynamikreihen können in absoluten Werten (Produktproduktion in Tonnen oder Rubel), relativen Werten (Anteil der städtischen Bevölkerung in %) und Durchschnittswerten (durchschnittliches Gehalt der Industriearbeiter pro Jahr) ausgedrückt werden , usw.). In tabellarischer Form enthält eine Zeitreihe zwei Spalten oder zwei Zeilen.
Die korrekte Konstruktion von Zeitreihen erfordert die Erfüllung einer Reihe von Anforderungen:
- alle Indikatoren einer Reihe von Dynamiken müssen wissenschaftlich fundiert und zuverlässig sein;
- Indikatoren einer Reihe von Dynamiken müssen im Zeitverlauf vergleichbar sein, ᴛ.ᴇ. müssen für dieselben Zeiträume oder dieselben Daten berechnet werden;
- Indikatoren für eine Reihe von Dynamiken müssen im gesamten Gebiet vergleichbar sein;
- Indikatoren einer Reihe von Dynamiken müssen inhaltlich vergleichbar sein, ᴛ.ᴇ. nach einer einzigen Methode auf die gleiche Weise berechnet;
- Indikatoren für eine Reihe von Dynamiken sollten für alle berücksichtigten landwirtschaftlichen Betriebe vergleichbar sein. Alle Indikatoren einer Dynamikreihe müssen in den gleichen Maßeinheiten angegeben werden.
Statistische Indikatoren können entweder die Ergebnisse des untersuchten Prozesses über einen bestimmten Zeitraum oder den Zustand des untersuchten Phänomens zu einem bestimmten Zeitpunkt charakterisieren, ᴛ.ᴇ. Indikatoren können intervallartig (periodisch) und kurzzeitig sein. Dementsprechend sind die Dynamikreihen zunächst entweder Intervall- oder Momentreihen. Momentendynamikreihen wiederum haben gleiche und ungleiche Zeitintervalle.
Die ursprüngliche Dynamikreihe kann in eine Reihe von Durchschnittswerten und eine Reihe von Relativwerten (Kette und Basis) umgewandelt werden. Solche Zeitreihen werden abgeleitete Zeitreihen genannt.
Die Methode zur Berechnung des Durchschnittsniveaus in der Dynamikreihe ist je nach Art der Dynamikreihe unterschiedlich. Anhand von Beispielen betrachten wir die Arten von Dynamikreihen und Formeln zur Berechnung des Durchschnittsniveaus.
Absolute Steigerungen (Δy) zeigen, um wie viele Einheiten sich das nachfolgende Niveau der Reihe im Vergleich zum vorherigen (Gr. 3. - Absolute Anstiege der Kette) oder im Vergleich zum Anfangsniveau (Gr. 4. - Absolute Grundzuwächse) geändert hat. Die Berechnungsformeln können wie folgt geschrieben werden:

Wenn die Absolutwerte der Reihe abnehmen, kommt es zu einer „Abnahme“ bzw. „Abnahme“.
Absolute Wachstumsindikatoren deuten darauf hin, beispielsweise im Jahr 1998. Die Produktion von Produkt „A“ stieg im Vergleich zu 1997. um 4 Tausend Tonnen und im Vergleich zu 1994 ᴦ. - um 34 Tausend Tonnen; für andere Jahre siehe Tabelle. 11,5 gr.
Gepostet auf ref.rf
3 und 4.
Wachstumsrate zeigt, wie oft sich das Niveau der Reihe im Vergleich zum vorherigen (Gr. 5 – Kettenwachstums- oder -rückgangskoeffizienten) oder im Vergleich zum Anfangsniveau (Gr. 6 – Grundwachstums- oder -rückgangskoeffizienten) geändert hat. Die Berechnungsformeln können wie folgt geschrieben werden:

Wachstumsraten Zeigen Sie, wie viel Prozent die nächste Stufe der Reihe im Vergleich zur vorherigen (Spalte 7 – Kettenwachstumsraten) oder im Vergleich zur Anfangsstufe (Gr. 8 – Grundwachstumsraten) ist. Die Berechnungsformeln können wie folgt geschrieben werden:

So zum Beispiel im Jahr 1997. Produktionsvolumen von Produkt „A“ im Vergleich zu 1996 ᴦ. betrug 105,5 % (
Wachstumsrate Zeigen Sie, um wie viel Prozent das Niveau des Berichtszeitraums im Vergleich zum vorherigen (Spalte 9 – Kettenwachstumsraten) oder im Vergleich zum Ausgangsniveau (Spalte 10 – Grundwachstumsraten) gestiegen ist. Die Berechnungsformeln können wie folgt geschrieben werden:
T pr = T r - 100 % oder T pr = absolutes Wachstum / Niveau der Vorperiode * 100 %
So zum Beispiel im Jahr 1996. im Vergleich zu 1995 ᴦ. Produkt „A“ wurde im Vergleich zu 1994 um 3,8 % (103,8 % – 100 %) oder (8:210) x 100 % mehr produziert. - um 9 % (109 % – 100 %).
Wenn die absoluten Werte in der Reihe sinken, liegt die Rate unter 100 % und dementsprechend liegt eine Abnahmerate vor (die Anstiegsrate mit einem Minuszeichen).
Absoluter Wert einer Steigerung von 1 %(GR.
Gepostet auf ref.rf
11) zeigt, wie viele Einheiten in einem bestimmten Zeitraum produziert werden müssen, damit das Niveau des Vorzeitraums um 1 % steigt. In unserem Beispiel im Jahr 1995 ᴦ. Es mussten 2,0 Tausend Tonnen produziert werden, und 1998 ᴦ. - 2,3 Tausend Tonnen, ᴛ.ᴇ. viel größer.
Der absolute Wert von 1 % Wachstum kann auf zwei Arten ermittelt werden:
§ das Niveau der vorherigen Periode geteilt durch 100;
§ Die absoluten Kettenzuwächse werden durch die entsprechenden Kettenwachstumsraten dividiert.
Absoluter Wert von 1 % Steigerung = 
In der Dynamik, insbesondere über einen langen Zeitraum, ist eine gemeinsame Analyse der Wachstumsrate mit dem Inhalt jedes prozentualen Anstiegs oder Rückgangs wichtig.
Beachten Sie, dass die betrachtete Methodik zur Analyse von Zeitreihen sowohl für Zeitreihen anwendbar ist, deren Niveaus in absoluten Werten (t, Tausend Rubel, Anzahl der Mitarbeiter usw.) ausgedrückt werden, als auch für Zeitreihen, deren Niveaus werden in relativen Indikatoren (% der Mängel, % Aschegehalt der Kohle usw.) oder Durchschnittswerten (durchschnittlicher Ertrag in c/ha, durchschnittlicher Lohn usw.) ausgedrückt.
Neben den betrachteten analytischen Indikatoren, die für jedes Jahr im Vergleich zum vorherigen oder anfänglichen Niveau berechnet werden, ist es bei der Analyse dynamischer Reihen äußerst wichtig, die durchschnittlichen analytischen Indikatoren für den Zeitraum zu berechnen: das durchschnittliche Niveau der Reihe, den durchschnittlichen Jahresabsolutwert Anstieg (Abnahme) und die durchschnittliche jährliche Wachstumsrate und Wachstumsrate.
Methoden zur Berechnung des durchschnittlichen Niveaus einer Reihe von Dynamiken wurden oben diskutiert. In der von uns betrachteten Intervalldynamikreihe wird das Durchschnittsniveau der Reihe mithilfe der einfachen arithmetischen Mittelformel berechnet:
Durchschnittliches jährliches Produktionsvolumen des Produkts für 1994-1998. belief sich auf 218,4 Tausend Tonnen.
Das durchschnittliche jährliche absolute Wachstum wird ebenfalls mithilfe der arithmetischen Mittelformel berechnet
Standardabweichung – Konzept und Typen. Klassifizierung und Merkmale der Kategorie „Mittlere quadratische Abweichung“ 2017, 2018.
Das Excel-Programm erfreut sich sowohl bei Profis als auch bei Laien großer Beliebtheit, da Anwender aller Erfahrungsstufen damit arbeiten können. Beispielsweise kann jeder mit minimalen „Kommunikations“-Kenntnissen in Excel ein einfaches Diagramm zeichnen, ein anständiges Schild anfertigen usw.
Gleichzeitig ermöglicht Ihnen dieses Programm sogar die Durchführung verschiedener Arten von Berechnungen, beispielsweise Berechnungen, was jedoch einen etwas anderen Schulungsstand erfordert. Wenn Sie jedoch gerade erst begonnen haben, sich mit diesem Programm vertraut zu machen, und sich für alles interessieren, was Ihnen dabei hilft, ein fortgeschrittener Benutzer zu werden, ist dieser Artikel genau das Richtige für Sie. Heute erzähle ich Ihnen, was die Standardabweichungsformel in Excel ist, warum sie überhaupt benötigt wird und genau genommen, wann sie verwendet wird. Gehen!
Was ist das
Beginnen wir mit der Theorie. Die Standardabweichung wird üblicherweise als Quadratwurzel bezeichnet, die aus dem arithmetischen Mittel aller quadrierten Differenzen zwischen den verfügbaren Größen sowie deren arithmetischem Mittel ermittelt wird. Dieser Wert wird übrigens üblicherweise als griechischer Buchstabe „Sigma“ bezeichnet. Die Berechnung der Standardabweichung erfolgt über die Formel STANDARDEVAL; das Programm erledigt dies dementsprechend für den Benutzer selbst.
Der Kern dieses Konzepts besteht darin, den Grad der Variabilität eines Instruments zu ermitteln, das heißt, es ist auf seine Art ein aus der deskriptiven Statistik abgeleiteter Indikator. Es identifiziert Änderungen der Volatilität eines Instruments über einen bestimmten Zeitraum. Die STDEV-Formeln können verwendet werden, um die Standardabweichung einer Stichprobe zu schätzen, wobei boolesche Werte und Textwerte ignoriert werden.
Formel
Die in Excel automatisch bereitgestellte Formel hilft bei der Berechnung der Standardabweichung in Excel. Um es zu finden, müssen Sie den Formelabschnitt in Excel suchen und dann den Abschnitt mit dem Namen STANDARDEVAL auswählen. Das ist also sehr einfach.
Danach erscheint vor Ihnen ein Fenster, in dem Sie Daten für die Berechnung eingeben müssen. Insbesondere sollten zwei Zahlen in spezielle Felder eingegeben werden, woraufhin das Programm selbst die Standardabweichung für die Stichprobe berechnet.

Zweifellos sind mathematische Formeln und Berechnungen ein ziemlich komplexes Thema, mit dem nicht alle Benutzer auf Anhieb zurechtkommen. Wenn man jedoch etwas tiefer geht und sich das Thema genauer ansieht, stellt sich heraus, dass nicht alles so traurig ist. Ich hoffe, Sie können sich davon am Beispiel der Berechnung der Standardabweichung überzeugen.
Video zur Hilfe
$X$. Erinnern wir uns zunächst an die folgende Definition:
Definition 1
Bevölkerung-- eine Menge zufällig ausgewählter Objekte eines bestimmten Typs, an denen Beobachtungen durchgeführt werden, um spezifische Werte einer Zufallsvariablen zu erhalten, die unter konstanten Bedingungen bei der Untersuchung einer Zufallsvariablen eines bestimmten Typs durchgeführt werden.
Definition 2
Allgemeine Varianz– das arithmetische Mittel der quadrierten Abweichungen der Werte der Populationsvariante von ihrem Mittelwert.
Lassen Sie die Werte der Option $x_1,\ x_2,\dots ,x_k$ jeweils Häufigkeiten $n_1,\ n_2,\dots ,n_k$ haben. Anschließend wird die allgemeine Varianz nach folgender Formel berechnet:
Betrachten wir einen Sonderfall. Alle Optionen $x_1,\ x_2,\dots ,x_k$ seien unterschiedlich. In diesem Fall $n_1,\ n_2,\dots ,n_k=1$. Wir stellen fest, dass in diesem Fall die allgemeine Varianz anhand der Formel berechnet wird:
Dieses Konzept ist auch mit dem Konzept der allgemeinen Standardabweichung verbunden.
Definition 3
Allgemeine Standardabweichung
\[(\sigma )_g=\sqrt(D_g)\]
Stichprobenvarianz
Gegeben sei eine Stichprobenpopulation in Bezug auf eine Zufallsvariable $X$. Erinnern wir uns zunächst an die folgende Definition:
Definition 4
Stichprobenpopulation-- Teil ausgewählter Objekte aus der Allgemeinbevölkerung.
Definition 5
Stichprobenvarianz– arithmetisches Mittel der Werte der Stichprobenpopulation.
Lassen Sie die Werte der Option $x_1,\ x_2,\dots ,x_k$ jeweils Häufigkeiten $n_1,\ n_2,\dots ,n_k$ haben. Anschließend wird die Stichprobenvarianz nach folgender Formel berechnet:
Betrachten wir einen Sonderfall. Alle Optionen $x_1,\ x_2,\dots ,x_k$ seien unterschiedlich. In diesem Fall $n_1,\ n_2,\dots ,n_k=1$. Wir stellen fest, dass in diesem Fall die Stichprobenvarianz anhand der Formel berechnet wird:
Mit diesem Konzept ist auch das Konzept der Stichprobenstandardabweichung verbunden.
Definition 6
Standardabweichung der Stichprobe-- Quadratwurzel der allgemeinen Varianz:
\[(\sigma )_в=\sqrt(D_в)\]
Korrigierte Varianz
Um die korrigierte Varianz $S^2$ zu finden, ist es notwendig, die Stichprobenvarianz mit dem Bruch $\frac(n)(n-1)$ zu multiplizieren
Dieses Konzept ist auch mit dem Konzept der korrigierten Standardabweichung verbunden, das durch die Formel ermittelt wird:
Für den Fall, dass die Werte der Varianten nicht diskret sind, sondern Intervalle darstellen, wird in den Formeln zur Berechnung der allgemeinen oder Stichprobenvarianzen der Wert von $x_i$ als Wert der Mitte des Intervalls angenommen zu dem $x_i.$ gehört.
Ein Beispiel für ein Problem zur Ermittlung der Varianz und Standardabweichung
Beispiel 1
Die Stichprobenpopulation wird durch die folgende Verteilungstabelle definiert:
Bild 1.
Lassen Sie uns dafür die Stichprobenvarianz, die Stichprobenstandardabweichung, die korrigierte Varianz und die korrigierte Standardabweichung ermitteln.
Um dieses Problem zu lösen, erstellen wir zunächst eine Berechnungstabelle:
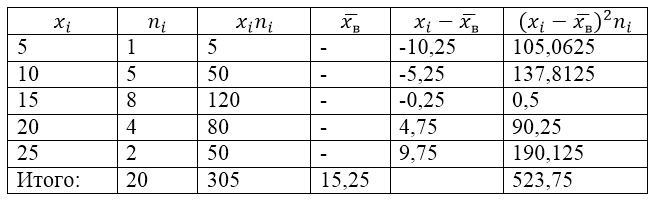
Figur 2.
Der Wert $\overline(x_в)$ (Stichprobendurchschnitt) in der Tabelle wird durch die Formel ermittelt:
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)\]
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)=\frac(305)(20)=15.25\]
Lassen Sie uns die Stichprobenvarianz mithilfe der Formel ermitteln:
Standardabweichung der Stichprobe:
\[(\sigma )_в=\sqrt(D_в)\ungefähr 5,12\]
Korrigierte Varianz:
\[(S^2=\frac(n)(n-1)D)_в=\frac(20)(19)\cdot 26,1875\ungefähr 27,57\]
Korrigierte Standardabweichung.