 入り口
入り口ダミーの母集団とサンプリング。 一般母集団とサンプル母集団。 代表性の概念
講義 6. 要素 数学的統計
知識を管理し、講義を要約するための質問
1. 確率変数を定義します。
2.離散および連続確率変数の数学的期待値と分散の式を書きます。
3. ラプラスの局所積分極限定理を定義する
4. 二項分布、超幾何分布、ポアソン分布、一様分布、正規分布を定義する式を記述します。
目標: 数理統計の基本概念を学ぶこと
1. 母集団とサンプル
2. サンプルの統計的分布。 ポリゴン。 棒グラフ .
3. サンプルに基づく一般集団のパラメータの推定
4. 一般的な平均とサンプルの平均。 それらの計算方法。
5. 一般的な差異とサンプルの差異。
6. 知識を管理し、講義を要約するための質問
私たちは、統計データを収集して処理するための科学に基づいた方法を開発する数理統計の要素の研究を開始します。
1. 一般集団とサンプル。同種のオブジェクトのセットを研究する必要があるとしましょう (このセットは 統計集計)これらのオブジェクトを特徴付ける定性的または定量的な特徴に関するもの。 たとえば、部品のバッチがある場合、部品の標準は定性的な兆候として機能し、部品の制御されたサイズは定量的な兆候として機能します。
完全な検査を実行するのが最善です。 それぞれのオブジェクトを調べます。 ただし、ほとんどの場合、さまざまな理由により、これは実行できません。 完全な検査を妨げる可能性がある 大きな数オブジェクト、そのアクセス不可能性。 たとえば、実験バッチの砲弾が爆発したときのクレーターの平均深さを知る必要がある場合、完全な検査を実行することでバッチ全体を破壊します。
完全な調査が不可能な場合は、調査のために母集団全体からオブジェクトの一部が選択されます。
オブジェクトの一部が選択される統計母集団は、と呼ばれます。 一般の人々。母集団からランダムに選択されたオブジェクトのセットはと呼ばれます サンプリング。
母集団とサンプル内のオブジェクトの数はそれぞれ呼び出されます。 音量一般の人々と 音量サンプル。
例10.1。 1本の木の果実(200個)について、この品種特有の味の有無を検査します。 この目的のために、10 個のピースが選択されます。 ここで、200 は母集団のサイズ、10 はサンプルのサイズです。
1 つのオブジェクトからサンプルが選択され、それが検査されて母集団に戻される場合、そのサンプルは と呼ばれます。 繰り返した。サンプルオブジェクトが母集団に戻されなくなった場合、サンプルは呼び出されます。 再現可能。
実際には、非反復サンプリングがより頻繁に使用されます。 サンプルサイズが母集団サイズのごく一部である場合、反復サンプルと非反復サンプルの差は無視できます。
サンプル内のオブジェクトのプロパティは、母集団内のオブジェクトのプロパティを正確に反映している必要があります。あるいは、よく言われるように、サンプルは次のとおりである必要があります。 代表(代表)。 母集団内のすべてのオブジェクトがサンプルに含まれる確率が同じである場合、つまり選択がランダムに行われる場合、サンプルは代表的であるとみなされます。 たとえば、将来の収穫量を予測するために、まだ熟していない果物の一般集団からサンプルを作成し、その特性 (重量、品質など) を調べることができます。 サンプル全体が 1 本の木から採取された場合、それは代表的なものにはなりません。 代表的なサンプルは、ランダムに選択された木からランダムに選択された果物で構成される必要があります。
2. サンプルの統計的分布。 ポリゴン。 棒グラフ。一般集団からサンプルを抽出するとします。 バツ 1 件が観察されました n 1回、 バツ 2 - n2一度、 ...、 × k - n k回と n 1 +n 2 +…+ ンク= P -サンプルサイズ。 観測値 バツ 1 , バツ 2 , …, Xのk呼ばれた オプション、昇順で書かれたバリアント シーケンスは次のようになります。 バリエーションシリーズ。観測値の数 n 1 , n 2 , …, ンク呼ばれた 周波数、およびサンプルサイズとの関係 , , …, - 相対周波数。相対度数の合計は 1 に等しいことに注意してください。 ![]() .
.
統計的サンプル分布オプションのリストとそれらに対応する頻度または相対頻度を呼び出します。 統計分布は、一連の間隔とそれに対応する頻度 (連続分布) として指定することもできます。 この区間内にあるバリアントの頻度の合計が、その区間に対応する頻度として取得されます。 統計分布をグラフで表示するには、次を使用します。 ポリゴンそして ヒストグラム。
軸上に多角形を構築するには おお値を延期するオプション バツ私は軸上にあります OU -周波数値 P i (相対周波数)。
例10.2。図では、 10.1 は次の分布のポリゴンを示します
 |  |
ポリゴンは通常、オプションの数が少ない場合に使用されます。 多数のバリアントの場合、および属性の連続分布の場合、ヒストグラムが作成されることがよくあります。 これを行うには、観察された属性のすべての値が含まれる間隔を、長さのいくつかの部分間隔に分割します。 h部分区間ごとに検索します 私は, - に含まれるバリアントの度数の合計 私-間隔。 次に、これらの間隔で、底辺と同様に、高さのある長方形が構築されます (または、 P -サンプルサイズ)。
四角 私部分的な長方形は次と等しい , (または ).
したがって、ヒストグラムの面積は、すべての頻度 (または相対頻度) の合計に等しくなります。 サンプルサイズ(または単位)。
例10.3。図では、 図 10.2 は、連続体積分布のヒストグラムを示しています。 n= 100 を次の表に示します。
数学的統計には、母集団とサンプルという 2 つの基本概念があります。
セットとは、研究者にとって関心のあるいくつかのオブジェクトまたは要素のほぼ数えられるセットです。
コレクションのプロパティは、その要素の一部が共有する現実または想像上の性質です。 プロパティはランダムである場合もあれば、非ランダムである場合もあります。
母集団パラメータは、定数または変数として定量化できるプロパティです。
単純なセットには次のような特徴があります。
別のプロパティ (例: ロシアのすべての学生);
定数または変数の形式の別のパラメータ (すべての女子学生)。
重複しない (互換性のない) プロパティのシステム。例: ウラジオストクの学校のすべての教師と生徒。
複雑なセットには次のような特徴があります。
少なくとも部分的に重複する特性のシステム(金メダルを獲得して学校を卒業した極東州立大学の心理学部および数学学部の学生)。
集合体における独立パラメータと依存パラメータのシステム。 総合的な性格研究で。
均質または均質とは集合であり、そのすべての特性はその各要素に固有のものです。
異質または異質とは、その特徴が要素の個別のサブセットに集中している集団です。
重要なパラメーターは、母集団の体積、つまり母集団を形成する要素の数です。 ボリュームのサイズは、母集団自体がどのように定義されるか、そして特にどのような質問に興味があるかによって異なります。 セッション中に特定の試験を受ける期間中の 1 年生の感情状態に興味があるとします。 すると住民は30分以内に疲弊してしまう。 すべての 1 年生の感情状態に興味がある場合、全体はさらに大きくなり、特定の大学などのすべての 1 年生の感情状態を考慮するとさらに大きくなります。 大規模な集団は選択的にしか研究できないことは明らかです。
サンプルとは一般集団の特定の部分であり、直接研究されるものです。
サンプルは、代表性、サイズ、選択方法、テスト設計に従って分類されます。
代表者 - 一般集団を質的および量的に適切に反映するサンプル。 サンプルは母集団を適切に反映している必要があり、そうでない場合、結果は研究の目的と一致しません。
代表性は体積に依存します。体積が大きいほど、サンプルはより代表的になります。 選考方法による。
Random - 要素がランダムに選択される場合。 数学的統計のほとんどの方法はランダムサンプリングの概念に基づいているため、当然のことながらサンプリングはランダムである必要があります。
非ランダムサンプリング:
機械的選択。母集団全体が、サンプルで計画されている単位と同じ数の部分に分割され、各部分から 1 つの要素が選択されます。
典型的な選択 - 母集団を同種の部分に分割し、それぞれから無作為にサンプルを抽出します。
シリアル選択 - 母集団を多数の異なるサイズのシリーズに分割し、その後 1 つの特定のシリーズのサンプルを作成します。
結合された選択 - 検討中の選択のタイプは、さまざまな段階で結合されます。
テスト設計に応じて、サンプルは独立したものにすることも依存するものにすることもできます。 サンプルサイズに基づいて、サンプルは小と大に分けられます。 小さなサンプルには、要素の数が n 200 で、平均サンプルが条件 30 を満たすサンプルが含まれます。小さなサンプルは、すでに研究されている母集団の既知の特性を統計的に制御するために使用されます。
大規模なサンプルは、母集団の未知の特性とパラメーターを確立するために使用されます。
トピック 1.3 の詳細。 母集団とサンプル:
- 7.2 サンプルと母集団の特徴
- 1.6. 正規分布母集団の相関係数の点推定と区間推定
サンプル研究を実施する必要性は、さまざまな理由によって発生する可能性があります。
多くの場合、研究対象の現象を完全に研究するには費用と時間がかかりすぎます。
場合によっては、完全な研究で受け取った情報を使用する機会が、その準備のプロセスが完了する前に使い果たされる可能性があります。
製品の品質を確認した結果、対象物が破壊されてしまう場合もあります。
例:
母集団が学校の全生徒であるとします (20 クラスから 600 人、各クラスに 30 人)。 研究テーマは喫煙に対する態度です。
人口情報を取得する必要があるオブジェクトのセットです。
一般集団は、研究者が興味を持つ性質と特性を持つすべてのオブジェクトで構成されます。 一般集団が特定の地域の成人集団全体である場合もありますが (たとえば、候補者に対する潜在的な有権者の態度を研究する場合)、ほとんどの場合、研究の対象を決定するいくつかの基準が指定されます。 たとえば、特定のブランドのハンドクリームを少なくとも週に 1 回使用し、家族 1 人あたり少なくとも 5,000 ルーブルの収入がある 10 ~ 89 歳の女性です。
サンプル母集団から抽出されたオブジェクトの小さなセットです。
サンプル母集団とは、一般母集団から特定の手順を使用して選択された結果(症例、被験者、物体、出来事、サンプル)を研究するために必要な最小限の母集団です。
例:
イノベーションに対する会社の顧客の反応を特定する;会社のすべての顧客は一般大衆を代表する。 呼ばれたクライアントはサンプルを形成します。
多数の取引を扱う監査法人を監査する場合、選択した数の取引を調査するだけで満足する必要があります。 会社のすべての取引は一般母集団を形成し、選択された取引はサンプルから形成されます。
一般人口は、特定の年のすべての徴兵で構成されます。
特定の企業で一定期間にわたって製造されたすべてのランプが一般集団を形成します。 制御のために選択されたランプが選択されます。
サンプルは代表的または非代表的とみなされる場合があります。 大規模なグループを調査する場合、サンプルは代表的なものになります。このグループ内にさまざまなサブグループの代表者がいる場合、これが正しい結論を導く唯一の方法です。 。
代表性とは、サンプルの特徴と母集団または一般母集団全体の特徴との対応関係です。代表性は、特定のサンプルを使用した研究の結果を、そのサンプルが収集された母集団全体にどの程度一般化できるかを決定します。
代表性は、研究目的の観点から重要な一般母集団のパラメーターを表すサンプル母集団の特性として定義することもできます。
例:高校生 60 人のサンプルは、各学年 3 人の生徒を含む同じ 60 人のサンプルよりも母集団をあまりよく代表していません。 その主な理由は、クラス内の年齢分布が不均等であることです。 したがって、最初のケースではサンプルの代表性が低く、2 番目のケースでは代表性が高くなります (他の条件がすべて等しい場合)。 .
タスク1。有権者が 253,000 人いる都市で、将来の有権者の政治的傾向を調査します。
解決
サンプルは、大量の取引を残した 15 人ごとの購入者にインタビューすることで作成できます。 ショッピングセンター。 このようなサンプルはショッピングモールの訪問者の意見を反映していますが、すべての都市住民の意見を代表しているとは考えられません。
サンプルを作成するもう 1 つの方法は、電話帳から番号を取得して、都市の居住者 100 人ごとに電話調査を実施することです。 この体系的なサンプリングにより、電話を持っており、家にいて、電話に出る人々のグループの意見に関する情報が提供されます。 しかし、それはすべての都市住民の意見を反映しているわけではありません。
サンプルを作成するもう 1 つの方法は、いくつかの団体が主催する集会の参加者にインタビューすることです。 政党。 このようなサンプルは、活動に積極的に参加している住民に関する情報を提供します。 政治生活都市。
したがって、母集団全体を代表するサンプルを作成する方法が必要です。つまり、サンプルは代表的 (代表的) でなければなりません。
タスク2。サンプルが代表的なものであるかどうかを判断します。
1) 年間の市内の事故に関する統計報告書を作成する必要がある場合、6 月の自動車事故の数。
2) 国内の一人当たりの自動車台数を計算する場合の都市住民。
3) 青少年向けテレビ番組の視聴率を決定する際の年齢は 40 ~ 50 歳。
解決
1) サンプルは代表的なものではありません。 夏には道路に雪も凍結もありませんが、これが事故の主な原因の1つです。
2) サンプルは代表的なものではありません。 田舎よりも都会のほうが車の数が多いのは明らかです。 これを考慮する必要があります。
3) サンプルは代表的なものではありません。 40 歳から 50 歳までの人は、若者向けの番組に興味を示す可能性は低いです。 このようなサンプルを使用すると、評価が大幅に低下する可能性がありますが、これは実際の状況を反映するものではありません。 サンプル母集団を形成するには、次のものを使用します。 さまざまな方法選択 統計は使用できる方法で提示されなければなりません。
母集団とサンプルのパラメータ
N は一般集団であり、層 N 1、N 2 などに分割されます。
地層統計的特性の観点から均質なオブジェクトを表します (たとえば、人口は年齢グループまたは社会階級ごとに階層に分割され、企業は産業ごとに分割されます)。 この場合、サンプルは層別と呼ばれます。
N - サンプルサイズ。
研究の統計的結論は確率変数 X の分布に基づいており、観測値 x 1、x 2、x 3 は確率変数 x の実現値と呼ばれます。
一般集団における確率変数 X の分布は理論的で理想的な性質を持ち、サンプルの類似物は経験的な分布です。
サンプルの場合、分布関数を決定するのは難しく、場合によっては不可能であるため、経験的データからパラメータを推定し、理論的な分布を記述する分析式に代入します。 この場合、分布のタイプに関する仮定は統計的に正しい場合もあれば、誤っている場合もあります。
しかし、いずれの場合でも、サンプルから再構成された経験的分布は、実際の分布を大まかに特徴づけるだけです。
分布の最も重要なパラメータは数学的期待値ですあと分散 σ 2- データ分散の尺度。
標準偏差σ - 観測データまたはセットの平均値からの逸脱の度合い。
タスク3.ミハイルと彼の友人たちは、犬の体高(甲の部分)を測ることにしました。 検索: 平均値。 成長偏差。

解決
数学的な期待値または平均値は、次の式を使用して求めることができます。

次に、各犬の身長の平均値または数学的期待値からの偏差、つまり分散を計算しましょう。
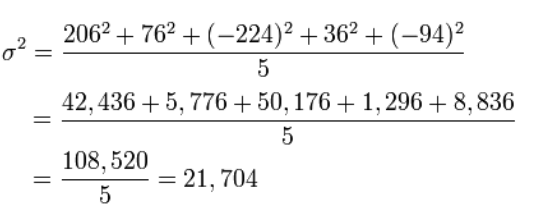

標準偏差はあくまで 平方根分散から。
σ \ = 147,32
したがって、知ることで、 標準偏差私たちは「標準的な身長」が何を意味するのか、そして非常に背の高い犬と非常に小さい犬の構成要素を知っています。
答え: 394、21,704; 147.32。
タスク4。工場で製造された同じ出力のランプの大量バッチから無作為に採取された、同じ出力の 50 個の電球の保存寿命を管理実験室で観察したところ、確立された保証の違反に関する次のデータが得られました。燃焼時間:
|
の偏差 H |
実際の偏差を反映する 10 個の小さな分布 番目保証に記載されている電球の点灯期間。 解決。 平均偏差
したがって、目的の正規分布は次のように特徴付けられます。 次の値でパラメータ: a = 0.4;σ 2 = 318; σ = 17.8。 したがって、確率密度は次のようになります。 この密度に対応する分布関数は次のようになります。 |

確率変数の分布には、その統計的特性に関するすべての情報が含まれています。 分布を構築するには、確率変数の値をいくつ知る必要がありますか? これを行うには、それを探索する必要があります 一般人.
母集団は、特定の確率変数が取り得るすべての値のセットです。
集団内の単位の数はその体積と呼ばれます N。 この値は有限または無限になります。 たとえば、ある都市の住民の増加を研究する場合、人口のサイズは都市の住民の数に等しくなります。 もしあれば 物理実験の場合、一般人口の体積は無限になります。 物理パラメータのすべての可能な値の数は無限大に等しくなります。
一般集団を研究することが常に可能であるとは限らず、推奨されるわけでもありません。 人口の体積が無限であればそれは不可能です。 しかし、量が限られている場合でも、完全な研究は多大な時間と労力を必要とし、通常は結果の絶対的な正確性が要求されないため、必ずしも正当化されるわけではありません。 一般集団の一部のみを調査することで、精度は劣りますが、労力と費用を大幅に削減して結果を得ることができます。 このような調査はサンプリングと呼ばれます。
母集団の一部に対してのみ実施される統計的研究はサンプリングと呼ばれ、母集団の調査対象の部分はサンプルと呼ばれます。
図 7.2 は、母集団と標本をセットとそのサブセットとして記号的に示しています。
図 7.2 母集団とサンプル
特定の母集団の特定のサブセット(多くの場合、その重要性の低い部分を構成する)を扱うと、実用的な目的に十分な精度の結果が得られます。 母集団の大部分を研究することは精度を高めるだけであり、サンプルが統計的な観点から正しく採取されていれば、結果の本質は変わりません。
サンプルが母集団の特性を反映し、結果が信頼できるものとなるためには、次の条件を満たす必要があります。 代表(代表)。
一部の一般集団の場合、その性質上、その一部が代表的なものとなります。 ただし、ほとんどの場合、代表的なサンプルを確保するために特別な措置を講じる必要があります。
1つ現代の数学統計の主な成果の 1 つは、データ選択の代表性を保証するランダム サンプリング法の理論と実践の開発です。
サンプル研究は常に、母集団全体を対象とした研究よりも精度が劣ります。 ただし、誤差の大きさがわかっていれば、これを調整することができます。 明らかに、サンプルサイズが母集団サイズに近ければ近いほど、誤差は小さくなります。 このことから、統計的推論の問題は、小さなサンプルを扱う場合に特に関連することが明らかです ( N ? 10-50).
これは、確率論の手法に基づいて、科学的かつ実践的な結論を得るために統計データの体系化と処理を扱う科学です。
統計データ 特定の特性を持つオブジェクトの数に関する情報を指します .
何らかの定性的または量的特性に従って結合されたオブジェクトのグループをと呼びます。 統計的全体性 。 コレクションに含まれるオブジェクトはその要素と呼ばれ、その総数がコレクションの要素となります。 音量。
一般人口は、特定の実際の条件セット、またはより厳密な条件の下で行うことができる、考えられるすべての観察のセットです。 一般母集団は確率変数 x とそれに関連する確率空間 (W, Á, P) です。
確率変数 x の分布は次のように呼ばれます。 人口分布(彼らは、たとえば、正規分布の母集団や単純に正規の母集団について話します)。
たとえば、確率変数の独立した測定が多数行われた場合、 バツ、その場合、一般集団は理論的には無限です(つまり、一般集団は抽象的な従来の数学的概念です)。 N 製品のバッチ内の不良製品の数がチェックされる場合、このバッチは体積 N の有限の一般母集団と見なされます。
社会経済調査の場合、ボリューム N の一般人口は都市、地域、または国の人口である可能性があり、測定される特性は個人の収入、支出、または貯蓄額である可能性があります。 属性が定性的性質 (性別、国籍、社会的地位、職業など) であるものの、有限のオプションのセットに属している場合、それを数値としてエンコードすることもできます (アンケートでよく行われるように)。 )。
オブジェクトの数 N が十分に大きい場合、包括的な調査 (たとえば、すべてのカートリッジの品質を確認する) を実施することは困難であり、場合によっては物理的に不可能です。 次に、限られた数のオブジェクトが母集団全体からランダムに選択され、研究の対象となります。
サンプル母集団または単に サンプリングボリューム n の は、独立して同一に分布する確率変数のシーケンス x 1 、 x 2 、...、 x n であり、それぞれの分布は確率変数 x の分布と一致します。
たとえば、確率変数の最初の n 回の測定結果 バツこれを無限の母集団からのサイズ n のサンプルと考えるのが通例です。 得られたデータは次のように呼ばれます 確率変数の観測 x、そして確率変数 x は x 1、x 2、…、x n の「値を取る」とも言います。
数学的統計の主なタスクは、1 つ以上の未知の確率変数の分布またはそれらの相互の関係について科学に基づいた結論を下すことです。 サンプルの特性と特徴に基づいて、確率変数(一般集団)の数値的特徴と分布法則について結論を下すという事実からなる方法は、と呼ばれます 選択的方法.
サンプリング法によって得られた確率変数の特性が客観的であるためには、サンプルが正確である必要があります。 代表 それらの。 研究された量を非常によく表しています。 法の力によって 多数サンプルがランダムに実行された場合、サンプルは代表的なものになると主張することができます。 母集団内のすべてのオブジェクトがサンプルに含まれる確率は同じです。 このためには、 異なる種類サンプルの選択。
1. 単純ランダム サンプリングは、母集団全体からオブジェクトを一度に 1 つずつ選択する選択です。
2. 層状(層状)) 選択では、ボリューム N の元の母集団がサブセット (階層) N 1、N 2、...、N k に分割され、N 1 + N 2 +...+ N k = N になります。が決定されると、それぞれからボリューム n 1、n 2、...、n k の単純なランダム サンプルが抽出されます。 層別選択の特別なケースは典型的選択であり、この場合、オブジェクトは母集団全体からではなく、母集団の各典型的な部分から選択されます。
組み合わせた選択複数のタイプの選択を一度に組み合わせて、サンプル調査のさまざまな段階を形成します。 他にもサンプリング方法はあります。
サンプルは次のように呼ばれます 繰り返された , 次のオブジェクトを選択する前に、選択したオブジェクトが母集団に返された場合。 サンプルは次のように呼ばれます 繰り返し可能な , 選択したオブジェクトが母集団に戻されない場合。 有限母集団の場合、リターンのないランダム選択は各ステップで個々の観測値の依存性をもたらし、リターンを伴う均等に可能なランダム選択は観測値の独立性をもたらします。 実際には、通常、非反復サンプルを扱います。 ただし、母集団サイズ N がサンプル サイズ n よりも何倍も大きい場合 (たとえば、数百倍または数千倍)、観測値の依存性は無視できます。
したがって、ランダム サンプル x 1、x 2、...、x n は、一般母集団を表す確率変数 ξ の連続的かつ独立した観察の結果であり、サンプルのすべての要素は元の確率変数と同じ分布を持ちます。バツ。
分布関数 F x (x) と確率変数の他の数値特性を x と呼びます。 理論的、 とは異なり サンプルの特性 、観測結果から決定されます。
サンプル x 1、x 2、...、x k を確率変数 x の独立した観測の結果とし、x 1 は n 1 回、x 2 - n 2 回、...、x k - n k 回観測されたとします。 、したがって、n i = n - サンプルサイズになります。 値 x i が n 回の観測で何回出現したかを示す数値 n i は、と呼ばれます。 頻度 与えられた値と比率 n i /n = w私- 相対頻度. 明らかに数字が w私は合理的です。
特徴を昇順に並べた統計母集団を バリエーションシリーズ 。 そのメンバーは x (1)、x (2)、... x (n) と呼ばれ、 オプション . バリエーションシリーズと呼ばれるものは、 離散、そのメンバーが特定の分離された値を取る場合。 統計的分布 離散確率変数のサンプリング バツオプションとそれに対応する相対頻度のリストと呼ばれる w私。 結果として得られるテーブルは次のように呼ばれます。 統計的に近い。
| ×(1) | ×(2) | ... | × k(k) |
| ω1 | ω2 | ... | ωk |
最大のものと 最小値変動系列は x min と x max で表され、と呼ばれます。 バリエーションシリーズのエクストリームメンバー。
連続確率変数を研究する場合、グループ化は、観測値の区間を等しい長さ h の k 個の部分区間に分割し、これらの区間に該当する観測値の数をカウントすることで構成されます。 結果として得られる数値は、頻度 n i として取得されます (新しい、すでに離散的な確率変数の場合)。 通常、間隔の中間値がオプション x i の新しい値として取得されます (または間隔自体が表に示されます)。 スタージェスの公式によれば、推奨される分割間隔の数は k » 1 + log 2 です。 n、部分区間の長さは h = (x max - x min)/k に等しくなります。 区間全体が の形式を持つと想定されます。
統計系列は、多角形、ヒストグラム、または累積頻度のグラフの形式でグラフィック表示できます。
周波数ポリゴン破線と呼ばれ、その線分は点 (x 1, n 1)、(x 2, n 2)、...、(x k, n k) を接続します。 ポリゴン 相対周波数 破線と呼ばれ、その線分は点 (x 1、 w 1)、(×2、 w 2), …, (x k , w k)。 多角形は通常、離散確率変数の場合にサンプルを表すのに役立ちます (図 7.1.1)。
米。 7.1 
.1.
相対頻度ヒストグラム長方形から構成される階段状の図形と呼ばれ、その底辺は長さ h の部分間隔であり、高さは
等しい w私/時間。 

ヒストグラムは通常、連続確率変数の場合のサンプルを表すために使用されます。 ヒストグラムの面積は 1 に等しくなります (図 7.1.2)。 相対度数のヒストグラムの中点を結ぶと 上辺長方形を作成すると、結果の破線が相対度数の多角形を形成します。 したがって、ヒストグラムはグラフとして見ることができます。 経験的(サンプル)分布密度 fn(x)。 理論的な分布の密度が有限である場合、経験的な密度は理論的な密度の近似値となります。
累積周波数のグラフヒストグラムと同様に作成された図ですが、長方形の高さを計算するために単純なものが取得されるのではなく、 累積相対周波数, それらの。 量 これらの値は減少せず、累積された周波数のグラフは階段状の「階段」(0から1まで)の形になります。
累積周波数のグラフは、理論的な分布関数を近似するために実際に使用されます。
タスク。この地域の中小企業 100 社のサンプルが分析されました。 調査の目的は、i 番目の各企業の借入資金と自己資金の比率 (x i) を測定することです。 結果を表 7.1.1 に示します。
テーブル企業の負債と自己資本の比率。
| 5,56 | 5,45 | 5,48 | 5,45 | 5,39 | 5,37 | 5,46 | 5,59 | 5,61 | 5,31 |
| 5,46 | 5,61 | 5,11 | 5,41 | 5.31 | 5,57 | 5,33 | 5,11 | 5,54 | 5,43 |
| 5,34 | 5,53 | 5,46 | 5,41 | 5,48 | 5,39 | 5,11 | 5,42 | 5,48 | 5,49 |
| 5,36 | 5,40 | 5,45 | 5,49 | 5,68 | 5,51 | 5,50 | 5,68 | 5,21 | 5,38 |
| 5,58 | 5,47 | 5,46 | 5,19 | 5,60 | 5,63 | 5,48 | 5,27 | 5,22 | 5,37 |
| 5,33 | 5,49 | 5,50 | 5,54 | 5,40 | 5.58 | 5,42 | 5,29 | 5,05 | 5,79 |
| 5,79 | 5,65 | 5,70 | 5,71 | 5,85 | 5,44 | 5,47 | 5,48 | 5,47 | 5,55 |
| 5,67 | 5,71 | 5,73 | 5,05 | 5,35 | 5,72 | 5,49 | 5,61 | 5,57 | 5,69 |
| 5,54 | 5,39 | 5,32 | 5,21 | 5,73 | 5,59 | 5,38 | 5,25 | 5,26 | 5,81 |
| 5,27 | 5,64 | 5,20 | 5,23 | 5,33 | 5,37 | 5,24 | 5,55 | 5,60 | 5,51 |
累積頻度のヒストグラムとグラフを作成します。
解決. グループ化された一連の観察を作成してみましょう。
1. サンプルで x min = 5.05 および x max = 5.85 を決定してみましょう。
2. 範囲全体を k 個の等間隔に分割しましょう: k » 1 + log 2 100 = 7.62; k = 8、したがって区間の長さ ![]()
表7.1.2。グループ化された一連の観察
| インターバル番号 | 間隔 | 区間の中点 x i | w私 | fn(x) | |
| 5,05-5,15 | 5,1 | 0,05 | 0,05 | 0,5 | |
| 5,15-5,25 | 5,2 | 0,08 | 0,13 | 0,8 | |
| 5,25-5,35 | 5,3 | 0,12 | 0,25 | 1,2 | |
| 5,35-5,45 | 5,4 | 0,20 | 0,45 | 2,0 | |
| 5,45-5,55 | 5,5 | 0,26 | 0,71 | 2,6 | |
| 5,55-5,65 | 5,6 | 0,15 | 0,86 | 1,5 | |
| 5,65-5,75 | 5,7 | 0,10 | 0,96 | 1,0 | |
| 5,75-5,85 | 5,8 | 0,04 | 1,00 | 0,4 |
図では、 表 7.1.2 のデータに従って構築された 7.1.3 および 7.1.4 は、累積頻度のヒストグラムとグラフを示しています。 曲線は、データに「適合」した密度および正規分布関数に対応します。


したがって、標本分布は母集団分布の近似値となります。