 入り口
入り口算術平均を計算する方法。 条件に応じて平均値を算出します。 絶対的な成長、チェーンおよびベースの成長、および成長率
中のすべての人が 現代世界ローンを組む計画を立てたり、冬に向けて野菜を買いだめしたりするとき、「平均値」という概念に定期的に遭遇します。 それが何であるか、どのようなタイプとクラスが存在するか、そしてなぜそれが統計や他の分野で使用されるのかを調べてみましょう。
平均値 - それは何ですか?
類似名 (SV) は、任意の 1 つの量的変数特性によって決定される、均一な現象のセットの一般化された特性です。
しかし、そのような難解な定義から遠く離れている人々は、この概念を何かの平均的な量として理解します。 たとえば、銀行員はローンを組む前に、潜在的な顧客に年間の平均収入、つまり人が稼ぐ合計金額に関するデータの提供を必ず求めます。 年間全体の収入を合計し、月数で割ることで計算されます。 したがって、銀行は顧客が期日までに借金を返済できるかどうかを判断できます。
なぜ使われるのでしょうか?
原則として、平均値は、集団的な性質の特定の社会現象の概要を説明するために広く使用されています。 上記の例のローンの場合のように、小規模な計算にも使用できます。

ただし、ほとんどの場合、平均値は依然としてグローバルな目的で使用されます。 そのうちの 1 つの例は、1 暦月中に国民が消費する電力量の計算です。 得られたデータに基づいて、さらに確立されます 最高基準国家からの恩恵を享受している人口のカテゴリー向け。
も使用しています 平均値特定の家電製品、自動車、建物などの耐用年数の保証期間が定められており、かつてはこのようにして収集されたデータに基づいて、現代の労働と休憩の基準が策定されました。
事実上あらゆる現象 現代の生活、それは大衆的な性質のものであり、何らかの形で検討中の概念と必然的に結びついています。
応用分野
この現象は、ほぼすべての精密科学、特に実験的な性質のもので広く使用されています。
平均値を見つけることは、医学、工学、料理、経済、政治などにおいて非常に重要です。
このような一般化から得られたデータに基づいて、彼らは治療薬、教育プログラムを開発し、最低生活レベルと賃金を確立し、 トレーニングスケジュール、家具、衣類、靴、衛生用品などを生産しています。
数学では、この用語は「平均値」と呼ばれ、さまざまな例や問題を解くために使用されます。 最も単純なものは、通常の分数による加算と減算です。 結局のところ、ご存知のとおり、このような例を解くには、両方の分数を共通の分母にする必要があります。
精密科学の女王でも、似た意味の「確率変数の平均値」という用語がよく使われます。 これは「数学的期待値」として多くの人によく知られており、確率論で考慮されることがよくあります。 同様の現象が統計計算を実行する場合にも当てはまることに注意してください。
統計における平均値
ただし、研究されている概念は統計で最もよく使用されます。 知られているように、この科学自体は、大衆社会現象の定量的特性の計算と分析に特化しています。 したがって、統計における平均値は、情報の収集と分析という主な目的を達成するための特殊な方法として使用されます。

この統計手法の本質は、考慮中の特性の個々の固有の値を特定のバランスの取れた平均値に置き換えることです。
例としては、有名な食べ物のジョークがあります。 で、ある工場では火曜日の昼休みに、上司は肉キャセロールを食べ、一般従業員はキャベツの煮物を食べるのが常だという。 これらのデータに基づいて、工場スタッフは平均して火曜日にロールキャベツを食べていると結論付けることができます。
この例は少し誇張されていますが、平均値を検索する方法の主な欠点、つまりオブジェクトや人格の個々の特性を平準化することを示しています。
平均値では、収集された情報を分析するだけでなく、さらなる行動を計画および予測するためにも使用されます。
また、達成された結果 (たとえば、春夏シーズンの小麦の栽培と収穫の計画の実施) を評価するためにも使用されます。
正しい計算方法
SVの種類によって計算式は異なりますが、 一般理論統計では、原則として、特性の平均値を計算するために 1 つの方法のみが使用されます。 これを行うには、まずすべての現象の値を合計し、次に結果の合計をそれらの数で割る必要があります。

このような計算を行う場合、平均値は常に母集団の個々の単位と同じ次元 (または単位) を持つことを覚えておく価値があります。

正しく計算されるための条件
上で説明した式は非常にシンプルで普遍的なものであるため、間違いを犯すことはほとんどありません。 ただし、常に 2 つの側面を考慮する価値があります。そうしないと、取得されるデータが実際の状況を反映しなくなります。

SVクラス
「平均値とは何ですか?」「どこで使用されますか?」という基本的な質問に対する答えが見つかりました。 「どうやって計算するの?」と疑問に思ったら、どのようなクラスとタイプの SV が存在するのかを調べてみる価値があります。
まず、この現象は2つに分類される。 これらは構造的な平均と電力の平均です。
パワーSVの種類
上記の各クラスはさらにタイプに分類されます。 鎮静クラスは4名です。

- 算術平均は、SV の最も一般的なタイプです。 これは、データ セット内で考慮されている特性の合計量が、このセットのすべてのユニットに均等に配分されるかを決定する際の平均項です。
このタイプは、単純な算術 SV と加重算術 SV のサブタイプに分類されます。
- 調和平均は、考慮中の特性の逆数値から計算される、単純算術平均の逆数である指標です。
属性や製品の個別の値はわかっているが、頻度データはわかっていない場合に使用されます。
- 幾何平均は、成長率を分析するときに最もよく使用されます。 経済現象。 これにより、特定の量の個々の値の合計ではなく積を変更せずに保存することが可能になります。
シンプルでバランスのとれたものにすることもできます。
- 平均 二次量計算に使用される 個別の指標生産リズムを特徴付ける変動係数などの指標。
また、パイプ、車輪、正方形の平均辺、および同様の図形の平均直径を計算するためにも使用されます。
他のすべてのタイプの平均と同様に、二乗平均平方根は単純で重み付けできます。
構造量の種類
平均 SV に加えて、構造タイプも統計でよく使用されます。 これらは、さまざまな特性の値の相対的な特性を計算するのに適しています。 内部構造配布行。
このようなタイプは 2 つあります。

統計集計の単位の特徴は、その意味において異なります。たとえば、企業の同じ職業の労働者の賃金は同じ期間では同じではありません、同じ製品の市場価格、地区の作物の収量などです。農場など したがって、研究対象のユニットの母集団全体の特徴である特性の値を決定するために、平均値が計算されます。
平均値 –
これは、ある量的特性の個々の値のセットの一般化された特性です。
定量ベースで調査される母集団は、個々の値で構成されます。 彼らは影響を受けています よくある理由、 それで 個別の条件。 平均値では、個々の値に特徴的な偏差が相殺されます。 平均は一連の個別の値の関数であり、1 つの値で集計全体を表し、そのすべての単位に共通するものを反映します。
質的に同質の単位からなる集団に対して計算された平均は、と呼ばれます。 典型的な平均。 たとえば、特定の専門職グループ (鉱山労働者、医師、図書館司書) の従業員の平均月給を計算できます。 もちろん月間レベルも 賃金鉱山労働者は、資格、勤続年数、月あたりの労働時間、その他多くの要因の違いにより、互いに異なり、また平均賃金のレベルも異なります。 ただし、平均水準は賃金水準に影響を与える主な要因を反映しており、従業員の個人特性によって生じる差異は相殺されます。 平均給与は、特定の種類の労働者の典型的な報酬レベルを反映しています。 典型的な平均を求める前に、特定の母集団がどの程度質的に均一であるかを分析する必要があります。 全体が個別の部分で構成されている場合は、典型的なグループに分割する必要があります ( 平均温度病院による)。
異種集団の特徴として使用される平均値はと呼ばれます システムの平均。 たとえば、一人当たりの国内総生産(GDP)の平均値、一人当たりのさまざまな財グループの消費の平均値、および統一された経済システムとしての国家の一般的な特徴を表すその他の同様の値です。
平均は、十分な数からなる母集団に対して計算する必要があります。 多数単位。 法律が発効するにはこの条件の遵守が必要です 多数、その結果として、個体値のランダムな偏差が 一般的な傾向お互いを打ち消し合う。
平均の種類と計算方法
平均の種類の選択は、特定の指標とソース データの経済的内容によって決まります。 ただし、平均値は、平均化された特性の各バリアントを置き換えるときに、最終的な、一般化された、または一般的に呼ばれる特性が変化しないように計算する必要があります。 指標の定義、これは平均化されたインジケーターに関連付けられています。 たとえば、ルートの個々のセクションの実際の速度を置き換える場合、 平均速度同じ時間内に車両が移動した総距離は変化してはなりません。 実際の賃金に置き換える場合 個々の労働者中堅企業 賃金賃金基金は変えるべきではない。 したがって、それぞれの特定のケースでは、利用可能なデータの性質に応じて、研究対象の社会経済現象の特性と本質に適切な指標の真の平均値が 1 つだけ存在します。
最も一般的に使用されるのは、算術平均、調和平均、幾何平均、二次平均、および三次平均です。
リストされた平均はクラスに属します 鎮静する平均して団結する 一般式:
,
ここで、 は調査対象の特性の平均値です。
m – 平均次数指数。
– 平均化される特性の現在値(バリアント)。
n – 特徴の数。
指数 m の値に応じて、次のタイプの電力平均が区別されます。
m = -1 の場合 – 調和平均。
m = 0 – 幾何平均。
m = 1 の場合 – 算術平均。
m = 2 の場合 – 二乗平均平方根。
m = 3 – 平均立方体。
同じ初期データを使用する場合、上式の指数 m が大きいほど、 より多くの価値平均サイズ:
.
定義関数の指数が増加するにつれて電力平均が増加するこの特性は、と呼ばれます。 平均値の多数決の法則.
マークされた平均はそれぞれ、次の 2 つの形式を取ることができます。 単純そして 重み付けされた.
シンプルなミディアムフォルム平均がプライマリ (グループ化されていない) データから計算される場合に使用されます。 加重フォーム– 二次(グループ化)データに基づいて平均を計算する場合。
算術平均
算術平均は、母集団の体積がさまざまな特性のすべての個別値の合計である場合に使用されます。 平均の種類が指定されていない場合は、算術平均が仮定されることに注意してください。 その論理式は次のようになります。 ![]()
単純な算術平均計算された グループ化されていないデータに基づく
式によると: ![]() または 、
または 、
特性の個々の値はどこにありますか。
j – シリアルナンバー値によって特徴付けられる観測単位。
N – 観測単位の数 (母集団の体積)。
例。講義「統計データの要約とグループ化」では、10 人のチームの作業経験を観察した結果を検討しました。 チームの従業員の平均勤務経験を計算してみましょう。 5、3、5、4、3、4、5、4、2、4。
単純な算術平均公式を使用して、次のように計算することもできます。 時系列の平均、特性値が提示される時間間隔が等しい場合。
例。音量 販売された製品第 1 四半期の総面積は 47 den でした。 単位は、2 番目が 54、3 番目が 65、4 番目が 58 den です。 単位 平均四半期売上高は、(47+54+65+58)/4 = 56 den です。 単位
瞬間的な指標が時系列で与えられている場合、平均を計算するとき、それらは期間の開始時と終了時の値の半分の合計に置き換えられます。
2 つ以上の瞬間があり、それらの間隔が等しい場合、時系列平均の公式を使用して平均が計算されます。
 ,
,
ここで、n は時点の数です
データを特性値ごとにグループ化する場合
(つまり、離散変分分布系列が構築されています) 加重算術平均周波数または特性の特定の値の観測値の頻度のいずれかを使用して計算され、その数 (k) が観測値 (N) の数より大幅に小さい。
,
,
ここで、k は変動系列のグループの数です。
i – バリエーション シリーズのグループ番号。
, a なので、実際の計算に使用される式が得られます。
そして
例。グループ化された行の作業チームの平均勤続年数を計算してみましょう。
a) 周波数を使用する:
b) 周波数を使用する:
データを区間ごとにグループ化する場合
、つまり は区間分布系列の形式で表示されます。算術平均を計算するときは、指定された区間にわたる人口単位の一様分布の仮定に基づいて、区間の中央が属性の値として取得されます。 計算は次の式を使用して実行されます。
そして
間隔の中央は次のとおりです: 、
ここで、 と は間隔の下限と上限です (特定の間隔の上限が次の間隔の下限と一致する場合)。
例。労働者 30 人の年間賃金の調査結果に基づいて構築された区間変動系列の算術平均を計算してみましょう (講義「統計データの要約とグループ化」を参照)。
表 1 – 間隔変動系列の分布。
インターバル、UAH |
頻度、人数 |
頻度、 |
インターバルの真ん中 |
||
600-700 |
3 |
0,10 |
(600+700):2=650 |
1950 |
65 |
![]() ああ または
ああ または ![]() ああ
ああ
ソースデータと区間変動系列に基づいて計算された算術平均は、区間内の属性値の不均一な分布により一致しない場合があります。 この場合、加重算術平均をより正確に計算するには、間隔の中央ではなく、各グループに対して計算された単純な算術平均を使用する必要があります( グループ平均)。 グループ平均から加重計算式を用いて計算した平均を といいます。 全体平均.
算術平均には多くの特性があります。
1. 平均オプションからの偏差の合計はゼロです。
.
2. オプションのすべての値が量 A だけ増減する場合、平均値も同じ量 A だけ増減します。 ![]()
3. 各オプションが B 回増加または減少すると、平均値も同じ回数だけ増加または減少します。
または ![]()
4. オプションと頻度の積の合計は、平均値と頻度の合計の積に等しくなります。 ![]()
5. すべての周波数を任意の数値で除算または乗算しても、算術平均は変わりません。 
6) すべての区間で頻度が互いに等しい場合、加重算術平均は単純な算術平均と等しくなります。 ![]() ,
,
ここで、k は変動系列のグループの数です。
平均のプロパティを使用すると、平均の計算を簡素化できます。
すべてのオプション (x) が最初に同じ数値 A だけ減らされ、次に係数 B だけ減らされると仮定します。 最も高い頻度の間隔の中央の値を A として選択し、間隔の値 (同一間隔の系列の場合) を B として選択すると、最も単純化が達成されます。 数量 A は原点と呼ばれるため、平均を計算するこの方法は と呼ばれます。 方法 b 条件付きゼロからのオーム基準または 瞬間のやり方.
このような変換の後、新しい変分分布系列が得られます。その変量は に等しくなります。 それらの算術平均は、 最初の注文の瞬間、は次の式で表され、2 番目と 3 番目のプロパティに従って、算術平均は元のバージョンの平均に等しく、最初に A 倍、次に B 倍に減算されます。
入手用 実質平均(元の系列の平均) 1 次モーメントに B を乗算し、A を加算する必要があります。 
モーメント法を使用した算術平均の計算を表のデータに示します。 2.
表 2 – 工場勤務者の勤続年数別分布
従業員の勤続年数、年数 |
労働者数 |
インターバルの真ん中 |
|||
0 – 5 |
12 |
2,5 |
15 |
3 |
36 |
一次瞬間の発見 ![]() 。 次に、A = 17.5 および B = 5 であることがわかっているので、工場労働者の平均勤続年数を計算します。
。 次に、A = 17.5 および B = 5 であることがわかっているので、工場労働者の平均勤続年数を計算します。
年
調和平均
上に示したように、算術平均は、その変量 x とその周波数 f が既知の場合に、特性の平均値を計算するために使用されます。
統計情報に母集団の個々の選択肢 x の度数 f が含まれていないが、それらの積として表されている場合、次の式が適用されます。 加重調和平均。 平均を計算するには、ここで を示します。 これらの式を算術加重平均の公式に代入すると、調和加重平均の公式が得られます。  ,
,
ここで、 は番号 i (i=1,2, …, k) の区間におけるインジケーター属性値の量 (重み) です。
したがって、調和平均は、合計の対象となるのがオプション自体ではなく、その逆数である場合に使用されます。 ![]() .
.
各オプションの重みが異なる場合 1に等しい、つまり 逆特性の個々の値は一度発生し、適用されます 平均調和単純: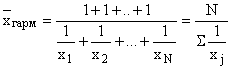 ,
,
ここで、 は 1 回発生する逆特性の個々のバリアントです。
N – 数値オプション。
母集団の 2 つの部分に調和平均がある場合、次の式を使用して母集団全体の全体平均が計算されます。 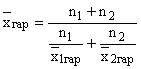
そして呼ばれます グループ平均の加重調和平均.
例。為替取引では、取引開始から最初の1時間で3件の取引が成立した。 グリブナの売上高と米ドルに対するグリブナの為替レートに関するデータを表に示します。 3 (列 2 および 3)。 取引の最初の 1 時間の米ドルに対するグリブナの平均為替レートを決定します。
表 3 – 外国為替取引の取引進捗状況に関するデータ
平均ドル為替レートは、すべての取引中に販売されたグリブナの金額と、同じ取引の結果として取得されたドルの金額の比率によって決定されます。 グリブナの最終的な販売額は表の 2 列目からわかり、各取引で購入されるドル数はグリブナの販売額を為替レート (4 列目) で割ることによって決定されます。 3回の取引で総額2200万ドルが購入された。 これは、1 ドルに対するグリブナの平均為替レートが 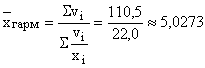 .
.
結果の値は実数です。 取引における実際のグリブナ為替レートに置き換えても、最終的なグリブナ売上高は変わりません。 指標の定義: 100万UAH
算術平均が計算に使用された場合、つまり ![]() グリブナ、2,200万ドルの購入の為替レートで。 1 億 1,066 万 UAH を費やす必要がありますが、これは真実ではありません。
グリブナ、2,200万ドルの購入の為替レートで。 1 億 1,066 万 UAH を費やす必要がありますが、これは真実ではありません。
幾何平均
幾何平均は現象のダイナミクスを分析するために使用され、次のことを決定することができます。 平均係数成長。 幾何平均を計算する場合、特性の個々の値は次のようになります。 相対指標前のレベルに対する各レベルの比率として、チェーン量の形式で構築されたダイナミクス。
単純な幾何平均は、次の式を使用して計算されます。  ,
,
製品の記号はどこにありますか、
N – 平均値の数。
例。 4年間の犯罪登録件数は1.57倍に増加しており、そのうち1回目は1.08倍、2回目は1.1倍、3回目は1.18倍、4回目は1.12倍となっている。 この場合、犯罪数の平均年間増加率は次のようになります。つまり、 登録された犯罪の数は毎年平均 12% 増加しました。
1,8
-0,8
0,2
1,0
1,4
1
3
4
1
1
3,24
0,64
0,04
1
1,96
3,24
1,92
0,16
1
1,96
加重平均二乗を計算するには、 を決定し、テーブルに入力します。 この場合、指定された標準からの製品の長さの平均偏差は次のようになります。 
この場合、算術平均は不適切です。 その結果、偏差はゼロになります。
二乗平均の使用については、バリエーションの観点からさらに説明します。
算術平均は、特定のデータ配列の平均値を示す統計指標です。 このインジケーターは分数として計算され、その分子は配列内のすべての値の合計であり、分母はその数値です。 算術平均は、日常の計算で使用される重要な係数です。
係数の意味
算術平均は、データを比較し、許容可能な値を計算するための基本的な指標です。 たとえば、さまざまな店舗が特定のメーカーの缶ビールを販売しています。 しかし、ある店では67ルーブル、別の店では70ルーブル、3番目の店では65ルーブル、最後の店では62ルーブルです。 価格にはかなりの幅があるため、購入者は製品を購入するときにコストを比較できるように、缶の平均コストに興味を持ちます。 市内の缶ビールの平均価格は次のとおりです。
平均価格 = (67 + 70 + 65 + 62) / 4 = 66 ルーブル。
平均価格がわかれば、どこで製品を購入するのが有益で、どこで過剰に支払わなければならないかを判断するのが簡単になります。
算術平均は、同種のデータのセットを分析する場合の統計計算で常に使用されます。 上の例では、同じブランドの缶ビールの価格です。 ただし、異なるメーカーのビールの価格やビールとレモネードの価格を比較することはできません。この場合、値のばらつきが大きくなり、平均価格があいまいで信頼性が低くなり、計算の意味そのものが失われてしまうためです。 「病院の平均体温」の風刺画に歪められるだろう。 異種データセットを計算するには、各値が独自の重み付け係数を受け取る場合、重み付けされた算術平均が使用されます。
算術平均の計算
計算式は非常に簡単です。
P = (a1 + a2 + … an) / n、
ここで、an は数量の値、n は値の合計数です。
このインジケーターは何に使用できますか? それが最初に明らかに使用されるのは統計です。 ほぼすべての統計研究では算術平均が使用されます。 これは、ロシアの平均結婚年齢、学童の科目の平均成績、または 1 日あたりの食料品の平均支出などです。 上で述べたように、重みを考慮せずに平均を計算すると、奇妙な値や不合理な値が生成される可能性があります。
たとえば、社長は ロシア連邦統計によれば、ロシア人の平均給与は27,000ルーブルであると声明を発表した。 ほとんどのロシア居住者にとって、この水準の給与は馬鹿げているように思えた。 計算するときに、一方では寡頭政治、産業企業のトップ、大銀行家の収入を考慮に入れ、他方では教師、清掃員、販売員の給与を考慮に入れても不思議ではありません。 たとえば会計士など、1 つの専門分野の平均給与でも、モスクワ、コストロマ、エカテリンブルクでは大きな違いがあります。
異種データの平均を計算する方法
給与計算では、各値の重みを考慮することが重要です。 これは、寡頭政治家や銀行家の給与には、たとえば 0.00001 の重みが与えられ、営業マンの給与には 0.12 が重み付けされることを意味します。 これらは突然の数字だが、ロシア社会における寡頭政治やセールスマンの蔓延を大まかに表している。
したがって、異種データセット内の平均値の平均または平均値を計算するには、算術加重平均を使用する必要があります。 それ以外の場合、ロシアで受け取る平均給与は27,000ルーブルになります。 あなたがあなたのことを知りたいなら 平均評価数学や、選択したホッケー選手が得点した平均ゴール数を知りたい場合は、算術平均計算ツールが最適です。
私たちのプログラムは、算術平均を計算するためのシンプルで便利な計算機です。 計算を実行するには、パラメーター値を入力するだけです。
いくつかの例を見てみましょう
平均スコアの計算
多くの教師は、算術平均法を使用して科目の年間成績を決定します。 子供が数学で 3、3、5、4 という 4 分の 1 の成績を取ったと想像してみましょう。教師は彼に年間何点を与えるでしょうか? 電卓を使って算術平均を計算してみましょう。 まず、適切な数のフィールドを選択し、表示されるセルに評価値を入力します。
(3 + 3 + 5 + 4) / 4 = 3,75
教師は生徒に有利な値を四捨五入し、生徒はその年間で堅実な B を受け取ります。
食べたキャンディーの計算
算術平均の不合理性をいくつか説明してみましょう。 マーシャとヴォヴァがキャンディーを 10 個持っていたと想像してみましょう。 マーシャはキャンディーを 8 個食べましたが、ヴォバは 2 個だけでした。子供たちは平均してキャンディーを何個食べましたか? 電卓を使用すると、子供たちが平均して 5 個のキャンディーを食べたことが簡単に計算できますが、これは現実と常識と完全に矛盾しています。 この例は、意味のあるデータセットにとって算術平均が重要であることを示しています。
結論
算術平均の計算は、多くの科学分野で広く使用されています。 この指標は統計計算だけでなく、物理学、力学、経済学、医学、金融などでもよく使われています。 算術平均の計算に関する問題を解決するためのアシスタントとして電卓を使用します。
平均値は統計で広く使用されます。 平均値は、流通コスト、利益、収益性などの商業活動の定性的指標を特徴付けます。
平均 - これは一般的な一般化手法の 1 つです。 平均の本質を正しく理解することによって、市場経済における平均の特別な重要性が決まります。そのとき、平均は、個別的でランダムなものを通して、一般的で必要なものを特定し、経済発展のパターンの傾向を特定することができます。
平均値 - これらはアクションを表す一般的な指標です 一般的な条件、研究されている現象のパターン。
統計的平均は、正しく統計的に組織された質量観察 (連続的および選択的) からの質量データに基づいて計算されます。 ただし、質的に均一な集団(集団現象)の集団データから計算された場合、統計的平均は客観的かつ典型的になります。 たとえば、協同組合や国有企業の平均賃金を計算し、その結果を全人口に拡張すると、異質な人口を対象として計算されているため、平均は架空のものとなり、そのような平均はまったく意味を失います。
平均値の助けを借りて、個々の観察単位で何らかの理由で生じる特性値の差異が平滑化されます。
たとえば、営業担当者の平均生産性は、資格、勤続年数、年齢、サービス形態、健康状態など、さまざまな理由によって決まります。
平均生産量は、母集団全体の一般的な特性を反映しています。
平均値は研究対象の特性の値を反映しているため、この特性と同じ次元で測定されます。
それぞれの平均値は、いずれか 1 つの特性に従って調査対象の母集団を特徴付けます。 多くの重要な特徴に従って研究対象の母集団を完全かつ包括的に理解するには、一般に、さまざまな角度から現象を説明できる平均値のシステムが必要です。
さまざまな平均があります。
算術平均。
幾何平均。
調和平均。
平均二乗;
平均的な時系列。
統計で最もよく使用される平均の種類をいくつか見てみましょう。
算術平均
単純算術平均 (加重なし) は、属性の個々の値の合計をこれらの値の数で割ったものに等しくなります。
特性の個々の値はバリアントと呼ばれ、x() で表されます。 母集団の数は n で示され、特性の平均値は で示されます。  。 したがって、算術単純平均は次と等しくなります。
。 したがって、算術単純平均は次と等しくなります。

離散分布系列データによれば、同じ特性値(変異)が複数回繰り返されることが明らかです。 したがって、選択肢 x は合計 2 回、選択肢 x は 16 回出現します。
分布系列における特性の同一の値の数は、頻度または重みと呼ばれ、記号 n で表されます。
労働者1人の平均給与を計算してみましょう  摩擦中:
摩擦中:
労働者の各グループの賃金基金はオプションと頻度の積に等しく、これらの積の合計がすべての労働者の賃金基金の合計となります。
これに従って、計算は一般的な形式で表すことができます。


結果として得られる式は加重算術平均と呼ばれます。
処理の結果、統計資料は離散分布系列の形式だけでなく、閉じた間隔または開いた間隔を持つ間隔変動系列の形式でも提示できます。
グループ化されたデータの平均は、加重算術平均の式を使用して計算されます。
経済統計の実践では、グループ平均または母集団の個々の部分の平均 (部分平均) を使用して平均を計算する必要がある場合があります。 このような場合、グループ平均または個人平均がオプション (x) として採用され、それに基づいて全体の平均が通常の加重算術平均として計算されます。
算術平均の基本特性 .
算術平均にはいくつかの特性があります。
1. 算術平均の値は、特性 x の各値の頻度を n 倍増減しても変化しません。
すべての周波数を任意の数で除算または乗算しても、平均値は変わりません。
2. 特性の個々の値の共通乗数は、平均の符号を超えて取得される場合があります。

3. 2 つ以上の量の合計 (差) の平均は、それらの平均の合計 (差) に等しい。

4. x = c の場合、c は定数値です。  .
.
5. 算術平均 x からの属性 X の値の偏差の合計はゼロに等しくなります。

調和平均。
統計では、算術平均とともに、属性の逆数値の算術平均の逆数である調和平均が使用されます。 算術平均と同様に、単純で重み付けすることができます。
変動系列の特性は、平均とともに最頻値と中央値です。
ファッション - これは、研究対象の母集団で最も頻繁に繰り返される特性 (バリアント) の値です。 離散分布系列の場合、最頻値は最高頻度のバリアントの値になります。
等間隔の間隔分布系列の場合、最頻値は次の式で決定されます。
どこ  - モードを含む間隔の初期値。
- モードを含む間隔の初期値。
 - モーダル間隔の値。
- モーダル間隔の値。
 - モーダル間隔の頻度;
- モーダル間隔の頻度;
 - モーダルインターバルに先行するインターバルの頻度。
- モーダルインターバルに先行するインターバルの頻度。
 - モーダルな間隔に続く間隔の頻度。
- モーダルな間隔に続く間隔の頻度。
中央値 ・バリエーションシリーズの中間に位置するオプションです。 分布系列が離散的であり、 奇数メンバーの場合、中央値は順序付けされた系列の中央に位置するオプションになります (順序付けされた系列とは、人口単位を昇順または降順に並べたものです)。
ほとんどの場合、データはある中心点の周囲に集中しています。 したがって、任意のデータセットを説明するには、平均値を示すだけで十分です。 分布の平均値を推定するために使用される 3 つの数値特性 (算術平均、中央値、最頻値) を順番に考えてみましょう。
平均
算術平均 (単に平均と呼ばれることも多い) は、分布の平均の最も一般的な推定値です。 観測されたすべての数値の合計をその数で割った結果です。 数値からなるサンプルの場合 X 1、X 2、…、Xn、標本平均(で示される) ) に等しい = (X 1 + X 2 + … + Xn) / n, または
ここで標本平均は、 n- サンプルサイズ、 バツ私 – i 番目の要素サンプル。
または形式でメモをダウンロード、形式で例をダウンロード
15 個の非常に高リスクの投資信託の 5 年間の平均年間リターンの算術平均を計算してみます (図 1)。

米。 1. 15 の非常にハイリスクな投資信託の平均年間リターン
サンプル平均は次のように計算されます。

これは、特に銀行や信用組合の預金者が同じ期間に得た 3 ~ 4% のリターンと比較すると、優れたリターンです。 リターンを並べ替えると、8 つのファンドのリターンが平均を上回り、7 つのファンドが平均を下回っていることが簡単にわかります。 算術平均は均衡点として機能するため、収益の低いファンドと収益の高いファンドのバランスがとれます。 サンプルのすべての要素が平均の計算に関与します。 分布平均の他の推定値にはこの特性はありません。
算術平均はいつ計算する必要がありますか?算術平均はサンプル内のすべての要素に依存するため、極値の存在は結果に大きな影響を与えます。 このような状況では、算術平均によって数値データの意味が歪められる可能性があります。 したがって、極値を含むデータセットを記述する場合は、中央値または算術平均と中央値を示す必要があります。 たとえば、RS Emerging Growth ファンドのリターンをサンプルから除外すると、14 ファンドのリターンのサンプル平均は 5.19% とほぼ 1% 減少します。
中央値
中央値は、順序付けられた数値配列の中央の値を表します。 配列に繰り返しの数値が含まれていない場合、その要素の半分は中央値より小さくなり、半分は中央値より大きくなります。 サンプルに極値が含まれている場合は、算術平均ではなく中央値を使用して平均を推定することをお勧めします。 サンプルの中央値を計算するには、まずサンプルを順序付けする必要があります。
この式は曖昧です。 その結果は、数値が偶数か奇数かによって異なります n:
- サンプルに奇数の要素が含まれている場合、中央値は次のようになります。 (n+1)/2- 番目の要素。
- サンプルに偶数の要素が含まれている場合、中央値はサンプルの中央の 2 つの要素の間にあり、これら 2 つの要素に対して計算された算術平均に等しくなります。
15 個の非常にリスクの高い投資信託のリターンを含むサンプルの中央値を計算するには、まず生データを並べ替える必要があります (図 2)。 この場合、中央値はサンプルの中央の要素の数と反対になります。 この例では No.8 です。 Excel には、順序なし配列でも機能する特別な関数 =MEDIAN() があります。

米。 2. 中央値 15 ファンド
したがって、中央値は 6.5 になります。 これは、非常に高リスクのファンドの半分のリターンは 6.5 を超えず、残りの半分のリターンはそれを超えることを意味します。 中央値 6.5 は平均値 6.08 よりもそれほど大きくないことに注意してください。
RS Emerging Growth ファンドのリターンをサンプルから取り除くと、残りの 14 ファンドの中央値は 6.2% に減少します。つまり、算術平均ほど顕著ではありません (図 3)。

米。 3. 中央値 14 ファンド
ファッション
この用語は、1894 年にピアソンによって最初に造られました。ファッションとは、サンプル内で最も頻繁に出現する (最もファッショナブルな) 数字です。 たとえば、信号機に対するドライバーの典型的な反応が停止する様子は、ファッションによってよく説明されています。 ファッションを利用する典型的な例は、靴のサイズや壁紙の色の選択です。 分布に複数のモードがある場合、それは多峰性または多峰性 (2 つ以上の「ピーク」がある) であると言われます。 分布の多峰性により、研究対象の変数の性質に関する重要な情報が得られます。 たとえば、社会学的調査において、変数が何かに対する好みや態度を表す場合、多峰性とは、いくつかの異なる要素が存在することを意味する場合があります。 さまざまな意見。 多峰性は、サンプルが均一ではなく、観測値が 2 つ以上の「重複する」分布によって生成される可能性があることを示す指標としても機能します。 算術平均とは異なり、外れ値はモードに影響を与えません。 投資信託の平均年間収益など、連続的に分布する確率変数の場合、最頻値がまったく存在しない (または意味をなさない) 場合があります。 これらのインジケーターは非常に異なる値を取る可能性があるため、値が繰り返されることは非常にまれです。
四分位数
四分位数は、大規模な数値サンプルの特性を説明する際にデータの分布を評価するために最もよく使用される指標です。 中央値は順序付けされた配列を半分に分割します (配列の要素の 50% が中央値より小さく、50% が中央値より大きい) が、四分位は順序付けされたデータ セットを 4 つの部分に分割します。 Q 1、中央値、および Q 3 の値は、それぞれ 25、50、および 75 パーセンタイルです。 第 1 四分位 Q 1 は、サンプルを 2 つの部分に分割する数値です。要素の 25% は第 1 四分位より小さく、75% は第 1 四分位より大きくなります。
第 3 四分位 Q 3 もサンプルを 2 つの部分に分割する数値です。要素の 75% は第 3 四分位より小さく、25% は第 3 四分位より大きくなります。
2007 より前のバージョンの Excel で四分位を計算するには、=QUARTILE(array,part) 関数を使用します。 Excel 2010 以降、次の 2 つの関数が使用されます。
- =QUARTILE.ON(配列,部分)
- =QUARTILE.EXC(配列,部分)
これら 2 つの関数はほとんど何も与えません さまざまな意味(図4)。 たとえば、15 の非常に高リスクの投資信託の年間平均リターンを含むサンプルの四分位を計算する場合、QUARTILE.IN と QUARTILE.EX ではそれぞれ Q 1 = 1.8 または –0.7 となります。 ちなみに、先ほど使用したQUARTILE関数は、 現代的な機能四分位数を含む 上記の式を使用して Excel で四分位数を計算する場合、データ配列を順序付ける必要はありません。

米。 4. Excel での四分位数の計算
もう一度強調しましょう。 Excel は単変量の四分位数を計算できます 個別シリーズ、確率変数の値が含まれます。 頻度ベースの分布の四分位数の計算については、以下のセクションで説明します。
幾何平均
算術平均とは異なり、幾何平均を使用すると、時間の経過に伴う変数の変化の程度を推定できます。 幾何平均は根です n仕事からの学位 n数量 (Excel では =SRGEOM 関数が使用されます):
G= (X 1 * X 2 * … * X n) 1/n
同様のパラメータは平均的です 幾何学的な意味収益率は次の式で決まります。
G = [(1 + R 1) * (1 + R 2) * … * (1 + R n)] 1/n – 1、
どこ リ– 利益率 私番目の期間。
たとえば、初期投資が 100,000 ドルであるとします。1 年目の終わりまでに 50,000 ドルに下がり、2 年目の終わりまでに最初のレベルの 100,000 ドルに回復します。2 年にわたるこの投資の収益率は、初期資金と最終資金額が等しいため、-year 期間は 0 に等しくなります。 ただし、初年度の収益率 R 1 = (50,000 – 100,000) / 100,000 = –0.5 であるため、年収益率の算術平均は = (-0.5 + 1) / 2 = 0.25 または 25% となります。 2 番目では、R 2 = (100,000 – 50,000) / 50,000 = 1 となります。同時に、2 年間の利益率の幾何平均値は次のようになります。 G = [(1–0.5) * (1+ 1 )] 1/2 – 1 = ½ – 1 = 1 – 1 = 0. したがって、幾何平均は、2 年間の投資額の変化 (より正確には、変化がないこと) をより正確に反映します。算術平均。
興味深い事実。まず、幾何平均は常に同じ数値の算術平均よりも小さくなります。 ただし、取り出した数値がすべて等しい場合を除きます。 第二に、特性を考慮した上で、 直角三角形, 平均が幾何学的と呼ばれる理由が理解できます。 直角三角形の斜辺まで下げた高さは、脚の斜辺への投影間の平均比例であり、各脚は斜辺とその斜辺への投影間の平均比例です (図 5)。 これは、2 つの (長さ) セグメントの幾何平均を作成する幾何学的な方法を提供します。これら 2 つのセグメントの合計を直径として円を作成し、その接続点から円との交点までの高さを復元する必要があります。希望の値が得られます:

米。 5. 幾何平均の幾何学的性質 (図は Wikipedia より)
2番 大切な財産数値データ - 彼らの 変化、データの分散の程度を特徴づけます。 2 つの異なるサンプルは、平均と分散の両方が異なる場合があります。 ただし、図に示すように、 図6および図7に示されるように、2つのサンプルは、変動は同じであるが平均値が異なる場合もあり、平均値は同じで変動が完全に異なる場合もある。 図のポリゴンBに相当するデータです。 7 では、ポリゴン A が構築されたデータよりも大幅に変化が少なくなります。

米。 6. 同じ広がりと異なる平均値を持つ 2 つの対称的なベル型分布

米。 7. 平均値が同じで広がりが異なる 2 つの対称的な釣鐘型分布
データ変動の推定値は 5 つあります。
- 範囲、
- 四分位範囲、
- 分散、
- 標準偏差、
- 変動係数。
範囲
範囲は、サンプルの最大要素と最小要素の差です。
範囲 = Xマックス – X分
15 の非常に高リスクの投資信託の平均年間リターンを含むサンプルの範囲は、順序付けされた配列を使用して計算できます (図 4 を参照): 範囲 = 18.5 – (-6.1) = 24.6。 これは、非常に高リスクのファンドの最高と最低の平均年間リターンの差が 24.6% であることを意味します。
範囲は、データの全体的な広がりを測定します。 サンプル範囲はデータ全体の広がりの非常に単純な推定値ですが、最小要素と最大要素の間でデータがどのように分布しているかを正確に考慮していないという弱点があります。 この効果は図ではっきりとわかります。 図8は、同じ範囲を有するサンプルを示す。 スケール B は、サンプルに少なくとも 1 つの極値が含まれている場合、サンプル範囲はデータの広がりの非常に不正確な推定であることを示しています。

米。 8. 同じ範囲の 3 つのサンプルの比較。 三角形はスケールのサポートを象徴し、その位置はサンプル平均に対応します。
四分位範囲
四分位間範囲 (平均) は、サンプルの第 3 四分位数と第 1 四分位数の差です。
四分位範囲 = Q 3 – Q 1
この値により、要素の 50% の散乱を推定することができ、極端な要素の影響を考慮する必要がなくなります。 15 の非常に高リスクの投資信託の平均年間リターンを含むサンプルの四分位範囲は、図のデータを使用して計算できます。 4 (たとえば、QUARTILE.EXC 関数の場合): 四分位範囲 = 9.8 – (-0.7) = 10.5。 9.8 と -0.7 という数字で囲まれた間隔は、多くの場合、中間ハーフと呼ばれます。
Q 1 と Q 3 の値、したがって四分位範囲は、外れ値の存在に依存しないことに注意してください。これは、それらの計算では Q 1 未満またはそれ以上の値が考慮されていないためです。 Q3より。 外れ値の影響を受けない中央値、第 1 四分位数、第 3 四分位数、四分位範囲などの要約指標は、ロバスト指標と呼ばれます。
範囲と四分位範囲はそれぞれサンプルの全体と平均の広がりの推定値を提供しますが、これらの推定値はどちらもデータがどのように分布しているかを正確に考慮していません。 分散と標準偏差にはこの欠点がありません。 これらの指標を使用すると、データが平均値の周りでどの程度変動しているかを評価できます。 サンプルの分散各サンプル要素とサンプル平均の差の二乗から計算された算術平均の近似値です。 サンプル X 1、X 2、... X n の場合、サンプル分散 (記号 S 2 で示される) は次の式で与えられます。

一般に、標本分散は、標本要素と標本平均の差の二乗和を、標本サイズから 1 を引いた値で割ったものです。

どこ - 算術平均、 n- サンプルサイズ、 Xi - 私番目の選択要素 バツ。 Excel バージョン 2007 より前のバージョンでは、標本分散の計算に =VARIN() 関数が使用されていましたが、バージョン 2010 以降では =VARIAN() 関数が使用されています。
データの拡散に関する最も実用的で広く受け入れられている推定値は次のとおりです。 サンプル標準偏差。 この指標は記号 S で示され、次と等しくなります。 平方根サンプル分散から:

Excel バージョン 2007 より前のバージョンでは、標準標本偏差の計算に関数 =STDEV.() が使用されていましたが、バージョン 2010 以降は関数 =STDEV.V() が使用されています。 これらの関数を計算するには、データ配列が順序付けされていない場合があります。
標本分散も標本標準偏差も負になることはできません。 指標 S 2 および S がゼロになり得る唯一の状況は、サンプルのすべての要素が互いに等しい場合です。 このまったくありそうもないケースでは、範囲と四分位範囲もゼロになります。
数値データは本質的に可変です。 どの変数でも多くの値を取ることができます さまざまな意味。 たとえば、さまざまな投資信託には、 さまざまな指標収益性と損失。 数値データにはばらつきがあるため、本質的に要約である平均の推定値だけでなく、データの広がりを特徴付ける分散の推定値も研究することが非常に重要です。
分散と標準偏差を使用すると、平均値付近のデータの広がりを評価できます。つまり、平均より小さいサンプル要素がいくつあるか、大きいサンプル要素がいくつあるかを判断できます。 分散にはいくつかの貴重な数学的特性があります。 ただし、その値は平方パーセント、平方ドル、平方インチなどの測定単位の 2 乗です。 したがって、分散の自然な尺度は標準偏差であり、これは所得パーセンテージ、ドル、またはインチの一般的な単位で表されます。
標準偏差を使用すると、平均値付近のサンプル要素の変動量を推定できます。 ほとんどすべての状況で、観測値の大部分は平均値からプラスまたはマイナス 1 標準偏差の範囲内にあります。 したがって、サンプル要素の算術平均と標準サンプル偏差がわかれば、データの大部分が属する区間を決定することができます。
15 の非常に高リスクの投資信託のリターンの標準偏差は 6.6 です (図 9)。 これは、ファンドの大部分の収益性が平均値との差が 6.6% 以内であることを意味します (つまり、収益性は からの範囲で変動します)。 –S= 6.2 – 6.6 = –0.4 ~ +S= 12.8)。 実際、ファンドの 5 年間の平均年間リターンは 53.3% (15 個中 8 個) であり、この範囲内にあります。

米。 9. サンプルの標準偏差
二乗差を合計する場合、平均から遠いサンプル項目は、平均に近い項目よりも重み付けされることに注意してください。 この特性が、分布の平均を推定するために算術平均が最もよく使用される主な理由です。
変動係数
以前の散布推定値とは異なり、変動係数は次のようになります。 相対評価。 元のデータの単位ではなく、常にパーセンテージとして測定されます。 シンボル CV で示される変動係数は、平均値付近のデータの分散を測定します。 変動係数は、標準偏差を算術平均で割って 100% を掛けたものに等しくなります。

どこ S- 標準サンプル偏差、 - サンプルの平均。
変動係数を使用すると、要素が異なる測定単位で表される 2 つのサンプルを比較できます。 たとえば、郵便配達サービスのマネージャーは、トラックの保有車両を更新する予定です。 荷物を積み込む際には、各荷物の重量 (ポンド単位) と体積 (立方フィート単位) という 2 つの制限を考慮する必要があります。 200 個の袋を含むサンプルで、平均重量が 26.0 ポンド、重量の標準偏差が 3.9 ポンド、平均袋容積が 8.8 立方フィート、容積の標準偏差が 2.2 立方フィートであると仮定します。 荷物の重量と体積の変動を比較するにはどうすればよいですか?
重量と体積の測定単位は互いに異なるため、管理者はこれらの量の相対的な広がりを比較する必要があります。 重量の変動係数は CV W = 3.9 / 26.0 * 100% = 15%、体積の変動係数は CV V = 2.2 / 8.8 * 100% = 25% となります。 したがって、パケットの体積の相対的な変動は、パケットの重さの相対的な変動よりもはるかに大きくなります。
配布形態
サンプルの 3 番目に重要な特性は、その分布の形状です。 この分布は対称または非対称の場合があります。 分布の形状を記述するには、その平均と中央値を計算する必要があります。 2 つが同じ場合、変数は対称的に分散されていると見なされます。 変数の平均値が中央値より大きい場合、その分布は正の歪度になります (図 10)。 中央値が平均より大きい場合、変数の分布は負に偏っています。 平均値が異常な程度に増加すると、正の歪度が発生します 高い値。 負の歪度は、平均が異常に小さい値に減少した場合に発生します。 変数は、どちらの方向にも極端な値を取らない場合、対称的に分布しているため、変数の大きい値と小さい値は互いに打ち消し合います。

米。 10. 3種類の分布
スケール A に示されているデータは負に歪んでいます。 この図でわかるように、 長い尾異常に小さい値の存在によって引き起こされる左のスキュー。 これらの非常に小さな値により、平均値が左にシフトし、中央値よりも小さくなります。 スケール B に示されているデータは対称的に分布しています。 分布の左半分と右半分は、それ自体の鏡像です。 大きい値と小さい値は互いにバランスが取れており、平均と中央値は等しくなります。 スケール B に示されているデータは、プラスに歪んでいます。 この図は、異常に高い値の存在によって引き起こされる長いテールと右への歪みを示しています。 これらもです 大量の平均値を右にシフトすると、中央値よりも大きくなります。
Excel では、アドインを使用して記述統計を取得できます。 分析パッケージ。 メニューを確認する データ → データ分析、開いたウィンドウで行を選択します 記述統計そしてクリックしてください わかりました。 窓の中で 記述統計必ず指定してください 入力間隔(図11)。 元のデータと同じシートに記述統計を表示したい場合は、ラジオ ボタンを選択します。 出力間隔そして、表示された統計の左上隅を配置するセルを指定します (この例では、$C$1)。 データを新規シートに出力したい場合や、 新しい本、適切なスイッチを選択するだけです。 の横にあるボックスにチェックを入れます 概要統計。 必要に応じて、選択することもできます 難易度、k番目に小さいものとk番目に大きい.
デポジットの場合 データエリア内 分析アイコンが表示されない データ分析、最初にアドオンをインストールする必要があります 分析パッケージ(たとえば、を参照)。

米。 11. アドインを使用して計算された、非常に高いレベルのリスクを伴うファンドの 5 年間の平均年間リターンの記述統計 データ分析 Excelプログラム
Excel は、平均、中央値、最頻値、標準偏差、分散、範囲 ( 間隔)、最小値、最大値、サンプル サイズ ( チェック)。 Excel では、標準誤差、尖度、歪度など、私たちにとって初めての統計も計算されます。 標準誤差標準偏差をサンプルサイズの平方根で割ったものに等しい。 非対称分布の対称性からの逸脱を特徴づける関数であり、サンプル要素と平均値の差の 3 乗に依存する関数です。 尖度は、分布の裾と比較した平均付近のデータの相対濃度の尺度であり、サンプル要素と平均の 4 乗の差に依存します。
上で説明した分布の平均、広がり、形状はサンプルから決定される特性です。 ただし、データセットに母集団全体の数値測定値が含まれている場合は、そのパラメータを計算できます。 このようなパラメーターには、母集団の期待値、分散、標準偏差が含まれます。
期待値母集団内のすべての値の合計を母集団のサイズで割ったものに等しい:

どこ µ - 期待値、 バツ私- 私変数の 番目の観測値 バツ, N- 一般人口の量。 Excel では、数学的期待値を計算するために、算術平均と同じ関数 =AVERAGE() が使用されます。
母集団分散一般母集団の要素とマットの要素の差の二乗和に等しい。 期待値を母集団のサイズで割った値:

どこ σ 2– 一般人口の分散。 バージョン 2007 より前の Excel では、バージョン 2010 =VARP() 以降、関数 =VARP() を使用して母集団の分散が計算されます。
母集団標準偏差母集団分散の平方根に等しい:

バージョン 2007 より前の Excel では、バージョン 2010 =STDEV.Y() 以降、母集団の標準偏差を計算するために =STDEV() 関数が使用されます。 母集団の分散と標準偏差の式は、標本分散と標準偏差の計算式とは異なることに注意してください。 計算するとき サンプル統計 S2そして S分数の分母は n – 1、パラメータを計算するとき σ 2そして σ - 一般人口の量 N.
経験則
ほとんどの状況では、観測値の大部分が中央値の周囲に集中し、クラスターを形成します。 歪度が正のデータ セットでは、このクラスターは数学的期待値の左側 (つまり、下) に位置し、歪度が負のデータ セットでは、このクラスターは数学的期待値の右側 (つまり、上) に位置します。 対称的なデータの場合、平均と中央値は同じであり、観測値は平均の周囲に集まり、釣鐘型の分布を形成します。 分布が明確に偏っておらず、データが重心の周囲に集中している場合、ばらつきの推定に使用できる経験則は、データが釣鐘型の分布を持っている場合、観測値の約 68% が範囲内にあるということです。期待値の 1 標準偏差。観測値の約 95% は数学的期待値から 2 標準偏差以内、99.7% の観測値は数学的期待値から 3 標準偏差以内です。
したがって、期待値付近の平均変動の推定値である標準偏差は、観測値がどのように分布しているかを理解し、外れ値を特定するのに役立ちます。 経験則では、釣鐘型分布の場合、20 個のうち 1 個の値だけが数学的期待値と標準偏差 2 を超えて異なります。 したがって、区間外の値は μ±2σ、外れ値と考えることができます。 さらに、1000 個の観測値のうち、標準偏差が 3 倍を超えて数学的期待と異なるのは 3 個だけです。 したがって、区間外の値は μ±3σほとんどの場合、外れ値になります。 偏りが大きい分布や釣鐘型ではない分布の場合は、ビエナマイ・チェビシェフの経験則を適用できます。
100年以上前、数学者のビエナメイとチェビシェフが独立して発見した 有用な特性標準偏差。 彼らは、分布の形状に関係なく、どのようなデータセットでも、次の距離内にある観測値の割合が高いことを発見しました。 k数学的期待値からの標準偏差、それ以上 (1 – 1/ k 2)*100%.
たとえば、次の場合 k= 2 の場合、ビエンネーム-チェビシェフ ルールでは、少なくとも (1 – (1/2) 2) x 100% = 75% の観測値がこの区間内に存在する必要があると規定されています。 μ±2σ。 このルールはどんなものにも当てはまります k、1を超えています。 Bienamay-Chebyshev ルールは非常に一般的で、あらゆるタイプの分布に有効です。 これは、観測値の最小数、つまり数学的期待値までの距離が指定された値を超えないことを指定します。 ただし、分布が釣鐘型の場合、経験則により、期待値付近のデータの集中度がより正確に推定されます。
周波数ベースの分布の記述統計量の計算
元のデータが入手できない場合、頻度分布が唯一の情報源になります。 このような状況では、算術平均、標準偏差、四分位数などの分布の定量的指標の近似値を計算することができます。
サンプルデータが度数分布として表されている場合、各クラス内のすべての値が次のクラスに集中していると仮定することで、算術平均の近似値を計算できます。 中間点クラス:

どこ - サンプル平均、 n- 観測値の数、またはサンプルサイズ、 と- 度数分布内のクラスの数、 mj- 中間点 j 3番目のクラス、 fj- 周波数対応 j- 番目のクラス。
度数分布から標準偏差を計算するには、各クラス内のすべての値がクラスの中間点に集中していると仮定します。

度数に基づいて系列の四分位がどのように決定されるかを理解するには、一人当たりの平均金銭収入によるロシア人口の分布に関する 2013 年のデータに基づいて下位四分位の計算を検討してください (図 12)。

米。 12. ロシアの人口に占める一人当たり月平均現金収入の割合(ルーブル)
間隔変動系列の最初の四分位を計算するには、次の式を使用できます。

ここで、Q1 は最初の四分位の値、xQ1 は最初の四分位を含む間隔の下限です (間隔は最初に 25% を超える累積頻度によって決まります)。 i – 間隔値; Σf – サンプル全体の周波数の合計。 おそらく常に 100% に等しくなります。 SQ1–1 – 下位四分位を含む区間に先行する区間の累積頻度。 fQ1 – 下位四分位を含む区間の周波数。 第 3 四分位の式は、すべての場所で Q1 の代わりに Q3 を使用し、1/4 の代わりに ¾ を使用する必要があるという点で異なります。
この例 (図 12) では、下位四分位は 7000.1 ~ 10,000 の範囲にあり、その累積頻度は 26.4% です。 この間隔の下限は 7000 ルーブル、間隔の値は 3000 ルーブル、下位四分位を含む間隔に先行する間隔の累積頻度は 13.4%、下位四分位を含む間隔の頻度は 13.0% です。 したがって、Q1 = 7000 + 3000 * (1/4 * 100 – 13.4) / 13 = 9677 摩擦となります。
記述統計に関連する落とし穴
この投稿では、平均、広がり、分布を評価するさまざまな統計を使用してデータセットを記述する方法を検討しました。 次のステップはデータの分析と解釈です。 これまではデータの客観的な特性を研究してきましたが、これからは主観的な解釈に移ります。 研究者は、分析対象の選択の誤りと結果の解釈の誤りという 2 つの間違いに直面します。
15 の非常にハイリスクな投資信託のリターンの分析は、非常に公平です。 彼は完全に客観的な結論に導きました。すべての投資信託には異なるリターンがあり、ファンドのリターンのばらつきは -6.1 から 18.5 の範囲であり、平均リターンは 6.08 です。 データ分析の客観性が確保されている 正しい選択分布の合計定量的指標。 データの平均と分散を推定するためのいくつかの方法が検討され、それらの長所と短所が示されました。 客観的かつ公平な分析を提供するために、適切な統計をどのように選択すればよいでしょうか? データ分布がわずかに歪んでいる場合、平均ではなく中央値を選択する必要がありますか? データの広がりをより正確に特徴付ける指標は、標準偏差と範囲のどちらですか? 分布がプラスに偏っていることを指摘すべきでしょうか?
一方、データの解釈は主観的なプロセスです。 さまざまな人同じ結果を解釈しても異なる結論に達します。 誰もが独自の視点を持っています。 ある人は、非常に高いレベルのリスクを伴う 15 のファンドの合計平均年間リターンが良好であると考えており、受け取った収入に非常に満足しています。 これらのファンドのリターンが低すぎると感じる人もいるかもしれません。 したがって、主観性は、誠実さ、中立性、結論の明確さによって補われるべきです。
倫理的問題
データ分析は倫理問題と密接に関係しています。 新聞、ラジオ、テレビ、インターネットによって広められる情報には批判的であるべきです。 時間が経つにつれて、結果だけでなく、研究の目標、主題、客観性に対しても懐疑的になることができるようになります。 英国の有名な政治家ベンジャミン・ディズレーリは、「嘘には3種類ある。嘘、とんでもない嘘、そして統計だ」と最もよく言いました。
注にもあるように、報告書に掲載すべき結果を選択する際には倫理的な問題が生じます。 肯定的なことと、 否定的な結果。 また、報告書や報告書を作成する場合には、その結果を正直、中立かつ客観的に表現する必要があります。 失敗したプレゼンテーションと不正なプレゼンテーションの間には区別が必要です。 これを行うには、話者の意図が何であったかを判断する必要があります。 話者が無知で重要な情報を省略する場合もあれば、意図的に省略する場合もあります (たとえば、算術平均を使用して、明らかに偏ったデータの平均を推定して、望ましい結果を得る場合)。 研究者の視点と一致しない結果を隠蔽することも不誠実です。
Levin et al. Statistics for Managers という本の資料が使用されています。 – M.: ウィリアムズ、2004年。 – p. 178–209
QUARTILE 関数は、さらに他の関数と組み合わせることができます。 以前のバージョンエクセル